



Leqi Liu
@leqiliu.bsky.social
AI/ML Researcher | Assistant Professor at UT Austin | Postdoc at Princeton PLI | PhD, Machine Learning Department, CMU. Research goal: Building controllable machine intelligence that serves humanity safely. leqiliu.github.io
We plug ExPO into:
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
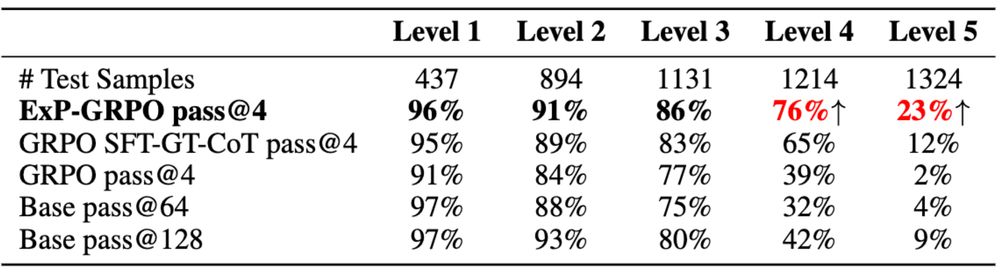
Results (Qwen2.5-3B-Instruct, MATH level-5):
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
July 22, 2025 at 5:09 PM
We plug ExPO into:
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
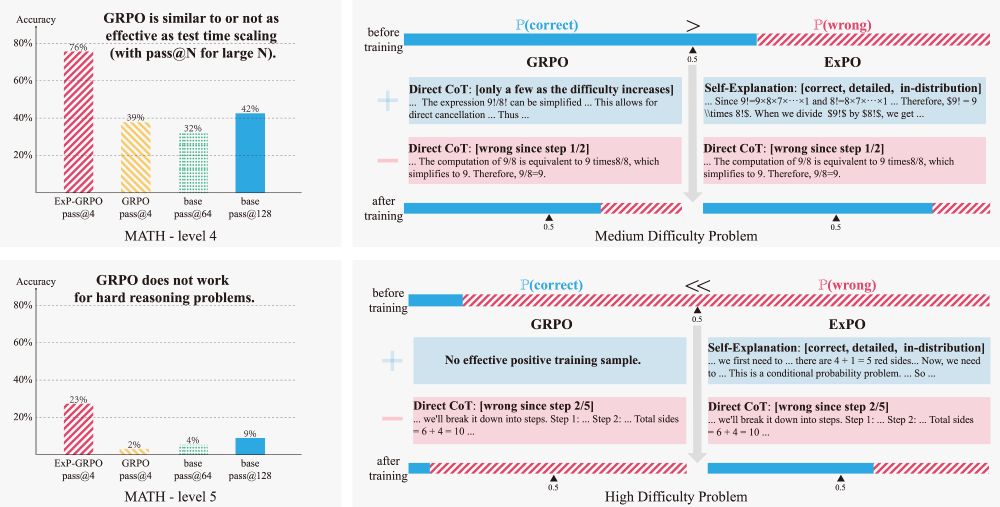
New method to crack hard reasoning problems with LLM!
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
July 22, 2025 at 5:09 PM
New method to crack hard reasoning problems with LLM!
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
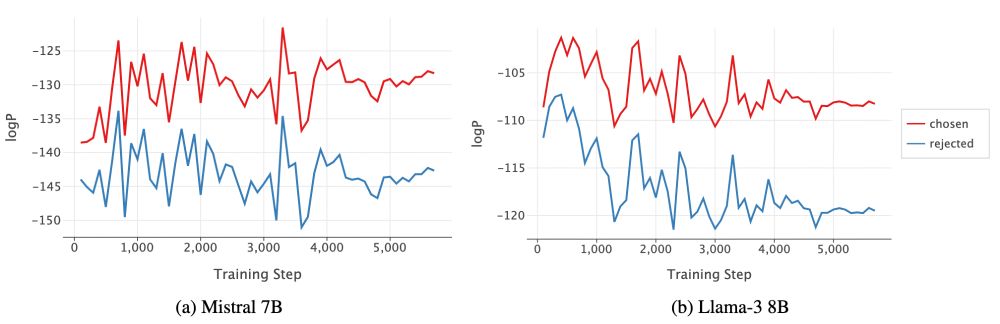
Ever wondered why there are synchronized ups and downs for chosen and rejected log-probs during DPO (and most *POs: IPO, SimPO, CPO, R-DPO, DPOP, RRHF, SlicHF) training? Why do chosen logps decrease, and rejected logps sometimes increase?
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
December 14, 2024 at 5:38 PM
Ever wondered why there are synchronized ups and downs for chosen and rejected log-probs during DPO (and most *POs: IPO, SimPO, CPO, R-DPO, DPOP, RRHF, SlicHF) training? Why do chosen logps decrease, and rejected logps sometimes increase?
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828