




Miao Zhang
@mzhang89.bsky.social
Post-doc in phonetics at the Department of Computational Linguistics, University of Zurich. Interested in the phonetics-phonology and phonetics-prosody interfaces.
Reposted by Miao Zhang

#statstab #465 How to embrace variation and accept
uncertainty in linguistic and
psycholinguistic data analysis
Thoughts: An accessible paper on communicating your results with nuance.
#bayes #bayesian #uncertainty #error #bias #guide #tutorial
sites.stat.columbia.edu/gelman/resea...
uncertainty in linguistic and
psycholinguistic data analysis
Thoughts: An accessible paper on communicating your results with nuance.
#bayes #bayesian #uncertainty #error #bias #guide #tutorial
sites.stat.columbia.edu/gelman/resea...
sites.stat.columbia.edu
November 21, 2025 at 5:19 PM
#statstab #465 How to embrace variation and accept
uncertainty in linguistic and
psycholinguistic data analysis
Thoughts: An accessible paper on communicating your results with nuance.
#bayes #bayesian #uncertainty #error #bias #guide #tutorial
sites.stat.columbia.edu/gelman/resea...
uncertainty in linguistic and
psycholinguistic data analysis
Thoughts: An accessible paper on communicating your results with nuance.
#bayes #bayesian #uncertainty #error #bias #guide #tutorial
sites.stat.columbia.edu/gelman/resea...
Reposted by Miao Zhang

🎉 Finally out in Journal of Phonetics, tutorial with @paulbuerkner.com
📖 "Bayesian beta regressions with brms in R: A tutorial for phoneticians"
Accepted manuscript here: doi.org/10.31219/osf...
Repo: github.com/stefanocoret...
Publisher link: www.sciencedirect.com/science/arti...
📖 "Bayesian beta regressions with brms in R: A tutorial for phoneticians"
Accepted manuscript here: doi.org/10.31219/osf...
Repo: github.com/stefanocoret...
Publisher link: www.sciencedirect.com/science/arti...

a close up of a rat looking at the camera with the word drunken written in the corner
ALT: a close up of a rat looking at the camera with the word drunken written in the corner
media.tenor.com
November 15, 2025 at 3:21 PM
🎉 Finally out in Journal of Phonetics, tutorial with @paulbuerkner.com
📖 "Bayesian beta regressions with brms in R: A tutorial for phoneticians"
Accepted manuscript here: doi.org/10.31219/osf...
Repo: github.com/stefanocoret...
Publisher link: www.sciencedirect.com/science/arti...
📖 "Bayesian beta regressions with brms in R: A tutorial for phoneticians"
Accepted manuscript here: doi.org/10.31219/osf...
Repo: github.com/stefanocoret...
Publisher link: www.sciencedirect.com/science/arti...
Reposted by Miao Zhang

Excited to share our new preprint with @mzhang89.bsky.social : “A crosslinguistic corpus phonetic analysis of intrinsic vowel duration” 🎉
🔗 osf.io/preprints/ps...
🔗 osf.io/preprints/ps...
OSF
osf.io
October 2, 2025 at 4:46 PM
Excited to share our new preprint with @mzhang89.bsky.social : “A crosslinguistic corpus phonetic analysis of intrinsic vowel duration” 🎉
🔗 osf.io/preprints/ps...
🔗 osf.io/preprints/ps...
Reposted by Miao Zhang

Bring back the iPod classic and the 3.5mm headphone jack

i don't want to hear your most boomer complaint. what's your most millennial complaint?
September 20, 2025 at 10:51 AM
Bring back the iPod classic and the 3.5mm headphone jack
Reposted by Miao Zhang
Simon Wood, the GOAT of generalized additive models & creator of the mgcv #rstats package, has an Annual Review of Statistics essay on GAMs, available open access #statssky #mlsky
www.annualreviews.org/content/jour...
www.annualreviews.org/content/jour...

