



Yanai Elazar
@yanai.bsky.social
Assistant Professor at Bar-Ilan University
https://yanaiela.github.io/
https://yanaiela.github.io/
Interested in interpretability, data attribution, evaluation, and similar topics?
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
November 13, 2025 at 1:59 PM
Interested in interpretability, data attribution, evaluation, and similar topics?
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)

Reposted by Yanai Elazar

"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)


September 24, 2025 at 1:21 PM
"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
Reposted by Yanai Elazar

I did a QA with Quanta about interpretability and training dynamics! I got to talk about a bunch of research hobby horses and how I got into them.

I really enjoyed talking to @nsaphra.bsky.social about her thoughts on what much language model interpretability research misses. My latest in @quantamagazine.bsky.social:

To Understand AI, Watch How It Evolves | Quanta Magazine
Naomi Saphra thinks that most research into language models focuses too much on the finished product. She’s mining the history of their training for insights into why these systems work the way they d...
www.quantamagazine.org
September 24, 2025 at 1:57 PM
I did a QA with Quanta about interpretability and training dynamics! I got to talk about a bunch of research hobby horses and how I got into them.
The new Tahoe UI is so bad. Everything just looks so blurred...
September 24, 2025 at 12:20 PM
The new Tahoe UI is so bad. Everything just looks so blurred...
Interesting opportunity for a research visit through the Azrieli foundation - azrielifoundation.org/azrieli-fell...
Let me know if you're interested!
Let me know if you're interested!

Call for Applications for the Azrieli International Visiting PhD Fellowship - The Azrieli Foundation
The Azrieli International Visiting PhD Fellowship offers outstanding international PhD candidates the opportunity to conduct short-term research in Israel, fostering academic collaboration and strengt...
azrielifoundation.org
September 18, 2025 at 7:34 AM
Interesting opportunity for a research visit through the Azrieli foundation - azrielifoundation.org/azrieli-fell...
Let me know if you're interested!
Let me know if you're interested!
Organizing a workshop? Checkout our compiled material for organizing one: www.bigpictureworkshop.com/open-workshop
(and hopefully we'll be back for another iteration of the Big Picture next year w/ Allyson Ettinger, @norakassner.bsky.social, @sebruder.bsky.social)
(and hopefully we'll be back for another iteration of the Big Picture next year w/ Allyson Ettinger, @norakassner.bsky.social, @sebruder.bsky.social)
Big Picture Workshop - Open Workshop
Open sourcing the workshop
www.bigpictureworkshop.com
September 3, 2025 at 2:55 PM
Organizing a workshop? Checkout our compiled material for organizing one: www.bigpictureworkshop.com/open-workshop
(and hopefully we'll be back for another iteration of the Big Picture next year w/ Allyson Ettinger, @norakassner.bsky.social, @sebruder.bsky.social)
(and hopefully we'll be back for another iteration of the Big Picture next year w/ Allyson Ettinger, @norakassner.bsky.social, @sebruder.bsky.social)
I’m excited to share that I'm joining Bar-Ilan University as an assistant professor!

August 14, 2025 at 12:45 PM
I’m excited to share that I'm joining Bar-Ilan University as an assistant professor!
A strange trend I've noticed at #ACL2025 is that people are hesitant to reach out to papers/"academic products" authors.
This is unfortunate for both parties! A simple email can save a lot of time to the sender, but is also one of my favorite kind of email as the receiver!
This is unfortunate for both parties! A simple email can save a lot of time to the sender, but is also one of my favorite kind of email as the receiver!
August 4, 2025 at 4:10 PM
A strange trend I've noticed at #ACL2025 is that people are hesitant to reach out to papers/"academic products" authors.
This is unfortunate for both parties! A simple email can save a lot of time to the sender, but is also one of my favorite kind of email as the receiver!
This is unfortunate for both parties! A simple email can save a lot of time to the sender, but is also one of my favorite kind of email as the receiver!
Reposted by Yanai Elazar

The EPFL NLP lab is looking to hire a postdoctoral researcher on the topic of designing, training, and evaluating multilingual LLMs:
docs.google.com/document/d/1...
Come join our dynamic group in beautiful Lausanne!
docs.google.com/document/d/1...
Come join our dynamic group in beautiful Lausanne!

