


Tom Everitt
@tom4everitt.bsky.social
AGI safety researcher at Google DeepMind, leading causalincentives.com
Personal website: tomeveritt.se
Personal website: tomeveritt.se
Pinned
Tom Everitt
@tom4everitt.bsky.social
· Apr 17

What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
Reposted by Tom Everitt

New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @alexirpan.bsky.social, me, Mark Kurzeja, David Elson, and Rohin Shah. (thread)

November 4, 2025 at 12:18 AM
New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @alexirpan.bsky.social, me, Mark Kurzeja, David Elson, and Rohin Shah. (thread)
Reposted by Tom Everitt

[1/9] Excited to share our new paper "A Pragmatic View of AI Personhood" published today. We feel this topic is timely, and rapidly growing in importance as AI becomes agentic, as AI agents integrate further into the economy, and as more and more users encounter AI.
October 31, 2025 at 12:32 PM
[1/9] Excited to share our new paper "A Pragmatic View of AI Personhood" published today. We feel this topic is timely, and rapidly growing in importance as AI becomes agentic, as AI agents integrate further into the economy, and as more and more users encounter AI.
Reposted by Tom Everitt

Evaluating the Infinite
🧵
My latest paper tries to solve a longstanding problem afflicting fields such as decision theory, economics, and ethics — the problem of infinities.
Let me explain a bit about what causes the problem and how my solution avoids it.
1/N
arxiv.org/abs/2509.19389
🧵
My latest paper tries to solve a longstanding problem afflicting fields such as decision theory, economics, and ethics — the problem of infinities.
Let me explain a bit about what causes the problem and how my solution avoids it.
1/N
arxiv.org/abs/2509.19389

Evaluating the Infinite
I present a novel mathematical technique for dealing with the infinities arising from divergent sums and integrals. It assigns them fine-grained infinite values from the set of hyperreal numbers in a ...
arxiv.org
September 25, 2025 at 3:28 PM
Evaluating the Infinite
🧵
My latest paper tries to solve a longstanding problem afflicting fields such as decision theory, economics, and ethics — the problem of infinities.
Let me explain a bit about what causes the problem and how my solution avoids it.
1/N
arxiv.org/abs/2509.19389
🧵
My latest paper tries to solve a longstanding problem afflicting fields such as decision theory, economics, and ethics — the problem of infinities.
Let me explain a bit about what causes the problem and how my solution avoids it.
1/N
arxiv.org/abs/2509.19389
Reposted by Tom Everitt

Do you have a PhD (or equivalent) or will have one in the coming months (i.e. 2-3 months away from graduating)? Do you want to help build open-ended agents that help humans do humans things better, rather than replace them? We're hiring 1-2 Research Scientists! Check the 🧵👇
July 21, 2025 at 2:21 PM
Do you have a PhD (or equivalent) or will have one in the coming months (i.e. 2-3 months away from graduating)? Do you want to help build open-ended agents that help humans do humans things better, rather than replace them? We're hiring 1-2 Research Scientists! Check the 🧵👇
Reposted by Tom Everitt

digital-strategy.ec.europa.eu/en/policies/... The Code also has two other, separate Chapters (Copyright, Transparency). The Chapter I co-chaired (Safety & Security) is a compliance tool for the small number of frontier AI companies to whom the “Systemic Risk” obligations of the AI Act apply.
2/3
2/3
The General-Purpose AI Code of Practice
The Code of Practice helps industry comply with the AI Act legal obligations on safety, transparency and copyright of general-purpose AI models.
digital-strategy.ec.europa.eu
July 10, 2025 at 11:53 AM
digital-strategy.ec.europa.eu/en/policies/... The Code also has two other, separate Chapters (Copyright, Transparency). The Chapter I co-chaired (Safety & Security) is a compliance tool for the small number of frontier AI companies to whom the “Systemic Risk” obligations of the AI Act apply.
2/3
2/3
Reposted by Tom Everitt

