



Atoosa Kasirzadeh
@atoosakz.bsky.social
societal impacts of AI | assistant professor of philosophy & software and societal systems at Carnegie Mellon University & AI2050 Schmidt Sciences early-career fellow | system engineering + AI + philosophy | https://kasirzadeh.org/
Reposted by Atoosa Kasirzadeh

🚨New paper: Reward Models (RMs) are used to align LLMs, but can they be steered toward user-specific value/style preferences?
With EVALUESTEER, we find even the best RMs we tested exhibit their own value/style biases, and are unable to align with a user >25% of the time. 🧵
With EVALUESTEER, we find even the best RMs we tested exhibit their own value/style biases, and are unable to align with a user >25% of the time. 🧵

October 14, 2025 at 3:59 PM
🚨New paper: Reward Models (RMs) are used to align LLMs, but can they be steered toward user-specific value/style preferences?
With EVALUESTEER, we find even the best RMs we tested exhibit their own value/style biases, and are unable to align with a user >25% of the time. 🧵
With EVALUESTEER, we find even the best RMs we tested exhibit their own value/style biases, and are unable to align with a user >25% of the time. 🧵
Reposted by Atoosa Kasirzadeh

If anyone needs me I will be in the museum, lying down next to the bog bodies.

October 13, 2025 at 5:58 PM
If anyone needs me I will be in the museum, lying down next to the bog bodies.
Reposted by Atoosa Kasirzadeh

Great work led by @andyliu.bsky.social and collaborators:
@kghate.bsky.social, @monadiab77.bsky.social, @daniel-fried.bsky.social, @atoosakz.bsky.social
Preprint: www.arxiv.org/abs/2509.25369
@kghate.bsky.social, @monadiab77.bsky.social, @daniel-fried.bsky.social, @atoosakz.bsky.social
Preprint: www.arxiv.org/abs/2509.25369

Generative Value Conflicts Reveal LLM Priorities
Past work seeks to align large language model (LLM)-based assistants with a target set of values, but such assistants are frequently forced to make tradeoffs between values when deployed. In response ...
www.arxiv.org
October 2, 2025 at 6:37 PM
Great work led by @andyliu.bsky.social and collaborators:
@kghate.bsky.social, @monadiab77.bsky.social, @daniel-fried.bsky.social, @atoosakz.bsky.social
Preprint: www.arxiv.org/abs/2509.25369
@kghate.bsky.social, @monadiab77.bsky.social, @daniel-fried.bsky.social, @atoosakz.bsky.social
Preprint: www.arxiv.org/abs/2509.25369
Reposted by Atoosa Kasirzadeh

🚨New Paper: LLM developers aim to align models with values like helpfulness or harmlessness. But when these conflict, which values do models choose to support? We introduce ConflictScope, a fully-automated evaluation pipeline that reveals how models rank values under conflict.
(📷 xkcd)
(📷 xkcd)

October 2, 2025 at 4:04 PM
🚨New Paper: LLM developers aim to align models with values like helpfulness or harmlessness. But when these conflict, which values do models choose to support? We introduce ConflictScope, a fully-automated evaluation pipeline that reveals how models rank values under conflict.
(📷 xkcd)
(📷 xkcd)
Reposted by Atoosa Kasirzadeh

If you read one review of If Anyone Builds It Everyone Dies make it @sigalsamuel.bsky.social 's about competing #AI worldviews
"It was hard to seriously entertain both [doomer and AI-as-normal tech] views at the same time."
www.vox.com/future-perfe...
"It was hard to seriously entertain both [doomer and AI-as-normal tech] views at the same time."
www.vox.com/future-perfe...

The AI doomers are not making an argument. They’re selling a worldview.
How rational is Eliezer Yudkowsky’s prophecy?
www.vox.com
September 17, 2025 at 3:31 PM
If you read one review of If Anyone Builds It Everyone Dies make it @sigalsamuel.bsky.social 's about competing #AI worldviews
"It was hard to seriously entertain both [doomer and AI-as-normal tech] views at the same time."
www.vox.com/future-perfe...
"It was hard to seriously entertain both [doomer and AI-as-normal tech] views at the same time."
www.vox.com/future-perfe...
Reposted by Atoosa Kasirzadeh

I had a very trippy experience reading the new Eliezer Yudkowsky book, IF ANYONE BUILDS IT, EVERYONE DIES.
I agree with the basic idea that the current speed & trajectory of AI progress is incredibly dangerous!
But I don't buy his general worldview. Here's why:
www.vox.com/future-perfe...
I agree with the basic idea that the current speed & trajectory of AI progress is incredibly dangerous!
But I don't buy his general worldview. Here's why:
www.vox.com/future-perfe...

