


Tom Everitt
@tom4everitt.bsky.social
AGI safety researcher at Google DeepMind, leading causalincentives.com
Personal website: tomeveritt.se
Personal website: tomeveritt.se
Causality. In previous work we showed a causal world model is needed for robustness. It turns out you don’t need as much causal knowledge of the environment for task generalization. There is a causal hierarchy, but for agency and agent capabilities, rather than inference!

June 4, 2025 at 3:51 PM
Causality. In previous work we showed a causal world model is needed for robustness. It turns out you don’t need as much causal knowledge of the environment for task generalization. There is a causal hierarchy, but for agency and agent capabilities, rather than inference!
Emergent capabilities. To minimize training loss across many goals, agents must learn a world model, which can solve tasks the agent was not explicitly trained on. Simple goal-directedness gives rise to many capabilities (social cognition, reasoning about uncertainty, intent…).

June 4, 2025 at 3:51 PM
Emergent capabilities. To minimize training loss across many goals, agents must learn a world model, which can solve tasks the agent was not explicitly trained on. Simple goal-directedness gives rise to many capabilities (social cognition, reasoning about uncertainty, intent…).
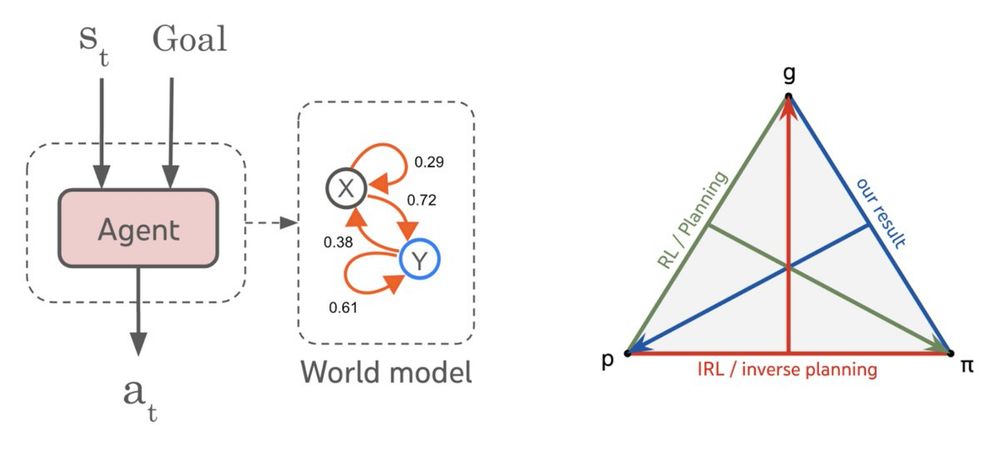
Extracting world knowledge from agents. We derive algorithms that recover a world model given the agent’s policy and goal (policy + goal -> world model). These algorithms complete the triptych of planning (world model + goal -> policy) and IRL (world model + policy -> goal).

June 4, 2025 at 3:51 PM
Extracting world knowledge from agents. We derive algorithms that recover a world model given the agent’s policy and goal (policy + goal -> world model). These algorithms complete the triptych of planning (world model + goal -> policy) and IRL (world model + policy -> goal).
Specifically, we show it’s possible to recover a bounded error approximation of the environment transition function from any goal-conditional policy that satisfies a regret bound across a wide enough set of simple goals, like steering the environment into a desired state.

June 4, 2025 at 3:49 PM
Specifically, we show it’s possible to recover a bounded error approximation of the environment transition function from any goal-conditional policy that satisfies a regret bound across a wide enough set of simple goals, like steering the environment into a desired state.
Turns out there’s a neat answer to this question. We prove that any agent capable of generalizing to a broad range of simple goal-directed tasks must have learned a predictive model capable of simulating its environment. And this model can always be recovered from the agent.

June 4, 2025 at 3:48 PM
Turns out there’s a neat answer to this question. We prove that any agent capable of generalizing to a broad range of simple goal-directed tasks must have learned a predictive model capable of simulating its environment. And this model can always be recovered from the agent.
Are world models necessary to achieve human-level agents, or is there a model-free short-cut?
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
June 4, 2025 at 3:48 PM
Are world models necessary to achieve human-level agents, or is there a model-free short-cut?
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Our new #ICML2025 paper tackles this question from first principles, and finds a surprising answer, agents _are_ world models… 🧵
arxiv.org/abs/2506.01622
Our definition also predicts other indicators of goal-directedness, such as propensity to rebuild a fallen tower, and persistence at Progress Ratio Tasks. (In PRTs, you can quit at any time, and face diminishing returns. They are commonly used to assess human goal-directedness.)


April 17, 2025 at 9:48 AM
Our definition also predicts other indicators of goal-directedness, such as propensity to rebuild a fallen tower, and persistence at Progress Ratio Tasks. (In PRTs, you can quit at any time, and face diminishing returns. They are commonly used to assess human goal-directedness.)
Notably, goal-directedness is fairly consistent across tasks, indicating that it may be an intrinsic property of models. Newer models are often more goal-directed, perhaps due to better RL post-training

April 17, 2025 at 9:47 AM
Notably, goal-directedness is fairly consistent across tasks, indicating that it may be an intrinsic property of models. Newer models are often more goal-directed, perhaps due to better RL post-training
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...

April 17, 2025 at 9:44 AM
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
Process based supervision done right, and with pretty CIDs to illustrate :)

January 23, 2025 at 8:33 PM
Process based supervision done right, and with pretty CIDs to illustrate :)
Formally, we measure the predictive power of the hypothesis that a policy is optimising a utility function, using the ‘soft optimal’ behaviour model in causal model or MDP.

December 14, 2024 at 9:08 PM
Formally, we measure the predictive power of the hypothesis that a policy is optimising a utility function, using the ‘soft optimal’ behaviour model in causal model or MDP.
How can we measure goal-directedness? Our idea: by considering how well the goal predicts the behaviour. For example, the behaviour of a mouse that always seeks out a piece of cheese is well-predicted by the cheese goal.

December 14, 2024 at 9:07 PM
How can we measure goal-directedness? Our idea: by considering how well the goal predicts the behaviour. For example, the behaviour of a mouse that always seeks out a piece of cheese is well-predicted by the cheese goal.
🔦 @NeurIPS2024 spotlight paper we’re presenting today. Making AI systems more agentic is a hot research topic. But powerful agents bring worries about misalignment and loss of control. Can we measure how agentic an AI system is? 🧵

December 14, 2024 at 9:05 PM
🔦 @NeurIPS2024 spotlight paper we’re presenting today. Making AI systems more agentic is a hot research topic. But powerful agents bring worries about misalignment and loss of control. Can we measure how agentic an AI system is? 🧵
On the philosophical side, but both insightful and accessible

November 27, 2024 at 7:14 PM
On the philosophical side, but both insightful and accessible