As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420
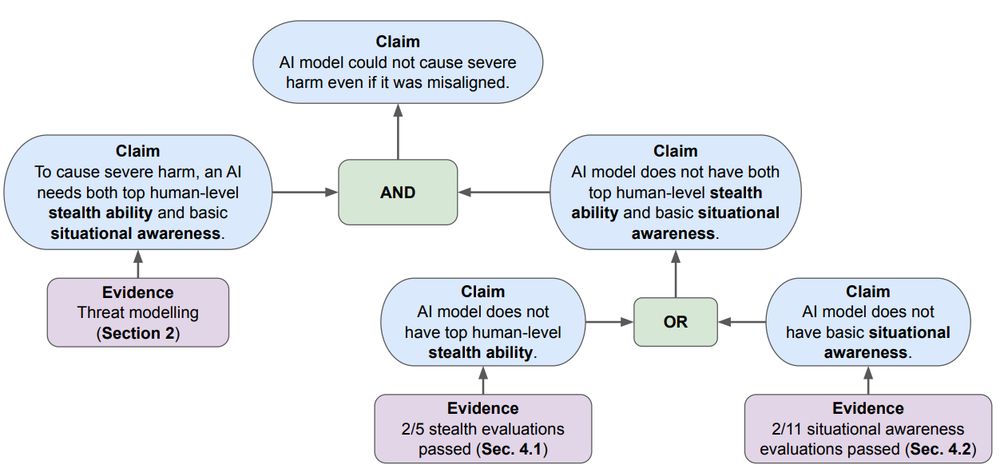
July 8, 2025 at 12:11 PM
As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended goals. Our paper "Evaluating Frontier Models for Stealth and Situational Awareness" assesses whether current models can scheme. arxiv.org/abs/2505.01420
Reposted by Tom Everitt

First position paper I ever wrote. "Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence" arxiv.org/abs/2506.23908 Background: I'd like LLMs to help me do math, but statistical learning seems inadequate to make this happen. What do you all think?

Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence
Sound deductive reasoning -- the ability to derive new knowledge from existing facts and rules -- is an indisputably desirable aspect of general intelligence. Despite the major advances of AI systems ...
arxiv.org
July 8, 2025 at 2:21 AM
First position paper I ever wrote. "Beyond Statistical Learning: Exact Learning Is Essential for General Intelligence" arxiv.org/abs/2506.23908 Background: I'd like LLMs to help me do math, but statistical learning seems inadequate to make this happen. What do you all think?
Reposted by Tom Everitt

Can frontier models hide secret information and reasoning in their outputs?
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵

July 4, 2025 at 3:34 PM
Can frontier models hide secret information and reasoning in their outputs?
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
We find early signs of steganographic capabilities in current frontier models, including Claude, GPT, and Gemini. 🧵
Thought provoking

1/ Can AI be conscious? My Behavioral & Brain Sciences target article on ‘Conscious AI and Biological Naturalism’ is now open for commentary proposals. Deadline is June 12. Take-home: real artificial consciousness is very unlikely along current trajectories. www.cambridge.org/core/journal...
Call for Commentary Proposals - Conscious artificial intelligence and biological
Call for Commentary Proposals - Conscious artificial intelligence and biological naturalism
www.cambridge.org
June 7, 2025 at 6:22 PM
Thought provoking
Are world models necessary to achieve human-level agents, or is there a model-free short-cut?
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
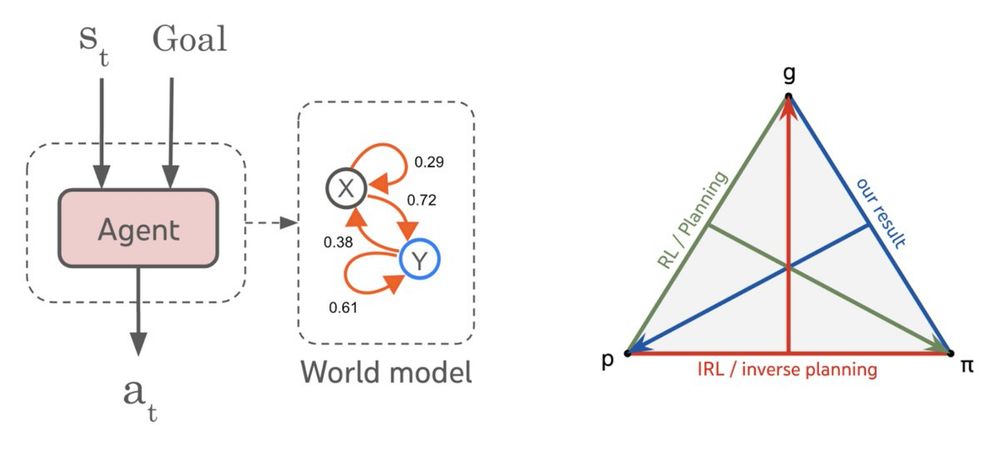
June 4, 2025 at 3:48 PM
Are world models necessary to achieve human-level agents, or is there a model-free short-cut?
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Great to see serious work on non-agentic AI. I think it's an underappreciated direction: better for safety, society, and human meaning.
LLMs show it's perfectly possible
LLMs show it's perfectly possible
Today marks a big milestone for me. I'm launching @law-zero.bsky.social, a nonprofit focusing on a new safe-by-design approach to AI that could both accelerate scientific discovery and provide a safeguard against the dangers of agentic AI.