“AI will kill everyone” is not an argument. It’s a worldview.
How rational is Eliezer Yudkowsky’s prophecy?
www.vox.com
September 18, 2025 at 3:24 PM
I had a very trippy experience reading the new Eliezer Yudkowsky book, IF ANYONE BUILDS IT, EVERYONE DIES.
I agree with the basic idea that the current speed & trajectory of AI progress is incredibly dangerous!
But I don't buy his general worldview. Here's why:
www.vox.com/future-perfe...
I agree with the basic idea that the current speed & trajectory of AI progress is incredibly dangerous!
But I don't buy his general worldview. Here's why:
www.vox.com/future-perfe...
Reposted by Atoosa Kasirzadeh

Very happy to announce brilliant new paper on AI by the wonderful @atoosakz.bsky.social , Phillip Hacker, and er, me, on systemic risk and how it is confusingly differently interpreted through the EU AIA, the DSA and its origin, financial regulation.
Paper at https://arxiv.org/pdf/2509.17878
Paper at https://arxiv.org/pdf/2509.17878

September 23, 2025 at 4:21 PM
Very happy to announce brilliant new paper on AI by the wonderful @atoosakz.bsky.social , Phillip Hacker, and er, me, on systemic risk and how it is confusingly differently interpreted through the EU AIA, the DSA and its origin, financial regulation.
Paper at https://arxiv.org/pdf/2509.17878
Paper at https://arxiv.org/pdf/2509.17878
Reposted by Atoosa Kasirzadeh
Kasirzadeh also has a really insightful, heartbreaking thread about what "normal" hides here: bsky.app/profile/atoo...
Normal isn't a fact; it's a perception built from repetition & power. My brother can call a night of missile fire normal simply because he's used to it.To an outsider, the scene is clearly abnormal. Judgements of normality rest on thin, shifting ground. History shows how quickly baselines move. 5/n
September 17, 2025 at 9:30 PM
Kasirzadeh also has a really insightful, heartbreaking thread about what "normal" hides here: bsky.app/profile/atoo...
Reposted by Atoosa Kasirzadeh
Anyway, big fan of the 3rd option Sigal presents, @atoosakz.bsky.social 's warning of "gradual accumulation of smaller, seemingly non-existential, AI risks" until catastrophe.
A warning that suggests AI safetyists should take AI ethics & sociology much more seriously! arxiv.org/pdf/2401.07836
A warning that suggests AI safetyists should take AI ethics & sociology much more seriously! arxiv.org/pdf/2401.07836
arxiv.org
September 17, 2025 at 3:39 PM
Anyway, big fan of the 3rd option Sigal presents, @atoosakz.bsky.social 's warning of "gradual accumulation of smaller, seemingly non-existential, AI risks" until catastrophe.
A warning that suggests AI safetyists should take AI ethics & sociology much more seriously! arxiv.org/pdf/2401.07836
A warning that suggests AI safetyists should take AI ethics & sociology much more seriously! arxiv.org/pdf/2401.07836
How good are the current AI agents for scientific discovery? We have answers in our new paper: lnkd.in/dxzmZXpR!
We look at 4 ways AI scientists can go wrong; design experiments to show the manifestation of these failures in 2 open source AI scientists; and recommend detection strategies.
We look at 4 ways AI scientists can go wrong; design experiments to show the manifestation of these failures in 2 open source AI scientists; and recommend detection strategies.

September 11, 2025 at 8:33 PM
How good are the current AI agents for scientific discovery? We have answers in our new paper: lnkd.in/dxzmZXpR!
We look at 4 ways AI scientists can go wrong; design experiments to show the manifestation of these failures in 2 open source AI scientists; and recommend detection strategies.
We look at 4 ways AI scientists can go wrong; design experiments to show the manifestation of these failures in 2 open source AI scientists; and recommend detection strategies.
🔊📢 Call for paper is now open (iaseai.org/iaseai26)! I’m thrilled to share that I will once again be serving as Program Co-Chair for International Association for Safe & Ethical AI Conference, this time for the 2026 edition along with the Co-Chair Jaime Fernández Fisac.