September 10, 2025 at 2:15 AM
Simon Wood, the GOAT of generalized additive models & creator of the mgcv #rstats package, has an Annual Review of Statistics essay on GAMs, available open access #statssky #mlsky
www.annualreviews.org/content/jour...
www.annualreviews.org/content/jour...
I feel things corrected by Grammarly feel less AI-generated than those corrected by general AI tools (ChatGPT-like). Is it just my illusion?
September 5, 2025 at 1:58 PM
I feel things corrected by Grammarly feel less AI-generated than those corrected by general AI tools (ChatGPT-like). Is it just my illusion?
Reposted by Miao Zhang
🗣️Mozilla Common Voice users!🗣️
Important notice: the client ID does not always correspond to a single speaker ID! Every so often, a single client ID contains more than one speaker’s voice. Our #Interspeech2025 paper examines the extent of this problem and proposes a solution
Important notice: the client ID does not always correspond to a single speaker ID! Every so often, a single client ID contains more than one speaker’s voice. Our #Interspeech2025 paper examines the extent of this problem and proposes a solution

August 29, 2025 at 10:25 AM
🗣️Mozilla Common Voice users!🗣️
Important notice: the client ID does not always correspond to a single speaker ID! Every so often, a single client ID contains more than one speaker’s voice. Our #Interspeech2025 paper examines the extent of this problem and proposes a solution
Important notice: the client ID does not always correspond to a single speaker ID! Every so often, a single client ID contains more than one speaker’s voice. Our #Interspeech2025 paper examines the extent of this problem and proposes a solution
Reposted by Miao Zhang
✅Similarity scores: huggingface.co/datasets/pac...
📄Paper: www.isca-archive.org/interspeech_...
💻Code: github.com/pacscilab/CV...
💫This was joint work with @mzhang89.bsky.social, Aref Farhadipour, Annie Baker, Jiachen Ma, and Bogdan Pricop
📄Paper: www.isca-archive.org/interspeech_...
💻Code: github.com/pacscilab/CV...
💫This was joint work with @mzhang89.bsky.social, Aref Farhadipour, Annie Baker, Jiachen Ma, and Bogdan Pricop

pacscilab/VoxCommunis at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 29, 2025 at 10:25 AM
✅Similarity scores: huggingface.co/datasets/pac...
📄Paper: www.isca-archive.org/interspeech_...
💻Code: github.com/pacscilab/CV...
💫This was joint work with @mzhang89.bsky.social, Aref Farhadipour, Annie Baker, Jiachen Ma, and Bogdan Pricop
📄Paper: www.isca-archive.org/interspeech_...
💻Code: github.com/pacscilab/CV...
💫This was joint work with @mzhang89.bsky.social, Aref Farhadipour, Annie Baker, Jiachen Ma, and Bogdan Pricop
Reposted by Miao Zhang

LabPhon 20 will be held in Montréal June 25–28, 2026, on the theme “Looking Back and Looking Forward,” to reflect on the field’s foundational contributions while highlighting new directions in laboratory phonology. Abstract submission deadline: Dec 1, 2025 labphon.org/labphon20/home
Home | Labphon
labphon.org
August 26, 2025 at 1:32 PM
LabPhon 20 will be held in Montréal June 25–28, 2026, on the theme “Looking Back and Looking Forward,” to reflect on the field’s foundational contributions while highlighting new directions in laboratory phonology. Abstract submission deadline: Dec 1, 2025 labphon.org/labphon20/home
The similarity score file can be found in our VoxCommunis huggingface repo: huggingface.co/datasets/pac.... You can also see the scripts we used to obtain the similarity scores here: github.com/areffarhadi/...
August 21, 2025 at 10:50 AM
The similarity score file can be found in our VoxCommunis huggingface repo: huggingface.co/datasets/pac.... You can also see the scripts we used to obtain the similarity scores here: github.com/areffarhadi/...
We presented our attempt to clean the Common Voice client ID for phonetic analysis at Interspeech 2025. Please check the poster here: www.researchgate.net/publication/.... The paper is also available at: www.isca-archive.org/interspeech_...

