



Chris Offner
@chrisoffner3d.bsky.social
Student Researcher @ RAI Institute, MSc CS Student @ ETH Zurich
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
Pinned
Chris Offner
@chrisoffner3d.bsky.social
· Nov 11

When vision people do graphics, they call it "image synthesis." When graphics people do vision, they call it "inverse rendering". ;)
Reposted by Chris Offner

Looking forward to a busy #ICCV2025.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.

October 17, 2025 at 8:11 AM
Looking forward to a busy #ICCV2025.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
Reposted by Chris Offner

#TTT3R: 3D Reconstruction as Test-Time Training
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
October 1, 2025 at 6:35 AM
#TTT3R: 3D Reconstruction as Test-Time Training
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
Reposted by Chris Offner

🚀 Europe’s first exascale supercomputer is here!
JUPITER, launched in Germany, is the EU’s most powerful system and fourth fastest worldwide.
100% powered by renewables, it has also ranked first in energy efficiency. It will boost AI, science, and climate research.
Read more - europa.eu/!vcWBqW
JUPITER, launched in Germany, is the EU’s most powerful system and fourth fastest worldwide.
100% powered by renewables, it has also ranked first in energy efficiency. It will boost AI, science, and climate research.
Read more - europa.eu/!vcWBqW

September 6, 2025 at 7:17 AM
🚀 Europe’s first exascale supercomputer is here!
JUPITER, launched in Germany, is the EU’s most powerful system and fourth fastest worldwide.
100% powered by renewables, it has also ranked first in energy efficiency. It will boost AI, science, and climate research.
Read more - europa.eu/!vcWBqW
JUPITER, launched in Germany, is the EU’s most powerful system and fourth fastest worldwide.
100% powered by renewables, it has also ranked first in energy efficiency. It will boost AI, science, and climate research.
Read more - europa.eu/!vcWBqW
Reposted by Chris Offner

There is a lot to hate about the politics of the silicon valley right, but they do actually want to build stuff, and I would prefer if the left didn't cede "we should be able to build stuff" to the right.
September 5, 2025 at 3:19 PM
There is a lot to hate about the politics of the silicon valley right, but they do actually want to build stuff, and I would prefer if the left didn't cede "we should be able to build stuff" to the right.
Reposted by Chris Offner

I can't* fathom why the top picture, and not the bottom picture, is the standard diagram for an autoencoder.
The whole idea of an autoencoder is that you complete a round trip and seek cycle consistency—why lay out the network linearly?
The whole idea of an autoencoder is that you complete a round trip and seek cycle consistency—why lay out the network linearly?

August 29, 2025 at 10:46 PM
I can't* fathom why the top picture, and not the bottom picture, is the standard diagram for an autoencoder.
The whole idea of an autoencoder is that you complete a round trip and seek cycle consistency—why lay out the network linearly?
The whole idea of an autoencoder is that you complete a round trip and seek cycle consistency—why lay out the network linearly?
Great video on the convergent evolution from hierarchical military command structures to cybernetics to centralized AI coordination across political ideologies:
www.youtube.com/watch?v=mayo...
www.youtube.com/watch?v=mayo...
August 23, 2025 at 11:07 AM
Great video on the convergent evolution from hierarchical military command structures to cybernetics to centralized AI coordination across political ideologies:
www.youtube.com/watch?v=mayo...
www.youtube.com/watch?v=mayo...
Reposted by Chris Offner

