



Here's the thing - I think it is always like this, just the degree to which it is coherent is a hyperparameter.
November 6, 2025 at 4:11 AM
Here's the thing - I think it is always like this, just the degree to which it is coherent is a hyperparameter.

accidentally forgetting to commit my hyperparameter change because I've sleep four hours in the past week and costing my company my monthly salary in compute credits
October 20, 2025 at 10:01 PM
accidentally forgetting to commit my hyperparameter change because I've sleep four hours in the past week and costing my company my monthly salary in compute credits

I'm diving into some serious hyperparameter tuning for my #chess program! ♟️
I'm using Optuna, and seriously, what a great API—it's super easy to use and makes the process so much cleaner. Getting closer to finding that optimal configuration!
#buildInPublic #chess
I'm using Optuna, and seriously, what a great API—it's super easy to use and makes the process so much cleaner. Getting closer to finding that optimal configuration!
#buildInPublic #chess

October 19, 2025 at 4:20 AM
I'm diving into some serious hyperparameter tuning for my #chess program! ♟️
I'm using Optuna, and seriously, what a great API—it's super easy to use and makes the process so much cleaner. Getting closer to finding that optimal configuration!
#buildInPublic #chess
I'm using Optuna, and seriously, what a great API—it's super easy to use and makes the process so much cleaner. Getting closer to finding that optimal configuration!
#buildInPublic #chess

TREND 7: YouTube & Tutorial Culture
Not just knowledge, but practical expertise is democratized.
"How to train your LLM" tutorials with millions of views.
Content available:
End-to-end training
Hyperparameter optimization
Infrastructure setup
Cost optimization
Troubleshooting
Not just knowledge, but practical expertise is democratized.
"How to train your LLM" tutorials with millions of views.
Content available:
End-to-end training
Hyperparameter optimization
Infrastructure setup
Cost optimization
Troubleshooting
October 17, 2025 at 12:37 PM
TREND 7: YouTube & Tutorial Culture
Not just knowledge, but practical expertise is democratized.
"How to train your LLM" tutorials with millions of views.
Content available:
End-to-end training
Hyperparameter optimization
Infrastructure setup
Cost optimization
Troubleshooting
Not just knowledge, but practical expertise is democratized.
"How to train your LLM" tutorials with millions of views.
Content available:
End-to-end training
Hyperparameter optimization
Infrastructure setup
Cost optimization
Troubleshooting

My take: Engineering *is* important. Ideas are cheap. Novelty is overrated. "Hyperparameter tuning" is a cynically dismissive term for something that is in fact the real, difficult problem.

Sometimes I’ll see a paper that implements an idea I’ve had but implements it poorly for engineering reasons. But then it’s hard to write a follow up paper because it’s not “novel” anymore
October 9, 2025 at 2:13 PM
My take: Engineering *is* important. Ideas are cheap. Novelty is overrated. "Hyperparameter tuning" is a cynically dismissive term for something that is in fact the real, difficult problem.

Gosh the next obvious statement would be on hyperparameter optimization and random architecture search but then the metaphor immediately starts stabbing you in the back 🙈
October 3, 2025 at 9:13 AM
Gosh the next obvious statement would be on hyperparameter optimization and random architecture search but then the metaphor immediately starts stabbing you in the back 🙈

I have been told I need to get more modern in my paper promotion! github.com/cvoelcker/reppo / arxiv.org/abs/2507.11019 @marcelhussing.bsky.social

September 26, 2025 at 2:51 PM
I have been told I need to get more modern in my paper promotion! github.com/cvoelcker/reppo / arxiv.org/abs/2507.11019 @marcelhussing.bsky.social

I then mapped out some analytic decisions to look at. Because I had neither infinite time nor infinite money, I looked at just four:
(1) The model used;
(2) The temperature OR reasoning effort hyperparameter setting;
(3) The demographic info provided;
(4) The way items were presented to the model.
(1) The model used;
(2) The temperature OR reasoning effort hyperparameter setting;
(3) The demographic info provided;
(4) The way items were presented to the model.

