


Pietro Lesci
@pietrolesci.bsky.social
PhD student at Cambridge University. Causality & language models. Passionate musician, professional debugger.
pietrolesci.github.io
pietrolesci.github.io
Had a really great and fun time with @yanai.bsky.social, Niloofar Mireshghallah, and Reza Shokri discussing memorisation at the @l2m2workshop.bsky.social panel. Thanks to the entire organising team and attendees for making this such a fantastic workshop! #ACL2025

I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
August 2, 2025 at 5:02 PM
Had a really great and fun time with @yanai.bsky.social, Niloofar Mireshghallah, and Reza Shokri discussing memorisation at the @l2m2workshop.bsky.social panel. Thanks to the entire organising team and attendees for making this such a fantastic workshop! #ACL2025
Reposted by Pietro Lesci

@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
BPE is a greedy method to find a tokeniser which maximises compression! Why don't we try to find properly optimal tokenisers instead? Well, it seems this is a pretty difficult—in fact, NP-complete—problem!🤯
New paper + @philipwitti.bsky.social
@gregorbachmann.bsky.social :) arxiv.org/abs/2412.15210
New paper + @philipwitti.bsky.social
@gregorbachmann.bsky.social :) arxiv.org/abs/2412.15210

Tokenisation is NP-Complete
In this work, we prove the NP-completeness of two variants of tokenisation, defined as the problem of compressing a dataset to at most $δ$ symbols by either finding a vocabulary directly (direct token...
arxiv.org
July 27, 2025 at 9:41 AM
@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
Reposted by Pietro Lesci

Just arrived in Vienna for ACL 2025 🇦🇹 Excited to be here and to finally meet so many people in person!
We have several papers this year and many from @milanlp.bsky.social are around, come say hi!
Here are all the works I'm involved in ⤵️
#ACL2025 #ACL2025NLP
We have several papers this year and many from @milanlp.bsky.social are around, come say hi!
Here are all the works I'm involved in ⤵️
#ACL2025 #ACL2025NLP

🎉 The @milanlp.bsky.social lab is excited to present 15 papers and 1 tutorial at #ACL2025 & workshops! Grateful to all our amazing collaborators, see everyone in Vienna! 🚀



July 27, 2025 at 10:29 AM
Just arrived in Vienna for ACL 2025 🇦🇹 Excited to be here and to finally meet so many people in person!
We have several papers this year and many from @milanlp.bsky.social are around, come say hi!
Here are all the works I'm involved in ⤵️
#ACL2025 #ACL2025NLP
We have several papers this year and many from @milanlp.bsky.social are around, come say hi!
Here are all the works I'm involved in ⤵️
#ACL2025 #ACL2025NLP
Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
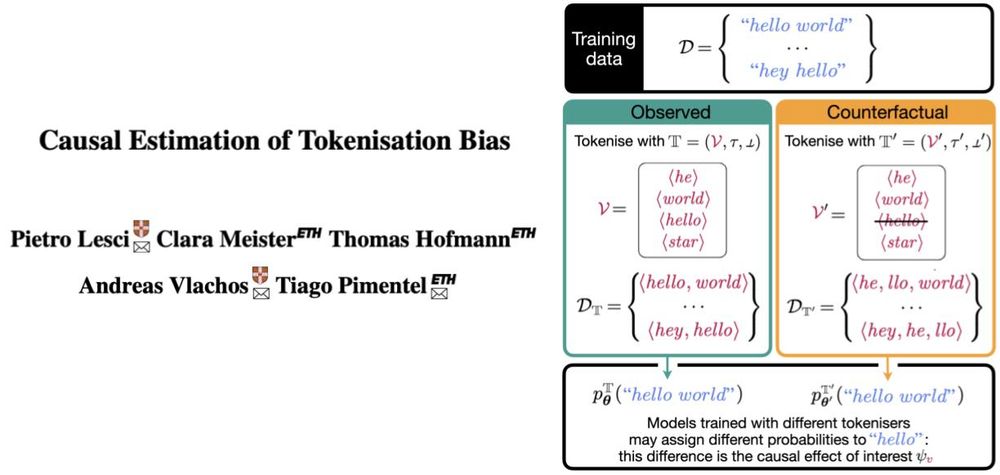
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
July 27, 2025 at 6:40 AM
Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
June 5, 2025 at 10:43 AM
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Reposted by Pietro Lesci
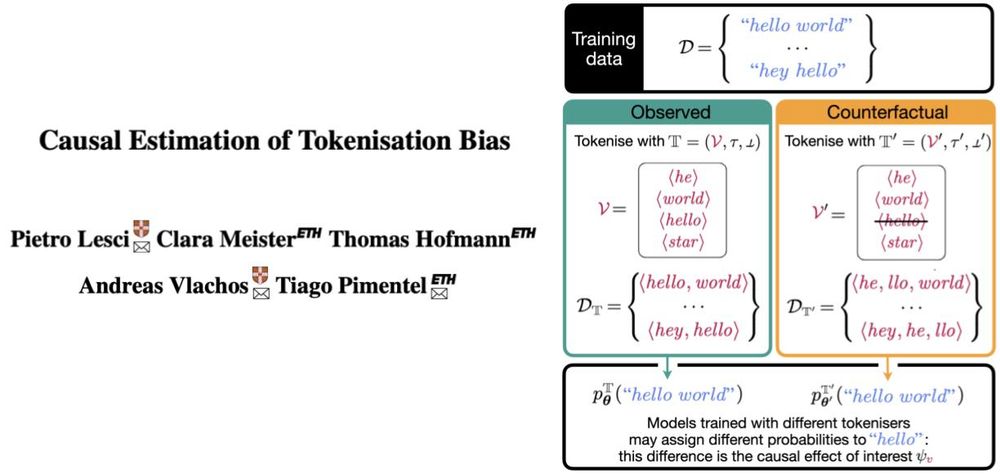
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
June 4, 2025 at 10:51 AM
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
Reposted by Pietro Lesci
If you're finishing your camera-ready for ACL or ICML and want to cite co-first authors more fairly, I just made a simple fix to do this! Just add $^*$ to the authors' names in your bibtex, and the citations should change :)
github.com/tpimentelms/...
github.com/tpimentelms/...