IASEAI'26
Building a Global Movement for Safe and Ethical AI
iaseai.org
August 19, 2025 at 10:18 AM
🔊📢 Call for paper is now open (iaseai.org/iaseai26)! I’m thrilled to share that I will once again be serving as Program Co-Chair for International Association for Safe & Ethical AI Conference, this time for the 2026 edition along with the Co-Chair Jaime Fernández Fisac.
Reposted by Atoosa Kasirzadeh

Introducing: Full-Stack Alignment 🥞
A research program dedicated to co-aligning AI systems *and* institutions with what people value.
It's the most ambitious project I've ever undertaken.
Here's what we're doing: 🧵
A research program dedicated to co-aligning AI systems *and* institutions with what people value.
It's the most ambitious project I've ever undertaken.
Here's what we're doing: 🧵
July 11, 2025 at 6:56 PM
Introducing: Full-Stack Alignment 🥞
A research program dedicated to co-aligning AI systems *and* institutions with what people value.
It's the most ambitious project I've ever undertaken.
Here's what we're doing: 🧵
A research program dedicated to co-aligning AI systems *and* institutions with what people value.
It's the most ambitious project I've ever undertaken.
Here's what we're doing: 🧵
At hashtag#AIforGood Summit 2025: ‘AI agents’ is mentioned almost every panel, from law and governance to the developer community; yet the term remains so opaque. A plug in to our paper with Iason Gabriel which offers one of the clearest definition I’ve seen: arxiv.org/pdf/2504.21848
arxiv.org
July 10, 2025 at 9:11 AM
At hashtag#AIforGood Summit 2025: ‘AI agents’ is mentioned almost every panel, from law and governance to the developer community; yet the term remains so opaque. A plug in to our paper with Iason Gabriel which offers one of the clearest definition I’ve seen: arxiv.org/pdf/2504.21848
I was planning to launch my substack on "Human, life, AI, and future" in a few months, with something very different. But life doesn’t always care about our timelines. Events erupt. Emotions build. And suddenly, waiting feels like avoidance. My first post: atoosatopia.substack.com/p/valid-and-...

June 16, 2025 at 10:33 PM
I was planning to launch my substack on "Human, life, AI, and future" in a few months, with something very different. But life doesn’t always care about our timelines. Events erupt. Emotions build. And suddenly, waiting feels like avoidance. My first post: atoosatopia.substack.com/p/valid-and-...
Ever since I first heard the slogan “AI as normal technology,” I’ve felt uneasy. Tonight that unease crystallised. In this 🧵 I unpack what normal hides and why the metaphor may ultimately fail to capture AI’s abnormal impacts on human life and societies. 1/n
June 15, 2025 at 5:48 AM
Ever since I first heard the slogan “AI as normal technology,” I’ve felt uneasy. Tonight that unease crystallised. In this 🧵 I unpack what normal hides and why the metaphor may ultimately fail to capture AI’s abnormal impacts on human life and societies. 1/n
What can policy makers learn from “AI safety for everyone” (Read here: www.nature.com/articles/s42... ; joint work with @gbalint.bsky.social )? I wrote about some policy lessons for Tech Policy Press.
May 23, 2025 at 8:32 PM
What can policy makers learn from “AI safety for everyone” (Read here: www.nature.com/articles/s42... ; joint work with @gbalint.bsky.social )? I wrote about some policy lessons for Tech Policy Press.
Congrats, Dr. Alex, for writing a fantastic dissertation! I had the pleasure of co-supervising Alex during my time at the U of Edinburgh 2022-2024! To have a glimpse at Alex's research read this amazing paper: link.springer.com/article/10.1...
May 21, 2025 at 9:33 PM
Congrats, Dr. Alex, for writing a fantastic dissertation! I had the pleasure of co-supervising Alex during my time at the U of Edinburgh 2022-2024! To have a glimpse at Alex's research read this amazing paper: link.springer.com/article/10.1...
This is a really good spicy debate and we need more spicy debates of this kind please!

My debate at the @noemamag.com anniversary is now online - it’s a spicy one! (albeit not by philosophy standards. No fireplace pokers were used).

Kara Swisher Hosts Fierce Debate On Future Of AI With Google VP, AI Ethicist
YouTube video by Noema Magazine
www.youtube.com
May 19, 2025 at 5:42 PM
This is a really good spicy debate and we need more spicy debates of this kind please!
I've learned so much from Tom's unbeatable papers about agency, in particular his technically and philosophically rich account of agency from a causal perspective: www.alignmentforum.org/posts/Qi77Tu...

