



Natasha Jaques
@natashajaques.bsky.social
Assistant Professor at UW and Staff Research Scientist at Google DeepMind. Social Reinforcement Learning in multi-agent and human-AI interactions. PhD from MIT. Check out https://socialrl.cs.washington.edu/ and https://natashajaques.ai/.
Pinned
Natasha Jaques
@natashajaques.bsky.social
· Dec 11
SocialRL Lab
We are the Social Reinforcement Learning Lab at the University of Washington.
socialrl.cs.washington.edu
Even though the Social RL lab only got started ~1 year ago, I’m super excited to announce that we have 10 people from the lab presenting their work at #NeurIPS2024. Delighted to officially introduce our lab: socialrl.cs.washington.edu! Thread with all our NeurIPS work below 👇
Instead of behavior cloning, what if you asked an LLM to write code to describe how an agent was acting, and used this to predict their future behavior?
Our new paper "Modeling Others' Minds as Code" shows this outperforms BC by 2x, and reaches human-level performance in predicting human behavior.
Our new paper "Modeling Others' Minds as Code" shows this outperforms BC by 2x, and reaches human-level performance in predicting human behavior.
Forget modeling every belief and goal! What if we represented people as following simple scripts instead (i.e "cross the crosswalk")?
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...

October 3, 2025 at 7:01 PM
Instead of behavior cloning, what if you asked an LLM to write code to describe how an agent was acting, and used this to predict their future behavior?
Our new paper "Modeling Others' Minds as Code" shows this outperforms BC by 2x, and reaches human-level performance in predicting human behavior.
Our new paper "Modeling Others' Minds as Code" shows this outperforms BC by 2x, and reaches human-level performance in predicting human behavior.
My husband presenting his work on caregiving 😍

lol this may be the most cogsci cogsci slide I've ever seen, from @maxkw.bsky.social
"before I got married I had six theories about raising children, now I have six kids and no theories"......but here's another theory #cogsci2025
"before I got married I had six theories about raising children, now I have six kids and no theories"......but here's another theory #cogsci2025

August 1, 2025 at 12:03 AM
My husband presenting his work on caregiving 😍
Excited to release our latest paper on a new multi-turn RL objective for training LLMs to *learn how to learn* to adapt to the user. This enables it to adapt and personalize to novel users, whereas the multi-turn RLHF baseline fails to generalize effectively to new users.

Personalization methods for LLMs often rely on extensive user history. We introduce Curiosity-driven User-modeling Reward as Intrinsic Objective (CURIO) to encourage actively learning about the user within multi-turn dialogs.
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...
📜 arxiv.org/abs/2504.03206
🌎 sites.google.com/cs.washingto...
July 8, 2025 at 11:05 PM
Excited to release our latest paper on a new multi-turn RL objective for training LLMs to *learn how to learn* to adapt to the user. This enables it to adapt and personalize to novel users, whereas the multi-turn RLHF baseline fails to generalize effectively to new users.
In our latest paper, we discovered a surprising result: training LLMs with self-play reinforcement learning on zero-sum games (like poker) significantly improves performance on math and reasoning benchmarks, zero-shot. Whaaat? How does this work?