In general I think 3D vision would do well to take some inspiration from Bayesians. I guess these days they lost their glamour, but imo it's a very nice way of thinking that feels somewhat lost currently.
August 22, 2025 at 3:18 PM
In general I think 3D vision would do well to take some inspiration from Bayesians. I guess these days they lost their glamour, but imo it's a very nice way of thinking that feels somewhat lost currently.
"It is beautiful. It is elegant. Does it work well in practice? Not really. This is often the caveat we face in research: the things that are beautiful don't work and the things that work are not beautiful." – Daniel Cremers
August 22, 2025 at 11:55 AM
"It is beautiful. It is elegant. Does it work well in practice? Not really. This is often the caveat we face in research: the things that are beautiful don't work and the things that work are not beautiful." – Daniel Cremers
"As roboticists and computer vision people [outside of big tech], do we have to just wait for the next foundation model?"
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
August 21, 2025 at 5:37 PM
"As roboticists and computer vision people [outside of big tech], do we have to just wait for the next foundation model?"
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
I share the frustration. It's disempowering when most major progress recently is downstream of "foundation models" that you don't have the compute or data to train yourself.
Reposted by Chris Offner

We're live on bluesky! bibliome.club is the platform for creating, collaborating on and sharing reading lists with your Bluesky network - open source and decentralised via ATProto.

Bibliome - Building the very best reading lists, together
Create collaborative bookshelves, discover new books, and build reading communities with friends. Join the decentralized reading revolution powered by Bluesky.
bibliome.club
August 20, 2025 at 8:45 PM
We're live on bluesky! bibliome.club is the platform for creating, collaborating on and sharing reading lists with your Bluesky network - open source and decentralised via ATProto.
Reposted by Chris Offner
The US calculus seems to be:
- The main 21st century story is US v. China.
- The US thus needs to focus on the Pacific.
- They need to peel Russia off of China and make it an ally.
- If this happens at the cost of the Europeans, so be it.
- Europe is useless as an ally and harmless as an adversary.
- The main 21st century story is US v. China.
- The US thus needs to focus on the Pacific.
- They need to peel Russia off of China and make it an ally.
- If this happens at the cost of the Europeans, so be it.
- Europe is useless as an ally and harmless as an adversary.
March 4, 2025 at 11:10 AM
The US calculus seems to be:
- The main 21st century story is US v. China.
- The US thus needs to focus on the Pacific.
- They need to peel Russia off of China and make it an ally.
- If this happens at the cost of the Europeans, so be it.
- Europe is useless as an ally and harmless as an adversary.
- The main 21st century story is US v. China.
- The US thus needs to focus on the Pacific.
- They need to peel Russia off of China and make it an ally.
- If this happens at the cost of the Europeans, so be it.
- Europe is useless as an ally and harmless as an adversary.
Yay, DINOv3 is out!
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.


August 14, 2025 at 5:59 PM
Yay, DINOv3 is out!
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
SigLIP (VLMs) and DINO are two competing paradigms for image encoders.
My intuition is that joint vision-language modeling works great for semantic problems but may be too coarse for geometry problems like SfM or SLAM.
Most animals navigate 3D space perfectly without language.
What are the best resources to learn about VLMs? Papers, tutorials, courses, blog posts, whatever is good. I can read the Kimi-VL or GLM tech reports and follow the breadcrumbs but I'd appreciate any and all recommendations towards a useful VLM curriculum! 🙏
August 12, 2025 at 5:58 PM
What are the best resources to learn about VLMs? Papers, tutorials, courses, blog posts, whatever is good. I can read the Kimi-VL or GLM tech reports and follow the breadcrumbs but I'd appreciate any and all recommendations towards a useful VLM curriculum! 🙏
Reposted by Chris Offner

Ensuring the robots can’t take our jobs by teaching the robots functional programming
June 28, 2025 at 1:21 AM
Ensuring the robots can’t take our jobs by teaching the robots functional programming
Reposted by Chris Offner
I was not aware that the #ECCV2024 oral recordings are publicly available... So here is the #ACEZero talk: eccv.ecva.net/virtual/2024...
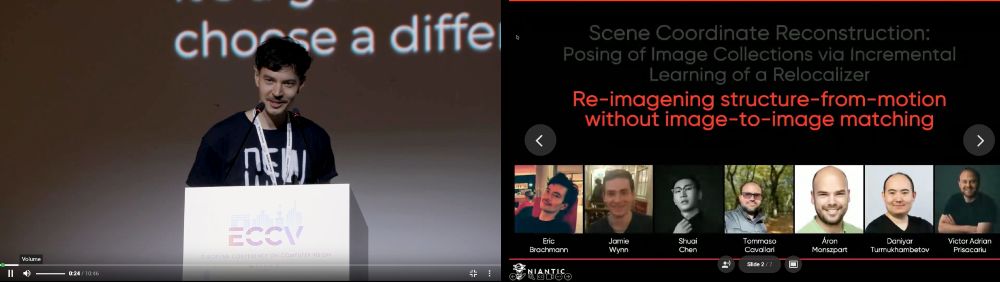
June 23, 2025 at 2:37 PM
I was not aware that the #ECCV2024 oral recordings are publicly available... So here is the #ACEZero talk: eccv.ecva.net/virtual/2024...
Reposted by Chris Offner