September 18, 2025 at 7:56 AM
I then mapped out some analytic decisions to look at. Because I had neither infinite time nor infinite money, I looked at just four:
(1) The model used;
(2) The temperature OR reasoning effort hyperparameter setting;
(3) The demographic info provided;
(4) The way items were presented to the model.
(1) The model used;
(2) The temperature OR reasoning effort hyperparameter setting;
(3) The demographic info provided;
(4) The way items were presented to the model.

--> i need to make unprincipled changes to a hyperparameter (the seed is a hyperparameter)
An illustrated guide to never learning anything

December 25, 2024 at 12:55 AM
--> i need to make unprincipled changes to a hyperparameter (the seed is a hyperparameter)

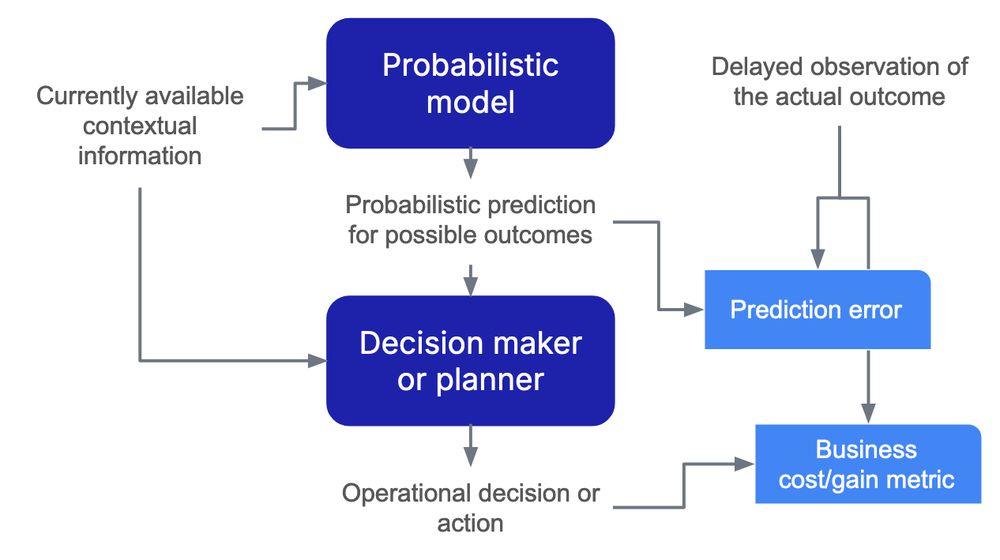
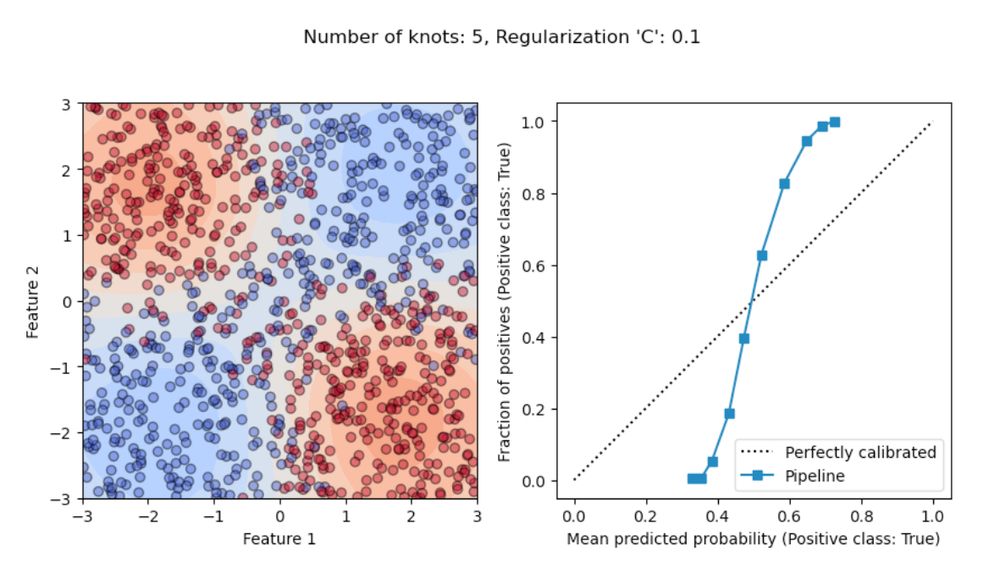
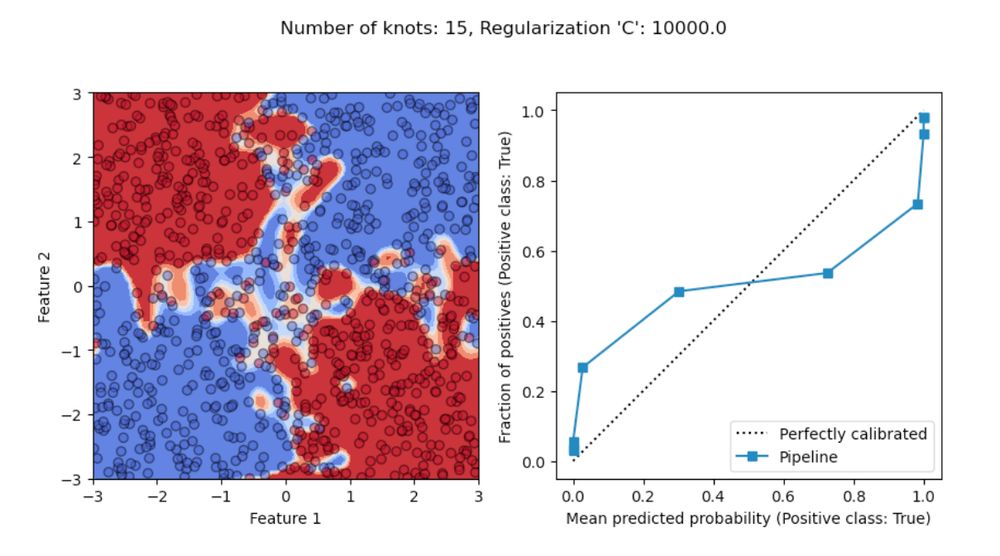
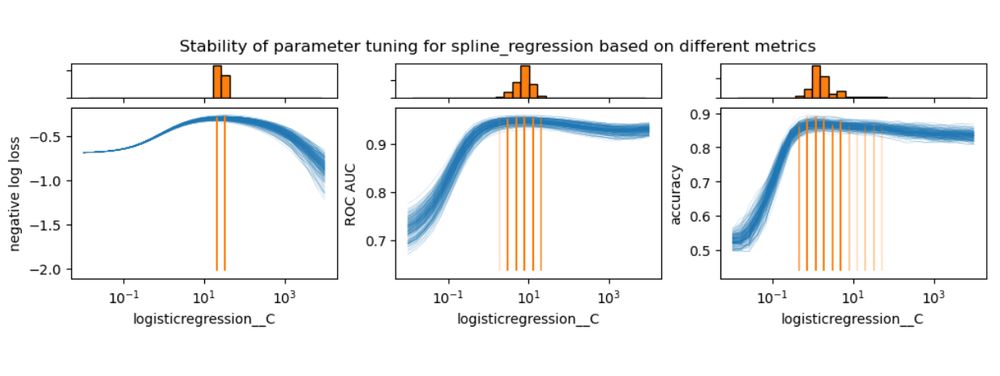
I recently shared some of my reflections on how to use probabilistic classifiers for optimal decision-making under uncertainty at @pydataparis.bsky.social 2024.
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
November 27, 2024 at 2:17 PM
I recently shared some of my reflections on how to use probabilistic classifiers for optimal decision-making under uncertainty at @pydataparis.bsky.social 2024.
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...
Here is the recording of the presentation:
www.youtube.com/watch?v=-gYn...