We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
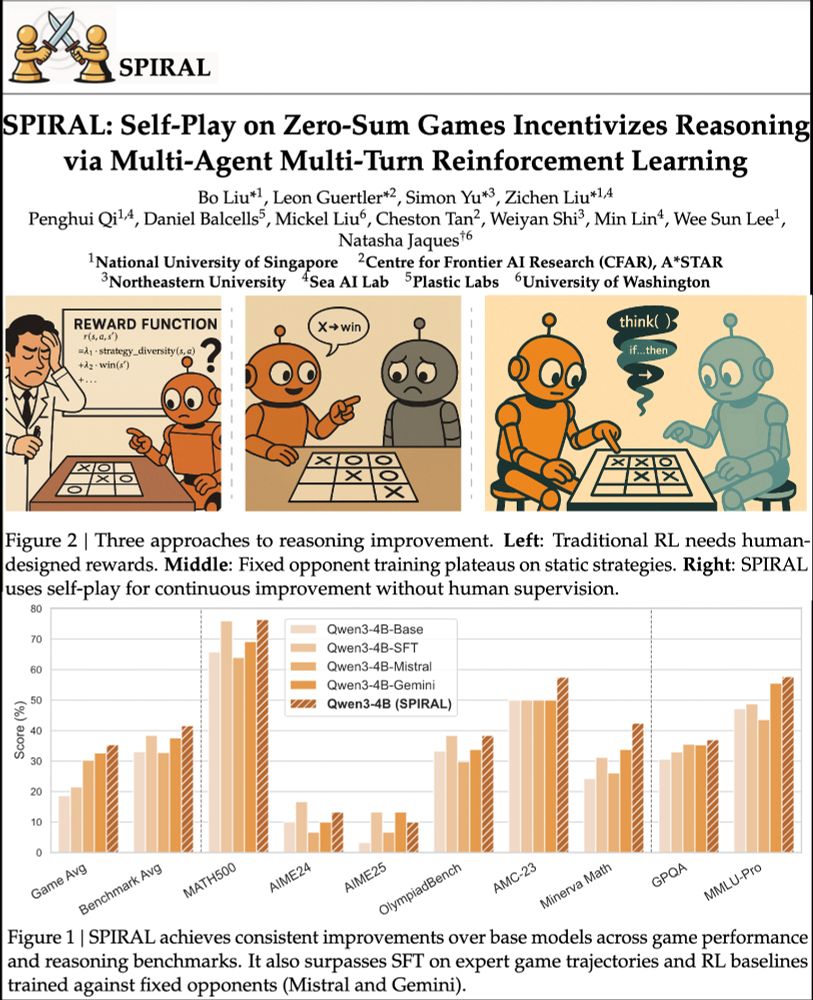
July 1, 2025 at 8:23 PM
In our latest paper, we discovered a surprising result: training LLMs with self-play reinforcement learning on zero-sum games (like poker) significantly improves performance on math and reasoning benchmarks, zero-shot. Whaaat? How does this work?
Just posted a talk I gave about this work! youtu.be/mxWJ9k2XKbk
June 12, 2025 at 5:08 PM
Just posted a talk I gave about this work! youtu.be/mxWJ9k2XKbk
Reposted by Natasha Jaques
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.

🤔Conventional LM safety alignment is reactive: find vulnerabilities→patch→repeat
🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵
🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵

June 12, 2025 at 5:07 PM
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
🤔Conventional LM safety alignment is reactive: find vulnerabilities→patch→repeat
🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵
🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵
June 12, 2025 at 5:07 PM
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
Reposted by Natasha Jaques

Oral @icmlconf.bsky.social !!! Can't wait to share our work and hear the community's thoughts on it, should be a fun talk!
Can't thank my collaborators enough: @cogscikid.bsky.social y.social @liangyanchenggg @simon-du.bsky.social @maxkw.bsky.social @natashajaques.bsky.social
Can't thank my collaborators enough: @cogscikid.bsky.social y.social @liangyanchenggg @simon-du.bsky.social @maxkw.bsky.social @natashajaques.bsky.social
Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
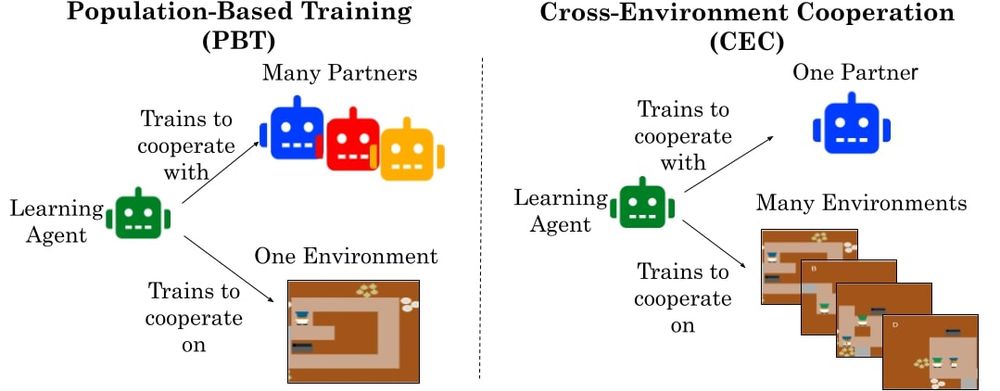
June 9, 2025 at 4:32 PM
Oral @icmlconf.bsky.social !!! Can't wait to share our work and hear the community's thoughts on it, should be a fun talk!
Can't thank my collaborators enough: @cogscikid.bsky.social y.social @liangyanchenggg @simon-du.bsky.social @maxkw.bsky.social @natashajaques.bsky.social
Can't thank my collaborators enough: @cogscikid.bsky.social y.social @liangyanchenggg @simon-du.bsky.social @maxkw.bsky.social @natashajaques.bsky.social
Reposted by Natasha Jaques