EPFL NLP Postdoctoral Scholar Posting - Swiss AI LLMs
The EPFL Natural Language Processing (NLP) lab is looking to hire a postdoctoral researcher candidate in the area of multilingual LLM design, training, and evaluation. This postdoctoral position is as...
docs.google.com
August 4, 2025 at 3:54 PM
The EPFL NLP lab is looking to hire a postdoctoral researcher on the topic of designing, training, and evaluating multilingual LLMs:
docs.google.com/document/d/1...
Come join our dynamic group in beautiful Lausanne!
docs.google.com/document/d/1...
Come join our dynamic group in beautiful Lausanne!
Reposted by Yanai Elazar

Had a really great and fun time with @yanai.bsky.social, Niloofar Mireshghallah, and Reza Shokri discussing memorisation at the @l2m2workshop.bsky.social panel. Thanks to the entire organising team and attendees for making this such a fantastic workshop! #ACL2025
I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
August 2, 2025 at 5:02 PM
Had a really great and fun time with @yanai.bsky.social, Niloofar Mireshghallah, and Reza Shokri discussing memorisation at the @l2m2workshop.bsky.social panel. Thanks to the entire organising team and attendees for making this such a fantastic workshop! #ACL2025
I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
August 2, 2025 at 3:04 PM
I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
Reposted by Yanai Elazar

I'll present our work w/ @santosh-tyss.bsky.social
@yanai.bsky.social @barbaraplank.bsky.social on LLMs memorization of distributions of political leanings in their pretraining data! Catch us at L2M2 workshop @l2m2workshop.bsky.social #ACL2025 tmrw
📆 Aug 1, 14:00–15:30 📑 arxiv.org/pdf/2502.18282
@yanai.bsky.social @barbaraplank.bsky.social on LLMs memorization of distributions of political leanings in their pretraining data! Catch us at L2M2 workshop @l2m2workshop.bsky.social #ACL2025 tmrw
📆 Aug 1, 14:00–15:30 📑 arxiv.org/pdf/2502.18282

July 31, 2025 at 8:41 AM
I'll present our work w/ @santosh-tyss.bsky.social
@yanai.bsky.social @barbaraplank.bsky.social on LLMs memorization of distributions of political leanings in their pretraining data! Catch us at L2M2 workshop @l2m2workshop.bsky.social #ACL2025 tmrw
📆 Aug 1, 14:00–15:30 📑 arxiv.org/pdf/2502.18282
@yanai.bsky.social @barbaraplank.bsky.social on LLMs memorization of distributions of political leanings in their pretraining data! Catch us at L2M2 workshop @l2m2workshop.bsky.social #ACL2025 tmrw
📆 Aug 1, 14:00–15:30 📑 arxiv.org/pdf/2502.18282
Reposted by Yanai Elazar

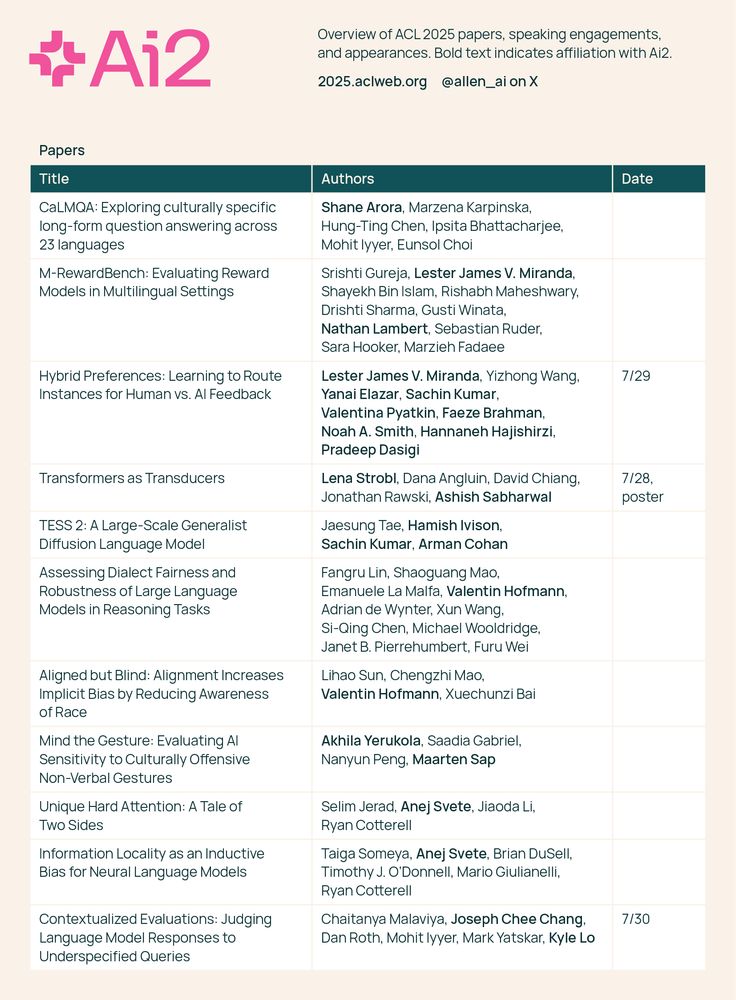
Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚

July 28, 2025 at 5:00 PM
Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚
It's crazy that people give more than a single invited talk during the same conference (diff workshops).
A single talk (done right) is challenging enough.
A single talk (done right) is challenging enough.
July 19, 2025 at 6:16 PM
It's crazy that people give more than a single invited talk during the same conference (diff workshops).
A single talk (done right) is challenging enough.
A single talk (done right) is challenging enough.
Reposted by Yanai Elazar

What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
July 10, 2025 at 5:26 PM
What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
I really like this take. Academia and the open source community should embrace transparency in data, even in the cost of the issues that come with it. These issues should be of course studied and documented, but not used as an indicator or a signal to shut down the whole operation.

Fully open machine learning requires not only GPU access but a community commitment to openness. (Some nostalgic lessons from the ImageNet decade.)

An open mindset
The commitments required for fully open source machine learning
www.argmin.net
July 10, 2025 at 4:14 PM
I really like this take. Academia and the open source community should embrace transparency in data, even in the cost of the issues that come with it. These issues should be of course studied and documented, but not used as an indicator or a signal to shut down the whole operation.
Reposted by Yanai Elazar

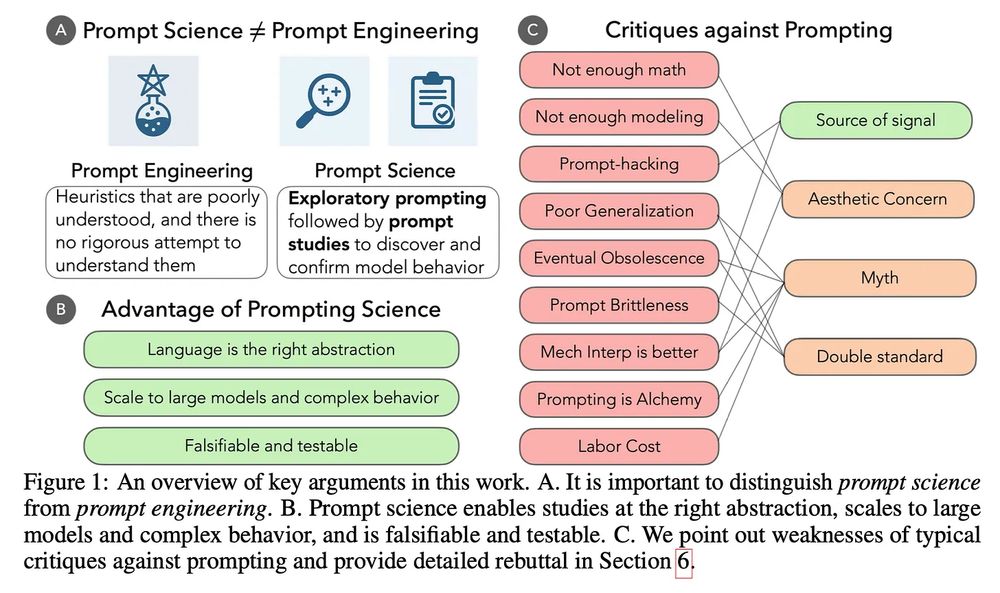
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
July 9, 2025 at 8:07 PM
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
What's up with @arxiv-cs-cl.bsky.social
Wasn't the entire premise of this website to allow uploading of papers w/o the official peer review process??
Wasn't the entire premise of this website to allow uploading of papers w/o the official peer review process??
July 1, 2025 at 5:51 PM
What's up with @arxiv-cs-cl.bsky.social
Wasn't the entire premise of this website to allow uploading of papers w/o the official peer review process??
Wasn't the entire premise of this website to allow uploading of papers w/o the official peer review process??
Check out our take on Chain-of-Thought.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.

Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵

July 1, 2025 at 5:45 PM
Check out our take on Chain-of-Thought.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
Reposted by Yanai Elazar

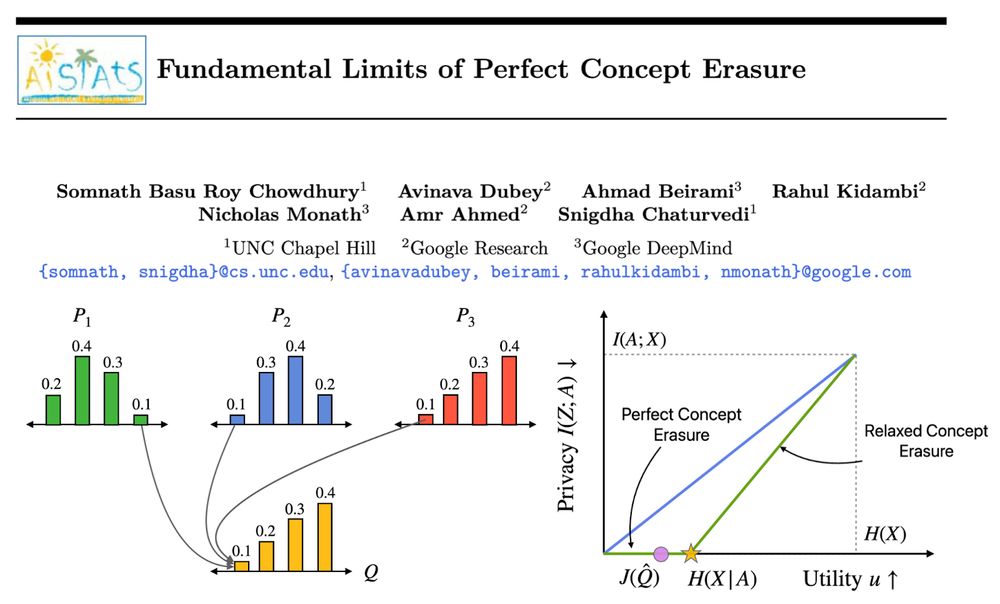
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
April 2, 2025 at 4:03 PM
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Reposted by Yanai Elazar

I'll be at #NAACL2025:
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
April 27, 2025 at 8:00 PM
I'll be at #NAACL2025:
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
💡 New ICLR paper! 💡
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social

April 25, 2025 at 1:55 AM
💡 New ICLR paper! 💡
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social
I'm on my way to ICLR!
Let me know if you want to meet and/or hang out 🥳
Let me know if you want to meet and/or hang out 🥳
April 22, 2025 at 11:41 PM
I'm on my way to ICLR!
Let me know if you want to meet and/or hang out 🥳
Let me know if you want to meet and/or hang out 🥳
Reposted by Yanai Elazar

I might be able to hire a postdoc for this fall in computational linguistics at UT Austin. Topics in the general LLM + cognitive space (particularly reasoning, chain of thought, LLMs + code) and LLM + linguistic space. If this could be of interest, feel free to get in touch!
April 21, 2025 at 3:56 PM
I might be able to hire a postdoc for this fall in computational linguistics at UT Austin. Topics in the general LLM + cognitive space (particularly reasoning, chain of thought, LLMs + code) and LLM + linguistic space. If this could be of interest, feel free to get in touch!