




Hamish Ivison
@hamishivi.bsky.social
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
Excited to be back home in Australia (Syd/Melb) for most of April! Email or DM if you want to grab a coffee :)

March 27, 2025 at 4:11 PM
Excited to be back home in Australia (Syd/Melb) for most of April! Email or DM if you want to grab a coffee :)
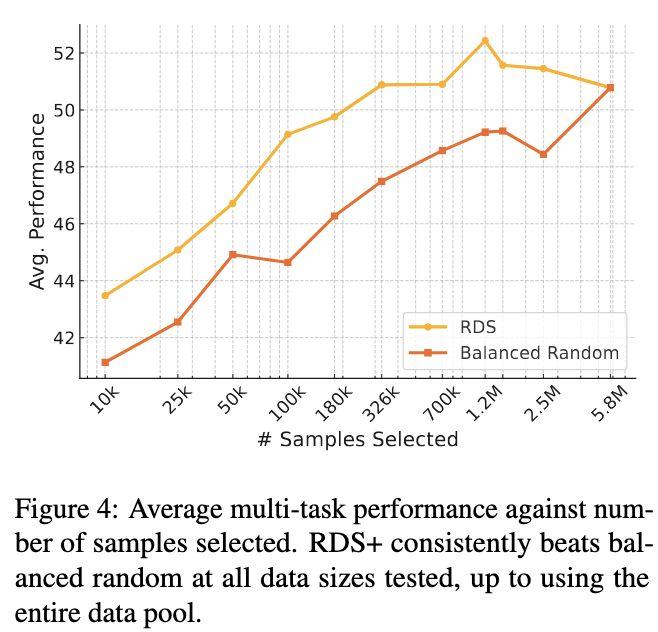
6/8 We further investigate RDS+, selecting up to millions of samples, and comparing it to random selection while taking total compute into account. RDS+ plus beats random selection at all data sizes, and taking compute into account, performs significantly better at larger sizes.
March 4, 2025 at 5:10 PM
6/8 We further investigate RDS+, selecting up to millions of samples, and comparing it to random selection while taking total compute into account. RDS+ plus beats random selection at all data sizes, and taking compute into account, performs significantly better at larger sizes.
5/8 We also investigate how well these methods work when selecting one dataset for multiple downstream tasks. The best performing method, RDS+, outperforms the Tulu 2 mixture. We also see strong results selecting using Arena Hard samples as query points with RDS+.

March 4, 2025 at 5:10 PM
5/8 We also investigate how well these methods work when selecting one dataset for multiple downstream tasks. The best performing method, RDS+, outperforms the Tulu 2 mixture. We also see strong results selecting using Arena Hard samples as query points with RDS+.
3/8 We test a variety of different data selection methods on these pools.
We select 10k samples from a downsampled pool of 200k samples, and then test selecting 10k samples from all 5.8M samples. Surprisingly, many methods drop in performance when the pool size increases!
We select 10k samples from a downsampled pool of 200k samples, and then test selecting 10k samples from all 5.8M samples. Surprisingly, many methods drop in performance when the pool size increases!

March 4, 2025 at 5:10 PM
3/8 We test a variety of different data selection methods on these pools.
We select 10k samples from a downsampled pool of 200k samples, and then test selecting 10k samples from all 5.8M samples. Surprisingly, many methods drop in performance when the pool size increases!
We select 10k samples from a downsampled pool of 200k samples, and then test selecting 10k samples from all 5.8M samples. Surprisingly, many methods drop in performance when the pool size increases!
2/8 We begin by constructing data pools for selection, using Tulu 2/3 as a starting point. These pools contain over 4 million samples – all data initially considered for the Tulu models. We then perform selection and evaluation across seven different downstream tasks.