At @rldmdublin2025.bsky.social this week? Check out our social learning workshop from @amritalamba.bsky.social and I tomorrow! Inc. talks from @natashajaques.bsky.social, @nitalon.bsky.social, @carocharp.bsky.social, @kartikchandra.bsky.social & more!
Full schedule: sites.google.com/view/rldm202...
Full schedule: sites.google.com/view/rldm202...
RLDM2025SocInfWorkshop
// RLDM 2025 Workshop \\
Reinforcement learning as a model of social behaviour and inference: progress and pitfalls
12.06.2025 // 9am-1pm
sites.google.com
June 11, 2025 at 6:49 AM
At @rldmdublin2025.bsky.social this week? Check out our social learning workshop from @amritalamba.bsky.social and I tomorrow! Inc. talks from @natashajaques.bsky.social, @nitalon.bsky.social, @carocharp.bsky.social, @kartikchandra.bsky.social & more!
Full schedule: sites.google.com/view/rldm202...
Full schedule: sites.google.com/view/rldm202...
Reposted by Natasha Jaques

1/4 Join us and the Autotelic Interaction Research (AIR) group @aalto.fi / Finland to work on Computational Social Intrinsic Motivation (SIM) as PhD (4y) or postdoc (2y). Job ad w project description and application instructions: bit.ly/4jyNLGv. We're looking forward to learning about you!
Doctoral Researcher and Postdoc positions to work on Computational Social Intrinsic Motivation (SIM) | Aalto University
The Autotelic Interaction Research (AIR) group at the Dept. of Computer Science, Aalto University, Finland is looking for 1 Doctoral Researcher (2+2 years) and 1 Postdoc (2 years) to work on Computational Social Intrinsic Motivation (SIM)
bit.ly
June 3, 2025 at 12:13 PM
1/4 Join us and the Autotelic Interaction Research (AIR) group @aalto.fi / Finland to work on Computational Social Intrinsic Motivation (SIM) as PhD (4y) or postdoc (2y). Job ad w project description and application instructions: bit.ly/4jyNLGv. We're looking forward to learning about you!
Human-AI cooperation is important, but existing work trains on the same 5 Overcooked layouts, creating brittle strategies.
Instead, we find that training on billions of procedurally generated tasks trains agents to learn general cooperative norms that transfer to humans... like avoiding collision
Instead, we find that training on billions of procedurally generated tasks trains agents to learn general cooperative norms that transfer to humans... like avoiding collision
Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
April 19, 2025 at 5:02 AM
Human-AI cooperation is important, but existing work trains on the same 5 Overcooked layouts, creating brittle strategies.
Instead, we find that training on billions of procedurally generated tasks trains agents to learn general cooperative norms that transfer to humans... like avoiding collision
Instead, we find that training on billions of procedurally generated tasks trains agents to learn general cooperative norms that transfer to humans... like avoiding collision
Reposted by Natasha Jaques
Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
April 19, 2025 at 12:06 AM
Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
Got a weird combination of mail today.