Every frontier AI system should be grounded in a core commitment: to protect human joy and endeavour. Today, we launch LawZero, a nonprofit dedicated to advancing safe-by-design AI. lawzero.org
June 3, 2025 at 8:15 PM
Great to see serious work on non-agentic AI. I think it's an underappreciated direction: better for safety, society, and human meaning.
LLMs show it's perfectly possible
LLMs show it's perfectly possible
Reposted by Tom Everitt
When I realized how dangerous the current agency-driven AI trajectory could be for future generations, I knew I had to do all I could to make AI safer. I recently shared this personal experience, and outlined the scientific solution I envision @TEDTalks⤵️
www.ted.com/talks/yoshua...
www.ted.com/talks/yoshua...

The catastrophic risks of AI — and a safer path
Yoshua Bengio — the world's most-cited computer scientist and a "godfather" of artificial intelligence — is deadly concerned about the current trajectory of the technology. As AI models race toward fu...
www.ted.com
May 20, 2025 at 5:17 PM
When I realized how dangerous the current agency-driven AI trajectory could be for future generations, I knew I had to do all I could to make AI safer. I recently shared this personal experience, and outlined the scientific solution I envision @TEDTalks⤵️
www.ted.com/talks/yoshua...
www.ted.com/talks/yoshua...
Nice video about one of our recent papers, and some of its potential implications for AI agents
www.youtube.com/watch?app=de...
www.youtube.com/watch?app=de...

Why Don't AI Agents Work?
YouTube video by Mutual Information
www.youtube.com
May 13, 2025 at 1:36 PM
Nice video about one of our recent papers, and some of its potential implications for AI agents
www.youtube.com/watch?app=de...
www.youtube.com/watch?app=de...
Agency comes in degrees, and can vary along several dimensions: autonomy, efficacy, goal-complexity, and generality.
Great paper helping us understand the different possibilities
Great paper helping us understand the different possibilities

New paper with Iason Gabriel on "Characterizing AI agents" is out! 2025 is being called the year of AI agents, with overwhelming headlines about them every day. But we lack a shared vocabulary to distinguish their fundamental properties. Our paper aims to bridge this gap. A 🧵

May 7, 2025 at 7:56 PM
Agency comes in degrees, and can vary along several dimensions: autonomy, efficacy, goal-complexity, and generality.
Great paper helping us understand the different possibilities
Great paper helping us understand the different possibilities
METR task-time scaling critique:
"the 4-minute mark for GPT-4 is completely arbitrary; you could probably put together one reasonable collection of word counting ... tasks with average human time of 30 seconds and another ... of 20 minutes where GPT-4 would hit 50% accuracy on each"
"the 4-minute mark for GPT-4 is completely arbitrary; you could probably put together one reasonable collection of word counting ... tasks with average human time of 30 seconds and another ... of 20 minutes where GPT-4 would hit 50% accuracy on each"

Thus hugely popular graph about scaling and task length hardly makes any sense.
Ernest Davis and I deconstruct it at my newsletter: garymarcus.substack.com/p/the-latest...
Ernest Davis and I deconstruct it at my newsletter: garymarcus.substack.com/p/the-latest...