that none of these three architectures is capable of solving CRQs unless some hyperparameter (depth, embedding dimension, and number of chain of thought tokens, respectively) grows with the size of the input. We also provide [3/6 of https://arxiv.org/abs/2503.01544v1]
March 4, 2025 at 6:35 AM
that none of these three architectures is capable of solving CRQs unless some hyperparameter (depth, embedding dimension, and number of chain of thought tokens, respectively) grows with the size of the input. We also provide [3/6 of https://arxiv.org/abs/2503.01544v1]

Multiply Robust Estimator Circumvents Hyperparameter Tuning of Neural Network Models in Causal Inference. (arXiv:2307.10536v1 [stat.ME])
http://arxiv.org/abs/2307.10536
http://arxiv.org/abs/2307.10536
July 23, 2023 at 12:00 AM
Multiply Robust Estimator Circumvents Hyperparameter Tuning of Neural Network Models in Causal Inference. (arXiv:2307.10536v1 [stat.ME])
http://arxiv.org/abs/2307.10536
http://arxiv.org/abs/2307.10536

sohl-dickstein.github.io/2024/02/12/f...
Some cool visualization of the hyperparameter landscape of some simple neural networks - quite chaotic and interesting.
Some cool visualization of the hyperparameter landscape of some simple neural networks - quite chaotic and interesting.
February 13, 2024 at 6:30 PM
sohl-dickstein.github.io/2024/02/12/f...
Some cool visualization of the hyperparameter landscape of some simple neural networks - quite chaotic and interesting.
Some cool visualization of the hyperparameter landscape of some simple neural networks - quite chaotic and interesting.

It turns out that one can be clever and overlap the work for estimating log det(A) and the derivatives of log det(A), and that all goes together for hyperparameter tuning for Gaussian processes with lots of data points.
December 10, 2024 at 10:53 PM
It turns out that one can be clever and overlap the work for estimating log det(A) and the derivatives of log det(A), and that all goes together for hyperparameter tuning for Gaussian processes with lots of data points.

Using hyperparameter tuning on ML Engine, I found the sweet spot for batch norm and hit 99.5% accuracy on MNIST in only 4 epochs (!) 2/4

February 6, 2025 at 5:39 PM
Using hyperparameter tuning on ML Engine, I found the sweet spot for batch norm and hit 99.5% accuracy on MNIST in only 4 epochs (!) 2/4

Automated hyperparameter tuning using any conformalized surrogate
https://thierrymoudiki.github.io/blog/2024/06/09/python/quasirandomizednn/conformal-bayesopt
#Techtonique #DataScience #Python #rstats #MachineLearning
https://thierrymoudiki.github.io/blog/2024/06/09/python/quasirandomizednn/conformal-bayesopt
#Techtonique #DataScience #Python #rstats #MachineLearning

March 31, 2025 at 12:28 PM
Automated hyperparameter tuning using any conformalized surrogate
https://thierrymoudiki.github.io/blog/2024/06/09/python/quasirandomizednn/conformal-bayesopt
#Techtonique #DataScience #Python #rstats #MachineLearning
https://thierrymoudiki.github.io/blog/2024/06/09/python/quasirandomizednn/conformal-bayesopt
#Techtonique #DataScience #Python #rstats #MachineLearning

Alessio Tosolini, Claire Bowern
Data Augmentation and Hyperparameter Tuning for Low-Resource MFA
https://arxiv.org/abs/2504.07024
Data Augmentation and Hyperparameter Tuning for Low-Resource MFA
https://arxiv.org/abs/2504.07024
April 10, 2025 at 5:44 AM
Alessio Tosolini, Claire Bowern
Data Augmentation and Hyperparameter Tuning for Low-Resource MFA
https://arxiv.org/abs/2504.07024
Data Augmentation and Hyperparameter Tuning for Low-Resource MFA
https://arxiv.org/abs/2504.07024