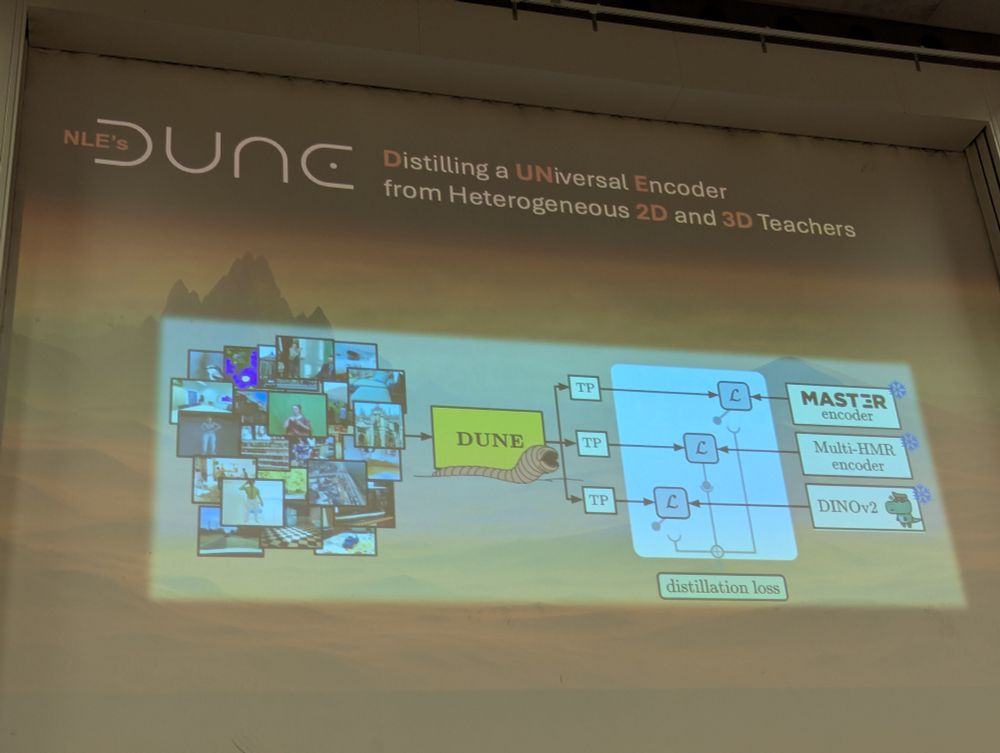
DUNE is a great universal image encoder which works for a large class of tasks and beats its teacher MASt3R on map free localization. #cvpr2025
We use it a lot already, I recommend it.
(keynote @ Paris by @dlarlus.bsky.social )
We use it a lot already, I recommend it.
(keynote @ Paris by @dlarlus.bsky.social )
June 6, 2025 at 12:48 PM
DUNE is a great universal image encoder which works for a large class of tasks and beats its teacher MASt3R on map free localization. #cvpr2025
We use it a lot already, I recommend it.
(keynote @ Paris by @dlarlus.bsky.social )
We use it a lot already, I recommend it.
(keynote @ Paris by @dlarlus.bsky.social )
Reposted by Chris Offner