April 12, 2025 at 5:04 PM
Got a weird combination of mail today.
Recorded a recent "talk" / rant about RL fine-tuning of LLMs for a guest lecture in Stanford CSE234: youtube.com/watch?v=NTSY.... Covers some of my lab's recent work on personalized RLHF, as well as some mild Schmidhubering about my own early contributions to this space

Reinforcement Learning (RL) for LLMs
YouTube video by Natasha Jaques
youtube.com
March 27, 2025 at 9:32 PM
Recorded a recent "talk" / rant about RL fine-tuning of LLMs for a guest lecture in Stanford CSE234: youtube.com/watch?v=NTSY.... Covers some of my lab's recent work on personalized RLHF, as well as some mild Schmidhubering about my own early contributions to this space
Reposted by Natasha Jaques

next Canadian government should think of boosting research funding up here and trying to grab as many American postdocs and researchers as possible
March 12, 2025 at 1:08 PM
next Canadian government should think of boosting research funding up here and trying to grab as many American postdocs and researchers as possible
Reposted by Natasha Jaques

AI has shown great potential in boosting efficiency. But can it help human society make better decisions as a whole? 🤔 In this project, using MARL, we explore this by studying the impact of an ESG disclosure mandate—a highly controversial policy. (1/6)

In our latest work, we introduce InvestESG, a lightweight, GPU-efficient MARL environment, designed to study incentives surrounding corporate climate mitigation and climate risks. Check out the project website: sites.google.com/view/investe...

InvestESG
TLDR: We introduce InvestESG, a lightweight, GPU-efficient MARL environment simulating company and investor responses to ESG disclosure mandates, with companies and investors modeled as two types of s...
sites.google.com
February 13, 2025 at 6:24 AM
AI has shown great potential in boosting efficiency. But can it help human society make better decisions as a whole? 🤔 In this project, using MARL, we explore this by studying the impact of an ESG disclosure mandate—a highly controversial policy. (1/6)
Our latest work uses multi-agent reinforcement learning to model corporate investment in climate change mitigation as a social dilemma. We create a new benchmark, and show that corporations are greedily motivated to pollute without mitigating their emissions, but if all companies defect...
In our latest work, we introduce InvestESG, a lightweight, GPU-efficient MARL environment, designed to study incentives surrounding corporate climate mitigation and climate risks. Check out the project website: sites.google.com/view/investe...
InvestESG
TLDR: We introduce InvestESG, a lightweight, GPU-efficient MARL environment simulating company and investor responses to ESG disclosure mandates, with companies and investors modeled as two types of s...
sites.google.com
February 13, 2025 at 6:38 AM
Our latest work uses multi-agent reinforcement learning to model corporate investment in climate change mitigation as a social dilemma. We create a new benchmark, and show that corporations are greedily motivated to pollute without mitigating their emissions, but if all companies defect...
The paper I spoke about at the #NeurIPS2024 ML for Systems workshop is now on arxiv arxiv.org/abs/2412.15573! We use multi-agent RL to solve a classic combinatorial optimization problem (the Sequential Assignment Problem), by combining MARL with a classical polynomial time assignment algorithm. 1/3

January 2, 2025 at 10:32 PM
The paper I spoke about at the #NeurIPS2024 ML for Systems workshop is now on arxiv arxiv.org/abs/2412.15573! We use multi-agent RL to solve a classic combinatorial optimization problem (the Sequential Assignment Problem), by combining MARL with a classical polynomial time assignment algorithm. 1/3
Repost for updating my favourite deep learning meme of all time

Six months ago someone put a for-loop around GPT-4o and got 50% on the ARC-AGI test set and 72% on a held-out training set redwoodresearch.substack.com/p/getting-50... Just sample 8000 times with beam search.
o3 is probably a more principled search technique...
o3 is probably a more principled search technique...
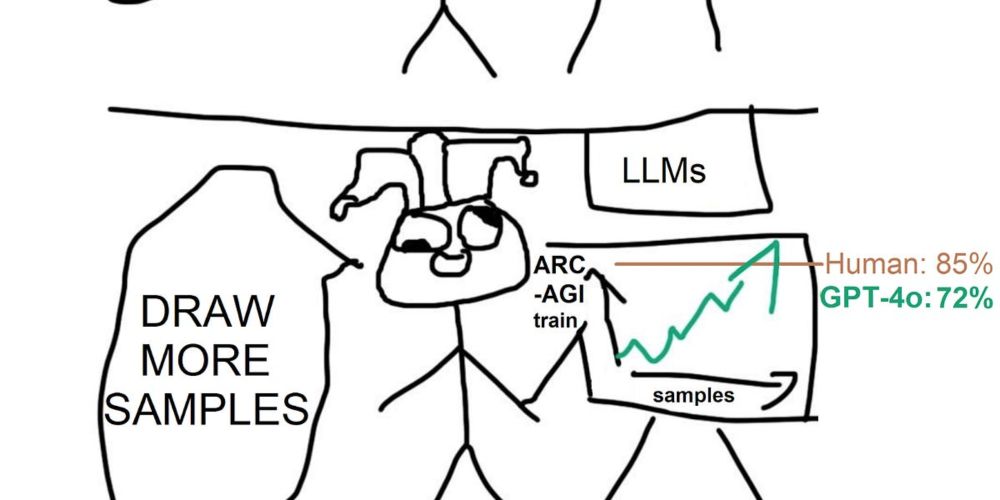
Getting 50% (SoTA) on ARC-AGI with GPT-4o
You can just draw more samples
redwoodresearch.substack.com
December 21, 2024 at 8:45 PM
Repost for updating my favourite deep learning meme of all time
Reposted by Natasha Jaques

