


Leqi Liu
@leqiliu.bsky.social
AI/ML Researcher | Assistant Professor at UT Austin | Postdoc at Princeton PLI | PhD, Machine Learning Department, CMU. Research goal: Building controllable machine intelligence that serves humanity safely. leqiliu.github.io
We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2026! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: tinyurl.com/use-inspired....
Learn more & apply: tinyurl.com/use-inspired....
October 31, 2025 at 5:43 PM
We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2026! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: tinyurl.com/use-inspired....
Learn more & apply: tinyurl.com/use-inspired....
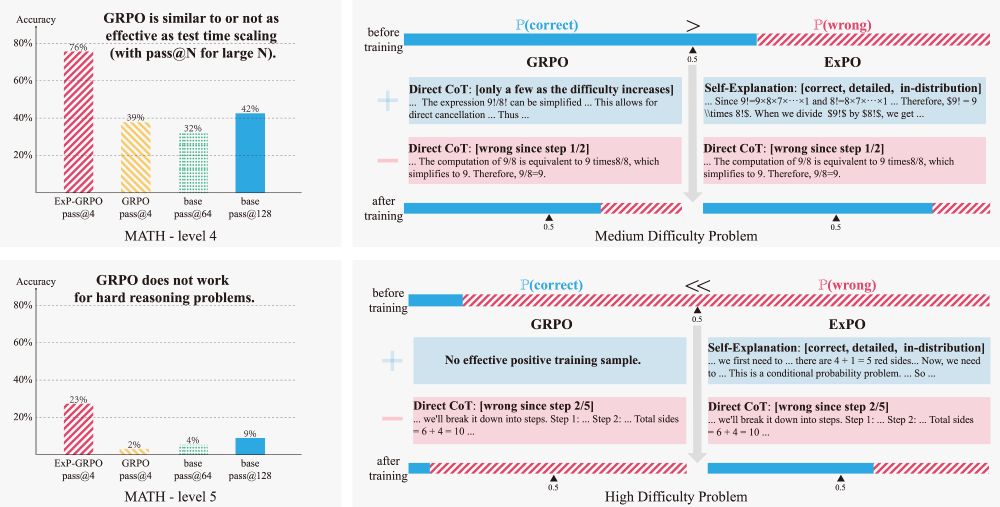
New method to crack hard reasoning problems with LLM!
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
July 22, 2025 at 5:09 PM
New method to crack hard reasoning problems with LLM!
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
July 10, 2025 at 5:26 PM
What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
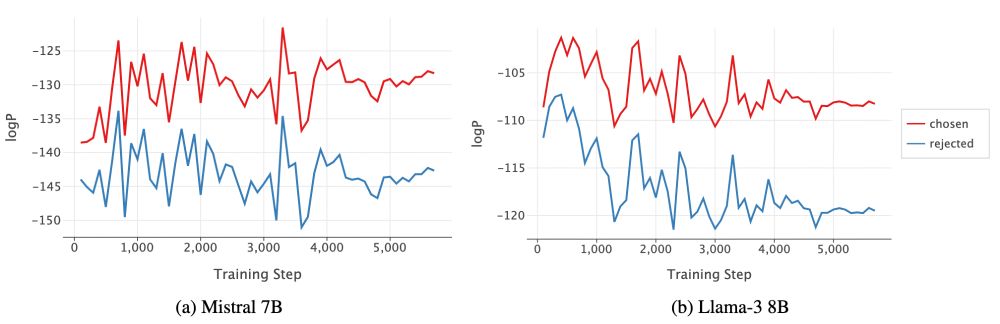
Ever wondered why there are synchronized ups and downs for chosen and rejected log-probs during DPO (and most *POs: IPO, SimPO, CPO, R-DPO, DPOP, RRHF, SlicHF) training? Why do chosen logps decrease, and rejected logps sometimes increase?
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
December 14, 2024 at 5:38 PM
Ever wondered why there are synchronized ups and downs for chosen and rejected log-probs during DPO (and most *POs: IPO, SimPO, CPO, R-DPO, DPOP, RRHF, SlicHF) training? Why do chosen logps decrease, and rejected logps sometimes increase?
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
How to **efficiently** build personalized language models **without** textual info on user preferences?
Our Personalized-RLHF work:
- light-weight user model
- personalize all *PO alignment algorithms
- strong performance on the largest personalized preference dataset
arxiv.org/abs/2402.05133
Our Personalized-RLHF work:
- light-weight user model
- personalize all *PO alignment algorithms
- strong performance on the largest personalized preference dataset
arxiv.org/abs/2402.05133
December 14, 2024 at 5:02 PM
How to **efficiently** build personalized language models **without** textual info on user preferences?
Our Personalized-RLHF work:
- light-weight user model
- personalize all *PO alignment algorithms
- strong performance on the largest personalized preference dataset
arxiv.org/abs/2402.05133
Our Personalized-RLHF work:
- light-weight user model
- personalize all *PO alignment algorithms
- strong performance on the largest personalized preference dataset
arxiv.org/abs/2402.05133
Reposted by Leqi Liu

We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2025! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: t.co/OPrxO3yMhf
Learn more & apply: t.co/OPrxO3yMhf
http://tinyurl.com/use-inspired-ai-f25
t.co
November 20, 2024 at 8:43 PM
We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2025! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: t.co/OPrxO3yMhf
Learn more & apply: t.co/OPrxO3yMhf