(PDF) Quantifying and Reducing Speaker Heterogeneity within the Common Voice Corpus for Phonetic Analysis
PDF | With its crosslinguistic and cross-speaker diversity, the Mozilla Common Voice Corpus (CV) has been a valuable resource for multilingual speech... | Find, read and cite all the research you need...
www.researchgate.net
August 21, 2025 at 10:33 AM
We presented our attempt to clean the Common Voice client ID for phonetic analysis at Interspeech 2025. Please check the poster here: www.researchgate.net/publication/.... The paper is also available at: www.isca-archive.org/interspeech_...
Reposted by Miao Zhang

Introducing the tidynorm package! It's got convenience functions for applying your favorite vowel normalization methods to point measures, formant tracks, and DCT coefficients in a tidyverse workflow, as well as a flexible framework for defining your own normalization methods!
Introducing tidynorm – Væl Space
Here’s a brief introduction to the new tidynorm package.
jofrhwld.github.io
June 16, 2025 at 3:35 PM
Introducing the tidynorm package! It's got convenience functions for applying your favorite vowel normalization methods to point measures, formant tracks, and DCT coefficients in a tidyverse workflow, as well as a flexible framework for defining your own normalization methods!
Reposted by Miao Zhang

New insights into German #prosody! How do speakers & listeners distinguish utterance-medial vs. utterance-final #intonation boundaries in #German? Subtle differences in intonation, particularly in the rhyme's f0, are key cues for listeners. #LabPhon #openaccess #kinematics doi.org/10.16995/lab...
How final is final: The production and perception of utterance-medial and utterance-final boundaries
We examine the production and perception of two types of phrase-final prosodic boundaries, specifically, utterance-medial and utterance-final intonation phrase (IP) boundaries in German. These two typ...
www.journal-labphon.org
June 14, 2025 at 3:17 AM
New insights into German #prosody! How do speakers & listeners distinguish utterance-medial vs. utterance-final #intonation boundaries in #German? Subtle differences in intonation, particularly in the rhyme's f0, are key cues for listeners. #LabPhon #openaccess #kinematics doi.org/10.16995/lab...
When people talk about neutralization in phonology, it's very important to check some phonetic data. It's very probable that we either didn't perceive it or overinterpreted some variance as non-natives.
June 10, 2025 at 8:47 PM
When people talk about neutralization in phonology, it's very important to check some phonetic data. It's very probable that we either didn't perceive it or overinterpreted some variance as non-natives.
Reposted by Miao Zhang

ggplot2 is turning 18! 🎂
For nearly two decades, it’s helped data scientists turn complex data into clear, beautiful insights.
We’re throwing a birthday party at Data+AI Summit, with treats and limited-edition swag. Come celebrate with us and @hadley.nz!
📍 Posit Lounge (402)
📅 June 10, 6–8pm
For nearly two decades, it’s helped data scientists turn complex data into clear, beautiful insights.
We’re throwing a birthday party at Data+AI Summit, with treats and limited-edition swag. Come celebrate with us and @hadley.nz!
📍 Posit Lounge (402)
📅 June 10, 6–8pm

June 9, 2025 at 9:58 PM
ggplot2 is turning 18! 🎂
For nearly two decades, it’s helped data scientists turn complex data into clear, beautiful insights.
We’re throwing a birthday party at Data+AI Summit, with treats and limited-edition swag. Come celebrate with us and @hadley.nz!
📍 Posit Lounge (402)
📅 June 10, 6–8pm
For nearly two decades, it’s helped data scientists turn complex data into clear, beautiful insights.
We’re throwing a birthday party at Data+AI Summit, with treats and limited-edition swag. Come celebrate with us and @hadley.nz!
📍 Posit Lounge (402)
📅 June 10, 6–8pm
arxiv.org/abs/2506.00733 Our Interspeech 2025 preprint.