I agree 100%. It's one thing to criticize corporate practices, the social impact, ethics, or future risks.
But I watch in total awe how it writes in a few seconds a well documented program in a language/API I don't know, while they complain "but it might have a bug and requires a pass or two" O_o
But I watch in total awe how it writes in a few seconds a well documented program in a language/API I don't know, while they complain "but it might have a bug and requires a pass or two" O_o
![gilbetron 60 days ago | next [=]
I get so confused on this. I play around, test, and mess with LLMs all the time and they are miraculous. Just amazing, doing things we dreamed about for decades. I mean, I can ask for obscure things with subtle nuance where I misspell words and mess up my question and it figures it out. It talks to me like a person. It generates really cool images. It helps me write code. And just tons of other stuff that astounds me.
And people just sit around, unimpressed, and complain that ... what ... it isn't a perfect superintelligence that understands everything perfectly? This is the most amazing technology I've experienced as a 50+ year old nerd that has been sitting deep in tech for basically my whole life. This is the stuff of science fiction, and while there totally are limitations, the speed at which it is progressing is insane. And people are like, "Wah, it can't write code like a Senior engineer with 20 years of experience!"
Crazy.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:wm4e6mmexrlsxgzypxk5kbhp/bafkreicte4bk6so5euwdn6vxx2zyufsw5qpqode3ilqyufo226gwsnas3q@jpeg)
May 31, 2025 at 11:11 PM
I agree 100%. It's one thing to criticize corporate practices, the social impact, ethics, or future risks.
But I watch in total awe how it writes in a few seconds a well documented program in a language/API I don't know, while they complain "but it might have a bug and requires a pass or two" O_o
But I watch in total awe how it writes in a few seconds a well documented program in a language/API I don't know, while they complain "but it might have a bug and requires a pass or two" O_o
My X feed's reaction to Dario Amodei's recent interviews.
May 31, 2025 at 6:23 PM
My X feed's reaction to Dario Amodei's recent interviews.
Reposted by Chris Offner

Collective intelligence is only as strong as our collective attention.

📢 New @cosmik.network blog post! Herbert Simon told us that information consumes attention. For 50 years, we've accepted that as a one-way street: attention as a scarce resource. This is the *linear* attention economy: we feel it as acute info overload, too many browser tabs open >

May 30, 2025 at 8:22 PM
Collective intelligence is only as strong as our collective attention.
Nice demonstration of the capabilities and failures of videogen models.
youtu.be/US2gO7UYEfY
youtu.be/US2gO7UYEfY

We Tested Google Veo and Runway to Create This AI Film. It Was Wild. | WSJ
YouTube video by The Wall Street Journal
youtu.be
May 30, 2025 at 5:29 AM
Nice demonstration of the capabilities and failures of videogen models.
youtu.be/US2gO7UYEfY
youtu.be/US2gO7UYEfY
Depending on who you talk to, a “deep dive” can mean spending seven years leading a field of research, or it can mean having six words on a slide instead of two.
May 20, 2025 at 6:46 AM
Depending on who you talk to, a “deep dive” can mean spending seven years leading a field of research, or it can mean having six words on a slide instead of two.
Ambitious projects are happening in Zurich’s AI scene.
www.theverge.com/news/669238/...
www.theverge.com/news/669238/...

May 19, 2025 at 5:50 AM
Ambitious projects are happening in Zurich’s AI scene.
www.theverge.com/news/669238/...
www.theverge.com/news/669238/...
Reposted by Chris Offner

This pattern is going to repeat in one domain after another, and gradually force us to admit that 60% of every job is networking, knowing who to trust, and doing poorly justified risk/benefit assessment.