May 29, 2025 at 8:53 AM
If you're finishing your camera-ready for ACL or ICML and want to cite co-first authors more fairly, I just made a simple fix to do this! Just add $^*$ to the authors' names in your bibtex, and the citations should change :)
github.com/tpimentelms/...
github.com/tpimentelms/...
Reposted by Pietro Lesci

📢 @aclmeeting.bsky.social notifications have been sent out, making this the perfect time to finalize your commitment. Don't miss the opportunity to be part of the L2M2 workshop!
🔗 Commit here: openreview.net/group?id=acl...
🗓️ Deadline: May 20, 2025 (AoE)
#ACL2025 #NLProc
🔗 Commit here: openreview.net/group?id=acl...
🗓️ Deadline: May 20, 2025 (AoE)
#ACL2025 #NLProc

ACL 2025 Workshop L2M2 ARR Commitment
Welcome to the OpenReview homepage for ACL 2025 Workshop L2M2 ARR Commitment
openreview.net
May 16, 2025 at 2:57 PM
📢 @aclmeeting.bsky.social notifications have been sent out, making this the perfect time to finalize your commitment. Don't miss the opportunity to be part of the L2M2 workshop!
🔗 Commit here: openreview.net/group?id=acl...
🗓️ Deadline: May 20, 2025 (AoE)
#ACL2025 #NLProc
🔗 Commit here: openreview.net/group?id=acl...
🗓️ Deadline: May 20, 2025 (AoE)
#ACL2025 #NLProc
I'm truly honoured that our paper "Causal Estimation of Memorisation Profiles" has been selected as the Paper of the Year by @cst.cam.ac.uk 🎉
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!

🎉 Congratulations @pietrolesci.bsky.social, Clara Meister, Thomas Hofmann, @andreasvlachos.bsky.social & Tiago Pimentel! They won Publication of the Year at our annual Hall of Fame awards last week for their paper on 'Causal Estimation of Memorisation Profiles'. www.cst.cam.ac.uk/announcing-w...