The latest AI scaling graph - and why it hardly makes sense
Just a because a graph is intriguing doesn’t mean that it means very much
garymarcus.substack.com
May 4, 2025 at 11:58 AM
METR task-time scaling critique:
"the 4-minute mark for GPT-4 is completely arbitrary; you could probably put together one reasonable collection of word counting ... tasks with average human time of 30 seconds and another ... of 20 minutes where GPT-4 would hit 50% accuracy on each"
"the 4-minute mark for GPT-4 is completely arbitrary; you could probably put together one reasonable collection of word counting ... tasks with average human time of 30 seconds and another ... of 20 minutes where GPT-4 would hit 50% accuracy on each"
Reposted by Tom Everitt

Generative AI tools used in art production should be evaluated by the broader art world of artists, art historians and curators, to integrate culturally-specific critique and to re-imagine these tools to suit the artists’ needs.
dl.acm.org/doi/full/10....
dl.acm.org/doi/full/10....

AI and Non-Western Art Worlds: Reimagining Critical AI Futures through Artistic Inquiry and Situated Dialogue | Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
dl.acm.org
May 1, 2025 at 6:19 PM
Generative AI tools used in art production should be evaluated by the broader art world of artists, art historians and curators, to integrate culturally-specific critique and to re-imagine these tools to suit the artists’ needs.
dl.acm.org/doi/full/10....
dl.acm.org/doi/full/10....
interesting argument about manufacturing: "[with] good enough software and hardware to create [good] humanoid robots ..., we will also be able to create more task-specific hardware ... that can do those roles cheaper, faster, and better."
perhaps the same is true for AI agents more generally?
perhaps the same is true for AI agents more generally?

Humanoid Robots in Manufacturing
Or, there's a reason we don't pull cars with mechanical horses
blog.spec.tech
April 30, 2025 at 9:06 AM
interesting argument about manufacturing: "[with] good enough software and hardware to create [good] humanoid robots ..., we will also be able to create more task-specific hardware ... that can do those roles cheaper, faster, and better."
perhaps the same is true for AI agents more generally?
perhaps the same is true for AI agents more generally?
Reposted by Tom Everitt

I'm very impressed with the Sentinel newsletter: by far the best aggregator of global news I've found
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!

April 29, 2025 at 1:00 PM
I'm very impressed with the Sentinel newsletter: by far the best aggregator of global news I've found
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
Reposted by Tom Everitt
Rival nations or companies sometimes choose to cooperate because some areas are protected zones of mutual interest—reducing shared risks without giving competitors an edge.
Our paper in FAccT '25: How geopolitical rivals can cooperate on AI safety research.
arxiv.org/abs/2504.12914
Our paper in FAccT '25: How geopolitical rivals can cooperate on AI safety research.
arxiv.org/abs/2504.12914
In Which Areas of Technical AI Safety Could Geopolitical Rivals Cooperate?
International cooperation is common in AI research, including between geopolitical rivals. While many experts advocate for greater international cooperation on AI safety to address shared global risks...
arxiv.org
April 23, 2025 at 1:48 PM
Rival nations or companies sometimes choose to cooperate because some areas are protected zones of mutual interest—reducing shared risks without giving competitors an edge.
Our paper in FAccT '25: How geopolitical rivals can cooperate on AI safety research.
arxiv.org/abs/2504.12914
Our paper in FAccT '25: How geopolitical rivals can cooperate on AI safety research.
arxiv.org/abs/2504.12914
Reposted by Tom Everitt