March 4, 2025 at 5:10 PM
2/8 We begin by constructing data pools for selection, using Tulu 2/3 as a starting point. These pools contain over 4 million samples – all data initially considered for the Tulu models. We then perform selection and evaluation across seven different downstream tasks.
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)

March 4, 2025 at 5:10 PM
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
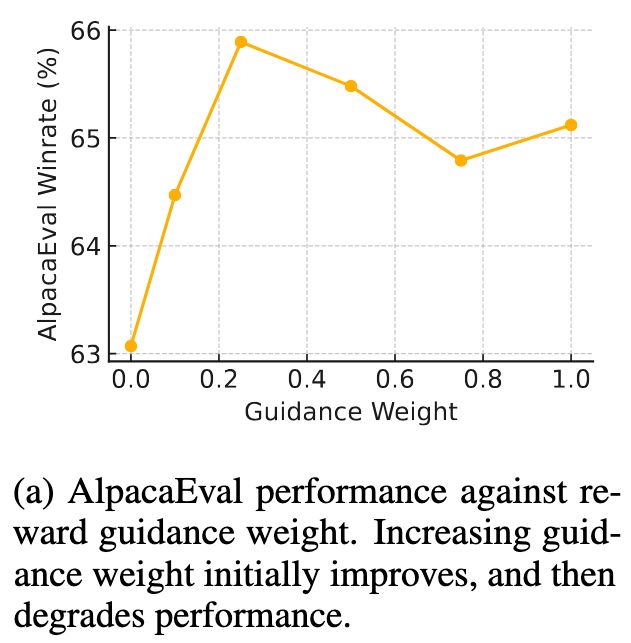
(6/8) Second, using classifier guidance with an off-the-shelf reward model (which we call reward guidance). Increasing the weight of the RM guidance improves AlpacaEval winrate. If you set the guidance really high, you get high-reward but nonsensical generations (reward-hacking!).
February 20, 2025 at 6:08 PM
(6/8) Second, using classifier guidance with an off-the-shelf reward model (which we call reward guidance). Increasing the weight of the RM guidance improves AlpacaEval winrate. If you set the guidance really high, you get high-reward but nonsensical generations (reward-hacking!).
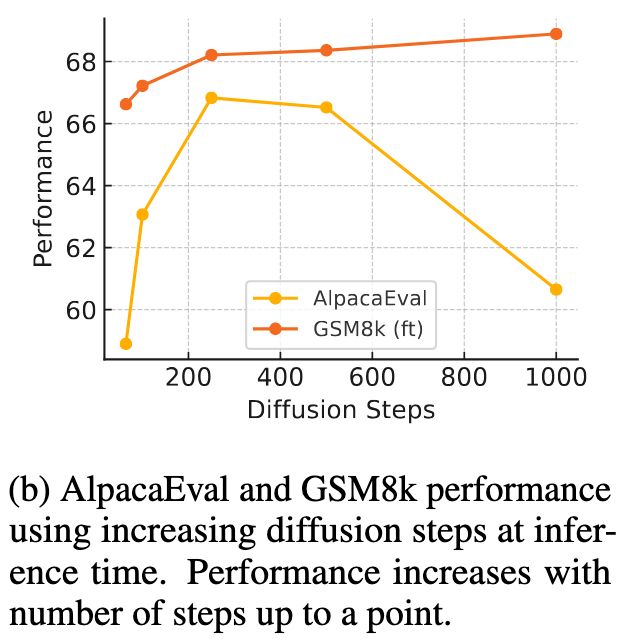
(5/8) First, as we increase diffusion steps, we see GSM8k scores improve consistently! We also see AlpacaEval improve, and then reduce, as the model generations also get more repetitive.
February 20, 2025 at 6:08 PM
(5/8) First, as we increase diffusion steps, we see GSM8k scores improve consistently! We also see AlpacaEval improve, and then reduce, as the model generations also get more repetitive.
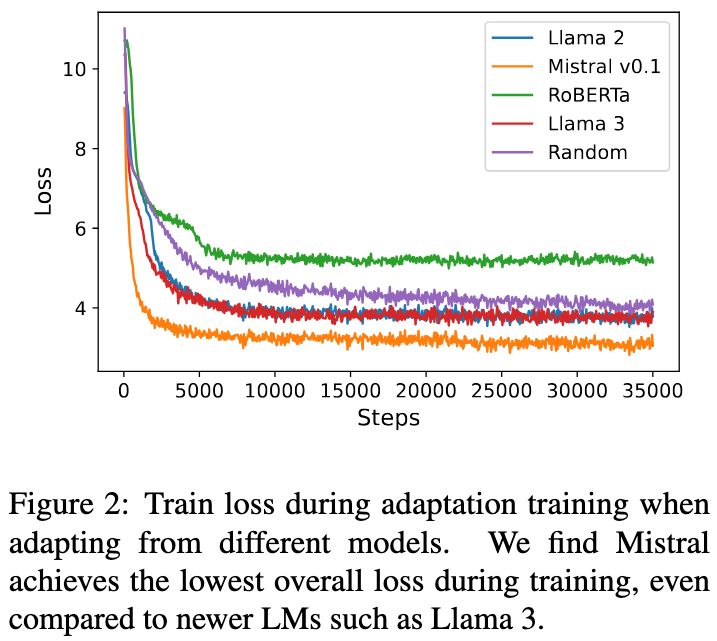
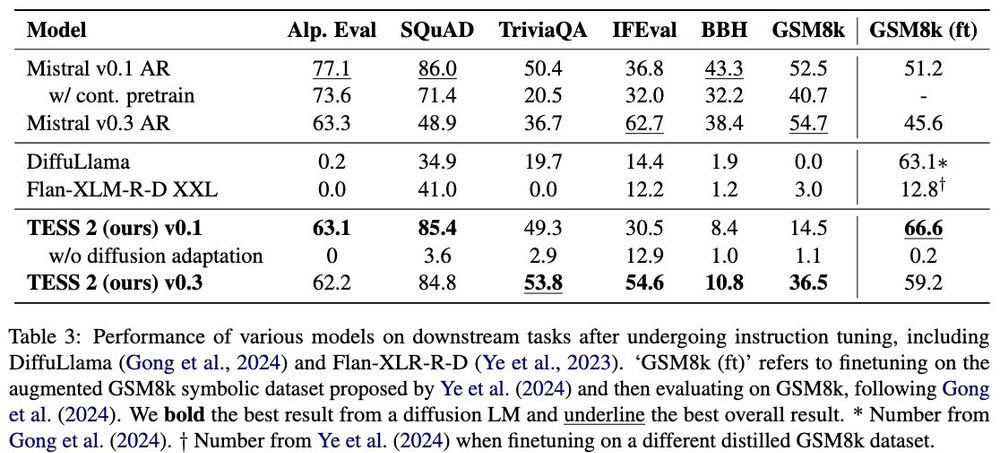