Quantifying and Reducing Speaker Heterogeneity within the Common Voice Corpus for Phonetic Analysis
With its crosslinguistic and cross-speaker diversity, the Mozilla Common Voice Corpus (CV) has been a valuable resource for multilingual speech technology and holds tremendous potential for research i...
arxiv.org
June 3, 2025 at 1:15 PM
arxiv.org/abs/2506.00733 Our Interspeech 2025 preprint.
The debate doesn't exist in China, we just call it [ʈʂi˥ aɪ˥ ɛ˧˥fu]

GIF is actually pronounced [xif], where [x] is the voiceless velar fricative

don’t worry guys, bluesky can be perfect so long as we all get along. first things first, we just need to agree on how "GIF" is pronounced
May 27, 2025 at 12:10 PM
The debate doesn't exist in China, we just call it [ʈʂi˥ aɪ˥ ɛ˧˥fu]
In case people don't use it very often, or never knew its existence, glimpse() from dplyr is a much better function to use when you want to have a very rough look at your dataset than head() or summary().
May 27, 2025 at 11:43 AM
In case people don't use it very often, or never knew its existence, glimpse() from dplyr is a much better function to use when you want to have a very rough look at your dataset than head() or summary().
youtu.be/cE3bK5XXbDc?... I recently gave a brief MFA tutorial.

MFA Workshop on 28 April 2025 | 张淼 Miao ZHANG | PAPPS | ZA JASRA
YouTube video by ZA JASRA (Linguistics)
youtu.be
May 26, 2025 at 9:54 AM
youtu.be/cE3bK5XXbDc?... I recently gave a brief MFA tutorial.
Reposted by Miao Zhang

💣 praatpicture version 1.4.0 on CRAN! 💣 (1/3)
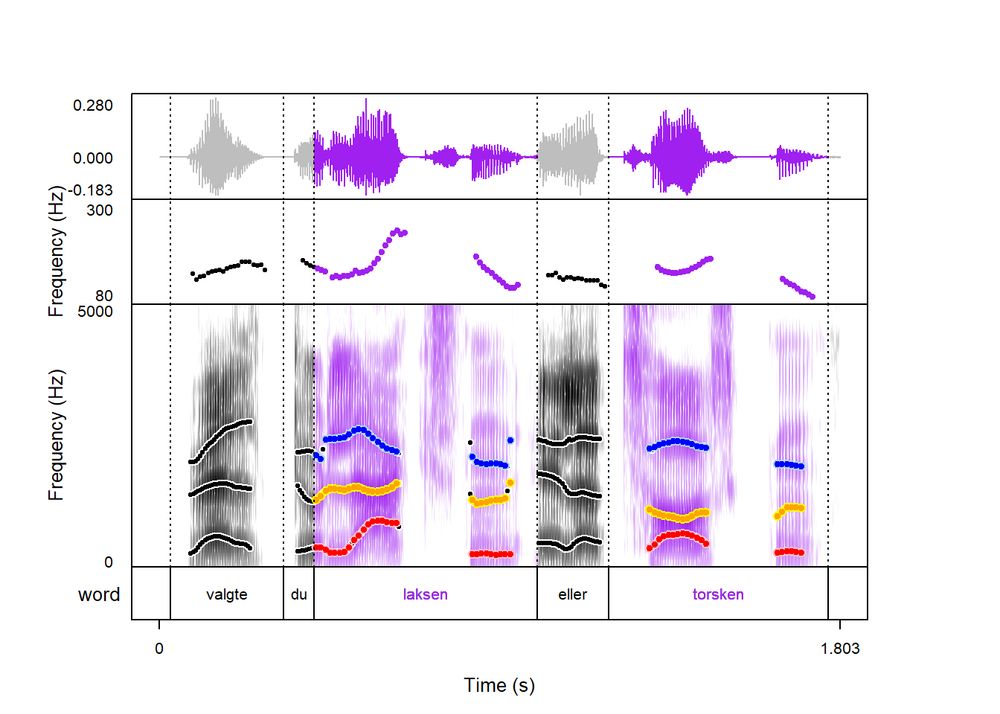
January 14, 2025 at 10:46 AM
💣 praatpicture version 1.4.0 on CRAN! 💣 (1/3)
Reposted by Miao Zhang