April 30, 2025 at 4:10 AM
I'm truly honoured that our paper "Causal Estimation of Memorisation Profiles" has been selected as the Paper of the Year by @cst.cam.ac.uk 🎉
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
✈️ Headed to @iclr-conf.bsky.social — whether you’ll be there in person or tuning in remotely, I’d love to connect!
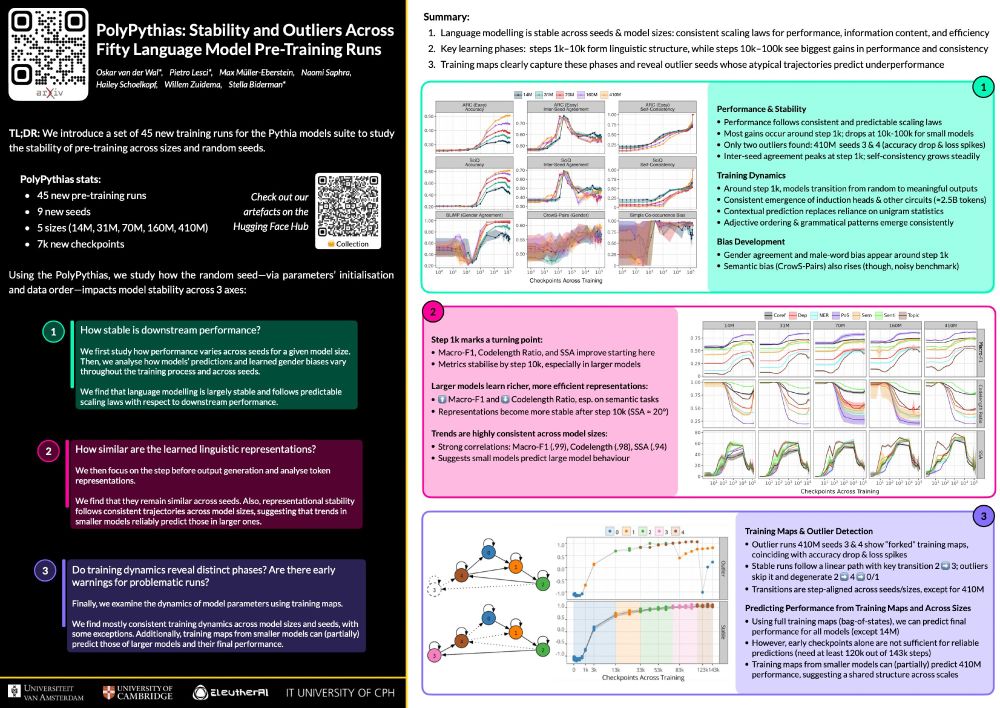
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
April 22, 2025 at 11:02 AM
✈️ Headed to @iclr-conf.bsky.social — whether you’ll be there in person or tuning in remotely, I’d love to connect!
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
We’ll be presenting our paper on pre-training stability in language models and the PolyPythias 🧵
🔗 ArXiv: arxiv.org/abs/2503.09543
🤗 PolyPythias: huggingface.co/collections/...
The First Workshop on Large Language Model Memorization will be co-located at @aclmeeting.bsky.social in Vienna. Help us spread the word!
📢 The First Workshop on Large Language Model Memorization (L2M2) will be co-located with
@aclmeeting.bsky.social in Vienna 🎉
💡 L2M2 brings together researchers to explore memorization from multiple angles. Whether it's text-only LLMs or Vision-language models, we want to hear from you! 🌍
@aclmeeting.bsky.social in Vienna 🎉
💡 L2M2 brings together researchers to explore memorization from multiple angles. Whether it's text-only LLMs or Vision-language models, we want to hear from you! 🌍
January 27, 2025 at 9:53 PM
The First Workshop on Large Language Model Memorization will be co-located at @aclmeeting.bsky.social in Vienna. Help us spread the word!
Reposted by Pietro Lesci

This year, when students of my optimization class were asking for references related to forward-backward mode autodiff, I didn't suggest books or articles: #JAX documentation was actually the best thing I've found! What's your go-to reference for this?
November 26, 2024 at 3:15 AM
This year, when students of my optimization class were asking for references related to forward-backward mode autodiff, I didn't suggest books or articles: #JAX documentation was actually the best thing I've found! What's your go-to reference for this?
Reposted by Pietro Lesci

Can deep learning finally compete with boosted trees on tabular data? 🌲
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵

November 18, 2024 at 2:15 PM
Can deep learning finally compete with boosted trees on tabular data? 🌲
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
In our NeurIPS 2024 paper, we introduce RealMLP, a NN with improvements in all areas and meta-learned default parameters.
Some insights about RealMLP and other models on large benchmarks (>200 datasets): 🧵
Reposted by Pietro Lesci

Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
November 27, 2024 at 9:00 AM
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
Amazing resource by @brandfonbrener.bsky.social and co-authors. They train and release (the last checkpoint of) >500 models with sizes 20M to 3.3B params and FLOPs 2e17 to 1e21 across 6 different pre-training datasets.
Bonus: They have evaluations on downstream benchmarks!
Great work! 🚀
Bonus: They have evaluations on downstream benchmarks!
Great work! 🚀

How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.

November 27, 2024 at 6:15 PM
Amazing resource by @brandfonbrener.bsky.social and co-authors. They train and release (the last checkpoint of) >500 models with sizes 20M to 3.3B params and FLOPs 2e17 to 1e21 across 6 different pre-training datasets.
Bonus: They have evaluations on downstream benchmarks!
Great work! 🚀
Bonus: They have evaluations on downstream benchmarks!
Great work! 🚀
Our lab is on Bluesky now: bsky.app/profile/camb... 🎉
bsky.app
November 25, 2024 at 11:25 AM
Our lab is on Bluesky now: bsky.app/profile/camb... 🎉
First post here. I found this thread of started packs very useful!

November 22, 2024 at 7:54 PM
First post here. I found this thread of started packs very useful!