Excited that our paper "safety alignment should be made more than just a few tokens deep" was recognized as an #ICLR2025 Outstanding Paper!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
April 23, 2025 at 10:22 PM
Excited that our paper "safety alignment should be made more than just a few tokens deep" was recognized as an #ICLR2025 Outstanding Paper!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
April 17, 2025 at 9:44 AM
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
Reposted by Tom Everitt

The 1st blackbox AI control paper uses a mixture of ML monitoring and editing to detect or block harm from malicious agents. However, blackbox control is one point in a space that varies with capability. Our new paper tracks how control might change along this trajectory. 🧵
arxiv.org/abs/2504.05259
arxiv.org/abs/2504.05259

How to evaluate control measures for LLM agents? A trajectory from today to superintelligence
As LLM agents grow more capable of causing harm autonomously, AI developers will rely on increasingly sophisticated control measures to prevent possibly misaligned agents from causing harm. AI develop...
arxiv.org
April 14, 2025 at 5:32 PM
The 1st blackbox AI control paper uses a mixture of ML monitoring and editing to detect or block harm from malicious agents. However, blackbox control is one point in a space that varies with capability. Our new paper tracks how control might change along this trajectory. 🧵
arxiv.org/abs/2504.05259
arxiv.org/abs/2504.05259
Causality can help with AI safety in so many ways!

Theories of Impact for Causality in AI Safety — LessWrong
Thanks to Jonathan Richens and Tom Everitt for discussions about this post. …
www.lesswrong.com
April 12, 2025 at 7:33 PM
Causality can help with AI safety in so many ways!
Reposted by Tom Everitt
Super excited this giant paper outlining our technical approach to AGI safety and security is finally out!
No time to read 145 pages? Check out the 10 page extended abstract at the beginning of the paper
No time to read 145 pages? Check out the 10 page extended abstract at the beginning of the paper

April 4, 2025 at 2:27 PM
Super excited this giant paper outlining our technical approach to AGI safety and security is finally out!
No time to read 145 pages? Check out the 10 page extended abstract at the beginning of the paper
No time to read 145 pages? Check out the 10 page extended abstract at the beginning of the paper
Reposted by Tom Everitt

𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
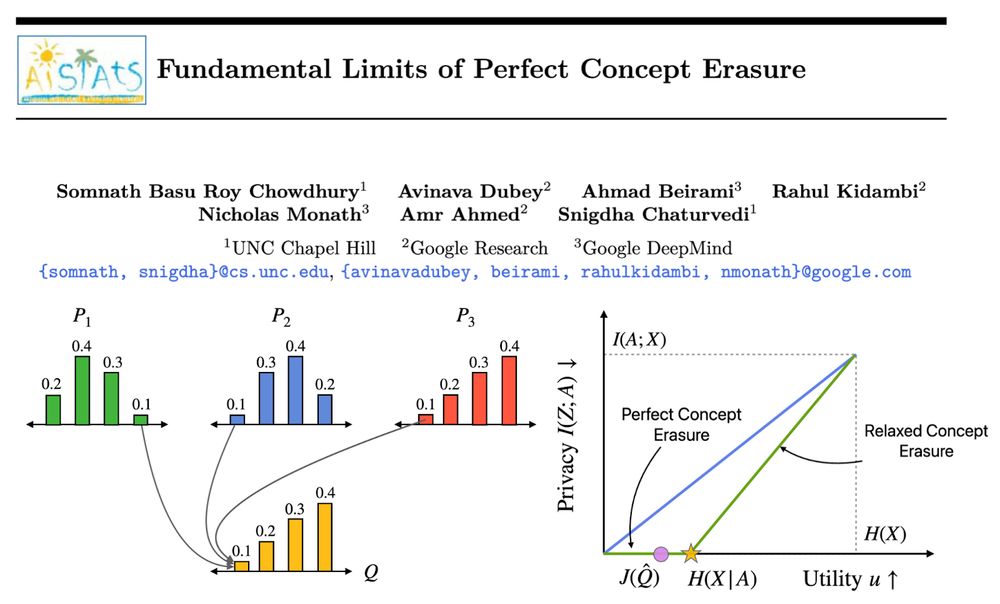
April 2, 2025 at 4:03 PM
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