Agency comes in degrees, and can vary along several dimensions: autonomy, efficacy, goal-complexity, and generality.
Great paper helping us understand the different possibilities
Great paper helping us understand the different possibilities
New paper with Iason Gabriel on "Characterizing AI agents" is out! 2025 is being called the year of AI agents, with overwhelming headlines about them every day. But we lack a shared vocabulary to distinguish their fundamental properties. Our paper aims to bridge this gap. A 🧵
May 9, 2025 at 3:53 AM
I've learned so much from Tom's unbeatable papers about agency, in particular his technically and philosophically rich account of agency from a causal perspective: www.alignmentforum.org/posts/Qi77Tu...
New paper with Iason Gabriel on "Characterizing AI agents" is out! 2025 is being called the year of AI agents, with overwhelming headlines about them every day. But we lack a shared vocabulary to distinguish their fundamental properties. Our paper aims to bridge this gap. A 🧵

May 2, 2025 at 5:21 PM
New paper with Iason Gabriel on "Characterizing AI agents" is out! 2025 is being called the year of AI agents, with overwhelming headlines about them every day. But we lack a shared vocabulary to distinguish their fundamental properties. Our paper aims to bridge this gap. A 🧵
Reposted by Atoosa Kasirzadeh

Our paper "AI safety for everyone" with Balint Gyevnar is out at Nature Machine Intelligence: www.nature.com/articles/s42...
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
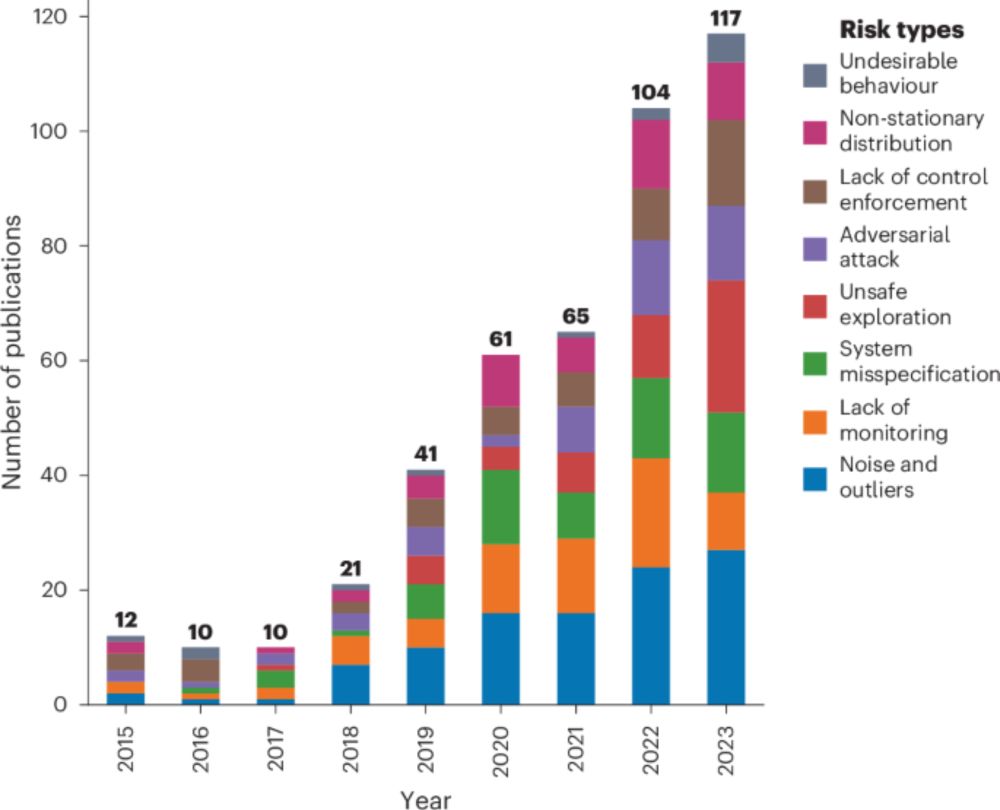
AI safety for everyone - Nature Machine Intelligence
A systematic review of peer-reviewed AI safety research reveals extensive work on practical and immediate concerns. The findings advocate for an inclusive approach to AI safety that embraces diverse m...
www.nature.com
April 23, 2025 at 2:00 PM
Our paper "AI safety for everyone" with Balint Gyevnar is out at Nature Machine Intelligence: www.nature.com/articles/s42...
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
AI safety for everyone - Nature Machine Intelligence
A systematic review of peer-reviewed AI safety research reveals extensive work on practical and immediate concerns. The findings advocate for an inclusive approach to AI safety that embraces diverse m...
www.nature.com
April 17, 2025 at 2:14 PM
Our paper "AI safety for everyone" with Balint Gyevnar is out at Nature Machine Intelligence: www.nature.com/articles/s42...
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
We challenge the narrative that AI safety is primarily about minimizing existential risks from AI. Why does this matter?
Reposted by Atoosa Kasirzadeh