Astonishing how many RL bottlenecks are resolved simply by “make simulator go fast”. What if we had prioritized engineering over algorithms years ago?
December 21, 2024 at 6:48 AM
Astonishing how many RL bottlenecks are resolved simply by “make simulator go fast”. What if we had prioritized engineering over algorithms years ago?
Reposted by Natasha Jaques

University of Washington researchers craft method of fine-tuning AI chatbots for individual taste www.geekwire.com/2024/univers...

University of Washington researchers craft method of fine-tuning AI chatbots for individual taste
Natasha Jaques, an assistant professor at the University of Washington's Paul G. Allen School of Computer Science & Engineering. (UW Photo) As
www.geekwire.com
December 19, 2024 at 1:39 AM
University of Washington researchers craft method of fine-tuning AI chatbots for individual taste www.geekwire.com/2024/univers...
UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...

Q&A: New AI training method lets systems better adjust to users’ values
University of Washington researchers created a method for training AI systems — both for large language models like ChatGPT and for robots — that can better reflect users’ diverse values. It...
washington.edu
December 18, 2024 at 9:51 PM
UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...
Reposted by Natasha Jaques
Really excited to present my work this Sunday @NeurIPS on how we might approach training a generalist agent capable of cooperation at scale: coordinating with many novel partners on many novel tasks has never been easier!
Come by the IMOL workshop to check it out and chat more!
Come by the IMOL workshop to check it out and chat more!
Also on Sunday, Kunal Jha @kjha02.bsky.social l will be presenting his recent work InfiniteKitchen: Cross-environment Cooperation for Zero-shot Multi-agent Coordination at the Intrinsically Motivated Open-ended Learning workshop imol-workshop.github.io
IMOL@NeurIPS 2024
Intrinsically Motivated Open-ended Learning NeurIPS 2024 in-person Workshop, December 15, Vancouver. imol.workshop@gmail.com. Description How do humans develop broad and flexible repertoires of knowle...
imol-workshop.github.io
December 12, 2024 at 6:33 PM
Really excited to present my work this Sunday @NeurIPS on how we might approach training a generalist agent capable of cooperation at scale: coordinating with many novel partners on many novel tasks has never been easier!
Come by the IMOL workshop to check it out and chat more!
Come by the IMOL workshop to check it out and chat more!
Even though the Social RL lab only got started ~1 year ago, I’m super excited to announce that we have 10 people from the lab presenting their work at #NeurIPS2024. Delighted to officially introduce our lab: socialrl.cs.washington.edu! Thread with all our NeurIPS work below 👇
SocialRL Lab
We are the Social Reinforcement Learning Lab at the University of Washington.
socialrl.cs.washington.edu
December 11, 2024 at 8:00 PM
Even though the Social RL lab only got started ~1 year ago, I’m super excited to announce that we have 10 people from the lab presenting their work at #NeurIPS2024. Delighted to officially introduce our lab: socialrl.cs.washington.edu! Thread with all our NeurIPS work below 👇
Reposted by Natasha Jaques

Let's cycle through the memes for this one until it stops... 😇😅🙏

December 2, 2024 at 1:23 AM
Let's cycle through the memes for this one until it stops... 😇😅🙏