The “AI Scientist” work, while interesting, sort of mischaracterizes the process of science as generating hypotheses and running experiments. The actual thing is so much more interesting: interpreting unclear evidence, reasoning about unsteady foundations, etc.
May 12, 2025 at 2:01 PM
This pattern is going to repeat in one domain after another, and gradually force us to admit that 60% of every job is networking, knowing who to trust, and doing poorly justified risk/benefit assessment.
Reposted by Chris Offner

VRG from CTU in Prague has 9 of its members listed as outstanding reviewers. Congratulations to @gkordo.bsky.social, @billpsomas.bsky.social , @stojnicv.xyz , Pavel Suma, @ducha-aiki.bsky.social , Miroslav Purkrábek, Tomas Vojir, and Yaqing Ding.

Behind every great conference is a team of dedicated reviewers. Congratulations to this year’s #CVPR2025 Outstanding Reviewers!
cvpr.thecvf.com/Conferences/...
cvpr.thecvf.com/Conferences/...
May 11, 2025 at 8:00 PM
VRG from CTU in Prague has 9 of its members listed as outstanding reviewers. Congratulations to @gkordo.bsky.social, @billpsomas.bsky.social , @stojnicv.xyz , Pavel Suma, @ducha-aiki.bsky.social , Miroslav Purkrábek, Tomas Vojir, and Yaqing Ding.
Reposted by Chris Offner

🎉💡 Impressions from today’s ETH Augmented Reality Lab (ETHAR) opening, a new hub dedicated to advancing core technologies in AR, in collab with Google. scientists.@christianholz.bsky.social @ethzurich.bsky.social

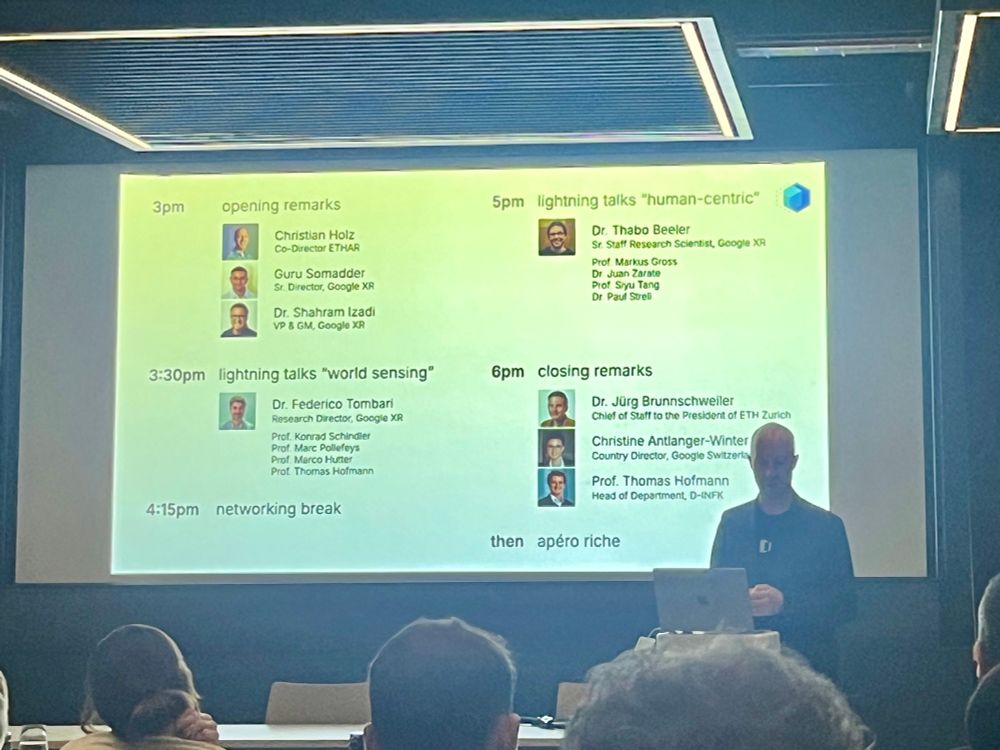


May 8, 2025 at 2:02 PM
🎉💡 Impressions from today’s ETH Augmented Reality Lab (ETHAR) opening, a new hub dedicated to advancing core technologies in AR, in collab with Google. scientists.@christianholz.bsky.social @ethzurich.bsky.social