I also use Zotero for most of my reading. Other than that, the Google Scholar PDF Reader extension is the best thing w.r.t how citations are handled:
chromewebstore.google.com/detail/googl...
chromewebstore.google.com/detail/googl...

Google Scholar PDF Reader - Chrome Web Store
Supercharge your paper reading: follow references, skim outline, jump to figures, cite and save.
chromewebstore.google.com
May 21, 2025 at 8:43 AM
I also use Zotero for most of my reading. Other than that, the Google Scholar PDF Reader extension is the best thing w.r.t how citations are handled:
chromewebstore.google.com/detail/googl...
chromewebstore.google.com/detail/googl...
Reposted by Miao Zhang
Very exciting news for PraatSauce users! We've just pushed a new version which fully rewrites the code base, making things faster and simpler to use.
Instead of settings parameters in a bunch of Praat windows, you now set them in a spreadsheet file that looks like this
github.com/kirbyj/praat...
Instead of settings parameters in a bunch of Praat windows, you now set them in a spreadsheet file that looks like this
github.com/kirbyj/praat...

May 21, 2025 at 3:19 PM
Very exciting news for PraatSauce users! We've just pushed a new version which fully rewrites the code base, making things faster and simpler to use.
Instead of settings parameters in a bunch of Praat windows, you now set them in a spreadsheet file that looks like this
github.com/kirbyj/praat...
Instead of settings parameters in a bunch of Praat windows, you now set them in a spreadsheet file that looks like this
github.com/kirbyj/praat...
I’m thrilled to announce that our paper, Quantifying and Reducing Speaker Heterogeneity within the Common Voice Corpus for Phonetic Analysis, coauthored with @echodroff.bsky.social, Aref Farhadipour, Jiachen Ma, Annie Baker and Bogdan Pricop from @cl-uzh.bsky.social was accepted for INTERSPEECH2025.
May 21, 2025 at 9:36 AM
I’m thrilled to announce that our paper, Quantifying and Reducing Speaker Heterogeneity within the Common Voice Corpus for Phonetic Analysis, coauthored with @echodroff.bsky.social, Aref Farhadipour, Jiachen Ma, Annie Baker and Bogdan Pricop from @cl-uzh.bsky.social was accepted for INTERSPEECH2025.
Reposted by Miao Zhang

When running ANOVAs in #R, use car::Anova().
aov() and anova() use Type I sums of squares, meaning that order matters, which can distort results in unbalanced designs. car::Anova() is safer because it uses Type II sums of squares by default), each effect is adjusted for all the other effects.
aov() and anova() use Type I sums of squares, meaning that order matters, which can distort results in unbalanced designs. car::Anova() is safer because it uses Type II sums of squares by default), each effect is adjusted for all the other effects.
April 13, 2025 at 5:42 PM
When running ANOVAs in #R, use car::Anova().
aov() and anova() use Type I sums of squares, meaning that order matters, which can distort results in unbalanced designs. car::Anova() is safer because it uses Type II sums of squares by default), each effect is adjusted for all the other effects.
aov() and anova() use Type I sums of squares, meaning that order matters, which can distort results in unbalanced designs. car::Anova() is safer because it uses Type II sums of squares by default), each effect is adjusted for all the other effects.
When you train an acoustic model for a tone language with tone labels in the phone set, do you keep the underlying tone label or the surface tone label?
April 13, 2025 at 6:56 PM
When you train an acoustic model for a tone language with tone labels in the phone set, do you keep the underlying tone label or the surface tone label?