(3/8) We train TESS 2 by (1) performing 200k steps of diffusion adaptation training, (2) instruction tuning on Tulu. We found that adapting Mistral models (v0.1/0.3) performed much better than Llama!
February 20, 2025 at 6:08 PM
(3/8) We train TESS 2 by (1) performing 200k steps of diffusion adaptation training, (2) instruction tuning on Tulu. We found that adapting Mistral models (v0.1/0.3) performed much better than Llama!
(2/8) We find that TESS 2 performs well in QA, but lags in reasoning-heavy tasks (GSM8k, BBH). However, when we train on GSM8k-specific data, we beat AR models!
It may be that instruction-tuning mixtures need to be adjusted for diffusion models (we just used Tulu 2/3 off the shelf).
It may be that instruction-tuning mixtures need to be adjusted for diffusion models (we just used Tulu 2/3 off the shelf).
February 20, 2025 at 6:08 PM
(2/8) We find that TESS 2 performs well in QA, but lags in reasoning-heavy tasks (GSM8k, BBH). However, when we train on GSM8k-specific data, we beat AR models!
It may be that instruction-tuning mixtures need to be adjusted for diffusion models (we just used Tulu 2/3 off the shelf).
It may be that instruction-tuning mixtures need to be adjusted for diffusion models (we just used Tulu 2/3 off the shelf).
(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
February 20, 2025 at 6:08 PM
(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
This was a fun side effort with lots of help from everyone on the Tulu 3 team. Special shoutouts to @vwxyzjn.bsky.social (who did a lot on the training+infra side) and @ljvmiranda.bsky.social (who helped with DPO data generation). I leave you with the *unofficial* name for this release:

January 30, 2025 at 3:38 PM
This was a fun side effort with lots of help from everyone on the Tulu 3 team. Special shoutouts to @vwxyzjn.bsky.social (who did a lot on the training+infra side) and @ljvmiranda.bsky.social (who helped with DPO data generation). I leave you with the *unofficial* name for this release:
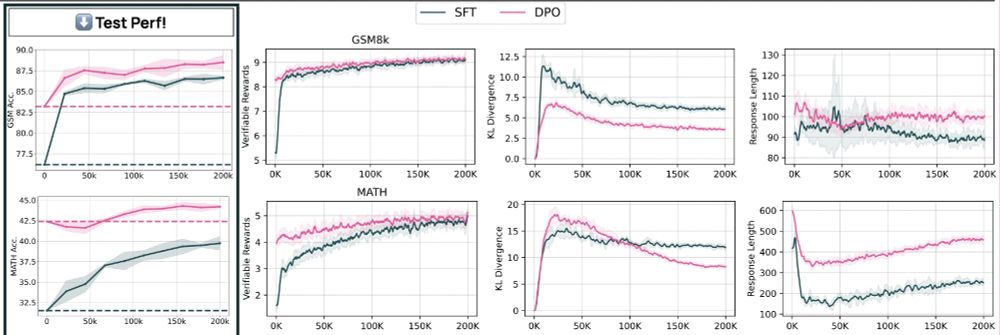
This is more or less the exact Tulu 3 recipe, with one exception: We just did RLVR on the MATH train set. This almost instantly gave > 5 point gains, as you can see in the RL curves below.
(multiply y-axis by 10 to get MATH test perf)
(multiply y-axis by 10 to get MATH test perf)

January 30, 2025 at 3:38 PM
This is more or less the exact Tulu 3 recipe, with one exception: We just did RLVR on the MATH train set. This almost instantly gave > 5 point gains, as you can see in the RL curves below.
(multiply y-axis by 10 to get MATH test perf)
(multiply y-axis by 10 to get MATH test perf)
li'l holiday project from the tulu team :)
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!

January 30, 2025 at 3:38 PM
li'l holiday project from the tulu team :)
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Seems like a good time to share this: a poster from a class project diving a little more into Tulu 3's RLVR. Deepseek R1 release today shows that scaling this sort of approach up can be very very effective!

January 20, 2025 at 7:04 PM
Seems like a good time to share this: a poster from a class project diving a little more into Tulu 3's RLVR. Deepseek R1 release today shows that scaling this sort of approach up can be very very effective!
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124

January 8, 2025 at 5:47 PM
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
December 6, 2024 at 8:24 PM
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):

December 2, 2024 at 6:53 PM
Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):
I know it doesn't know much if anything about me but this was pretty surprisingly good!

November 30, 2024 at 5:50 AM
I know it doesn't know much if anything about me but this was pretty surprisingly good!
Watching RL training curves is too addictive... begging my models to yap more and get more reward 🙏

November 29, 2024 at 7:35 AM
Watching RL training curves is too addictive... begging my models to yap more and get more reward 🙏
being unable to do ox math is pretty inexcusable... core concern for olmo 3.

November 28, 2024 at 5:31 AM
being unable to do ox math is pretty inexcusable... core concern for olmo 3.
there is also PNW-tulu

November 21, 2024 at 5:51 PM
there is also PNW-tulu
If you love instagram reels, I made a Tulu 3 video for you :)
November 21, 2024 at 5:47 PM
If you love instagram reels, I made a Tulu 3 video for you :)
It's just a chill release.

November 21, 2024 at 5:46 PM
It's just a chill release.