A hyperparameter-randomized ensemble approach for robust clustering across diverse datasets https://www.biorxiv.org/content/10.1101/2023.12.18.571953v1

A hyperparameter-randomized ensemble approach for robust clustering across diverse datasets https://www.biorxiv.org/content/10.1101/2023.12.18.571953v1
Clustering analysis is widely used to group objects by similarity, but for complex datasets such as
www.biorxiv.org
December 19, 2023 at 7:55 PM
A hyperparameter-randomized ensemble approach for robust clustering across diverse datasets https://www.biorxiv.org/content/10.1101/2023.12.18.571953v1
values for basic regularization techniques (i.e. weight decay, label smoothing, and dropout). In particular, our best NAdamW hyperparameter list performs well on AlgoPerf held-out workloads not used to construct it, and represents a compelling [6/7 of https://arxiv.org/abs/2503.03986v1]
March 7, 2025 at 6:34 AM
values for basic regularization techniques (i.e. weight decay, label smoothing, and dropout). In particular, our best NAdamW hyperparameter list performs well on AlgoPerf held-out workloads not used to construct it, and represents a compelling [6/7 of https://arxiv.org/abs/2503.03986v1]
requiring significantly fewer discretization steps and no hyperparameter tuning. [6/6 of https://arxiv.org/abs/2503.01006v1]
March 4, 2025 at 6:32 AM
requiring significantly fewer discretization steps and no hyperparameter tuning. [6/6 of https://arxiv.org/abs/2503.01006v1]
instability. This highlights the trade-off between performance optimization and prediction consistency, raising concerns about the risk of arbitrary predictions. These findings provide insight into how hyperparameter optimization leads to predictive [6/7 of https://arxiv.org/abs/2503.13506v1]
March 19, 2025 at 5:58 AM
instability. This highlights the trade-off between performance optimization and prediction consistency, raising concerns about the risk of arbitrary predictions. These findings provide insight into how hyperparameter optimization leads to predictive [6/7 of https://arxiv.org/abs/2503.13506v1]

been wanting to try wandb sweeps for quite sometime; the code was super simple

November 14, 2024 at 4:31 AM
been wanting to try wandb sweeps for quite sometime; the code was super simple

autonomous design of materials with tailored functionalities. By leveraging AutoML frameworks (e.g., AutoGluon, TPOT, and H2O.ai), researchers can automate the model selection, hyperparameter tuning, and feature engineering, significantly improving [4/9 of https://arxiv.org/abs/2503.18975v1]
March 26, 2025 at 6:07 AM
autonomous design of materials with tailored functionalities. By leveraging AutoML frameworks (e.g., AutoGluon, TPOT, and H2O.ai), researchers can automate the model selection, hyperparameter tuning, and feature engineering, significantly improving [4/9 of https://arxiv.org/abs/2503.18975v1]
against a strong, workload-agnostic baseline is important to improve hyperparameter reduction techniques. [8/8 of https://arxiv.org/abs/2505.24005v1]
June 2, 2025 at 6:03 AM
against a strong, workload-agnostic baseline is important to improve hyperparameter reduction techniques. [8/8 of https://arxiv.org/abs/2505.24005v1]
Wang, Deng, Hu, Zhang, Jiang, Zhang, Zhao, W.: Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining https://arxiv.org/abs/2505.24261 https://arxiv.org/pdf/2505.24261 https://arxiv.org/html/2505.24261
June 2, 2025 at 6:09 AM
Wang, Deng, Hu, Zhang, Jiang, Zhang, Zhao, W.: Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining https://arxiv.org/abs/2505.24261 https://arxiv.org/pdf/2505.24261 https://arxiv.org/html/2505.24261