Panel 1: Regulating AI in a Time of Democratic Upheaval starts in approximately 5 minutes.
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms

April 10, 2025 at 1:44 PM
Panel 1: Regulating AI in a Time of Democratic Upheaval starts in approximately 5 minutes.
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
Reposted by Atoosa Kasirzadeh
On 4/10 and 4/11, we're hosting our symposium "AI and Democratic Freedoms." Excited to have panelists @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, & Deirdre K. Mulligan join moderator
@shaynelongpre.bsky.social to kick it off. RSVP: www.eventbrite.com/e/artificial...
@shaynelongpre.bsky.social to kick it off. RSVP: www.eventbrite.com/e/artificial...


April 2, 2025 at 7:58 PM
On 4/10 and 4/11, we're hosting our symposium "AI and Democratic Freedoms." Excited to have panelists @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, & Deirdre K. Mulligan join moderator
@shaynelongpre.bsky.social to kick it off. RSVP: www.eventbrite.com/e/artificial...
@shaynelongpre.bsky.social to kick it off. RSVP: www.eventbrite.com/e/artificial...
Out in Philosophical Studies. A 🧵: Read here: link.springer.com/article/10.1...
Most AI x-risk discussions focus on a cataclysmic moment—a decisive superintelligent takeover. But what if existential risk doesn’t arrive like a bomb, but seeps in like a leak?
Most AI x-risk discussions focus on a cataclysmic moment—a decisive superintelligent takeover. But what if existential risk doesn’t arrive like a bomb, but seeps in like a leak?
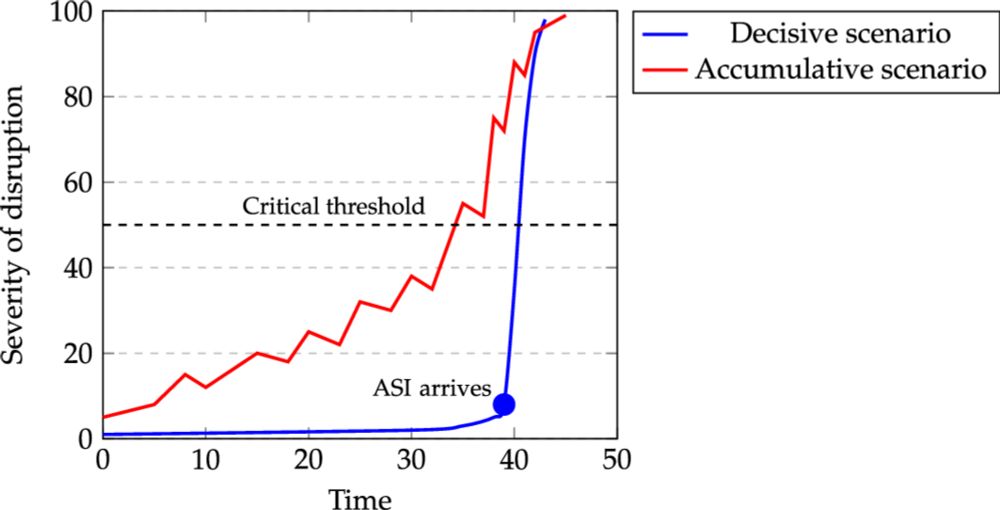
Two types of AI existential risk: decisive and accumulative - Philosophical Studies
The conventional discourse on existential risks (x-risks) from AI typically focuses on abrupt, dire events caused by advanced AI systems, particularly those that might achieve or surpass human-level i...
link.springer.com
March 30, 2025 at 10:43 PM
Out in Philosophical Studies. A 🧵: Read here: link.springer.com/article/10.1...
Most AI x-risk discussions focus on a cataclysmic moment—a decisive superintelligent takeover. But what if existential risk doesn’t arrive like a bomb, but seeps in like a leak?
Most AI x-risk discussions focus on a cataclysmic moment—a decisive superintelligent takeover. But what if existential risk doesn’t arrive like a bomb, but seeps in like a leak?