



@alexrieber.bsky.social
Reposted

"Even after accounting for the upfront costs and delayed benefits, enrolling marginal applicants to public universities generates substantial net returns for society, the marginal students themselves, and the government budget."
Public Universities FTW!
Public Universities FTW!




December 24, 2025 at 9:00 PM
"Even after accounting for the upfront costs and delayed benefits, enrolling marginal applicants to public universities generates substantial net returns for society, the marginal students themselves, and the government budget."
Public Universities FTW!
Public Universities FTW!
Reposted

New paper! @william-dinneen.bsky.social @guygrossman.bsky.social Yiqing Xu and I use GPT to code 91k articles from 174 polisci journals (2003–2023)and track research designs, transparency practices, and citations. How has the credibility revolution reshaped the discipline? doi.org/10.31235/osf...
🧵
🧵

December 2, 2025 at 11:46 PM
New paper! @william-dinneen.bsky.social @guygrossman.bsky.social Yiqing Xu and I use GPT to code 91k articles from 174 polisci journals (2003–2023)and track research designs, transparency practices, and citations. How has the credibility revolution reshaped the discipline? doi.org/10.31235/osf...
🧵
🧵
Reposted

My reviewing style has changed over time. Rather than litigate every little thing, and pushing my own ideas, I focus only on 2 things:
(1) Are the claims interesting/important?
(2) Does the evidence support the claims?
Most of my reviews these days are short and focused.
(1) Are the claims interesting/important?
(2) Does the evidence support the claims?
Most of my reviews these days are short and focused.
November 8, 2025 at 11:22 AM
My reviewing style has changed over time. Rather than litigate every little thing, and pushing my own ideas, I focus only on 2 things:
(1) Are the claims interesting/important?
(2) Does the evidence support the claims?
Most of my reviews these days are short and focused.
(1) Are the claims interesting/important?
(2) Does the evidence support the claims?
Most of my reviews these days are short and focused.
Reposted
"When Product Markets Become Collective Traps: The Case of Social Media"
raw.githubusercontent.com/cproth/paper...
raw.githubusercontent.com/cproth/paper...

August 7, 2025 at 5:27 PM
"When Product Markets Become Collective Traps: The Case of Social Media"
raw.githubusercontent.com/cproth/paper...
raw.githubusercontent.com/cproth/paper...
Reposted

"...a model should be judged by criteria akin to those applied to stories, such as aesthetics, originality, and relevance. It does not require that a model have predictive power, nor that it be subjected to empirical testing. Essentially, crafting a compelling model is an art rather than a science."

August 7, 2025 at 7:14 PM
"...a model should be judged by criteria akin to those applied to stories, such as aesthetics, originality, and relevance. It does not require that a model have predictive power, nor that it be subjected to empirical testing. Essentially, crafting a compelling model is an art rather than a science."
Reposted
BREAKING: new study just dropped that shows compelling evidence that cell phone bans cause student grades to modestly increase.
Grade increases are largest among low performing students.
Grade increases are largest among low performing students.
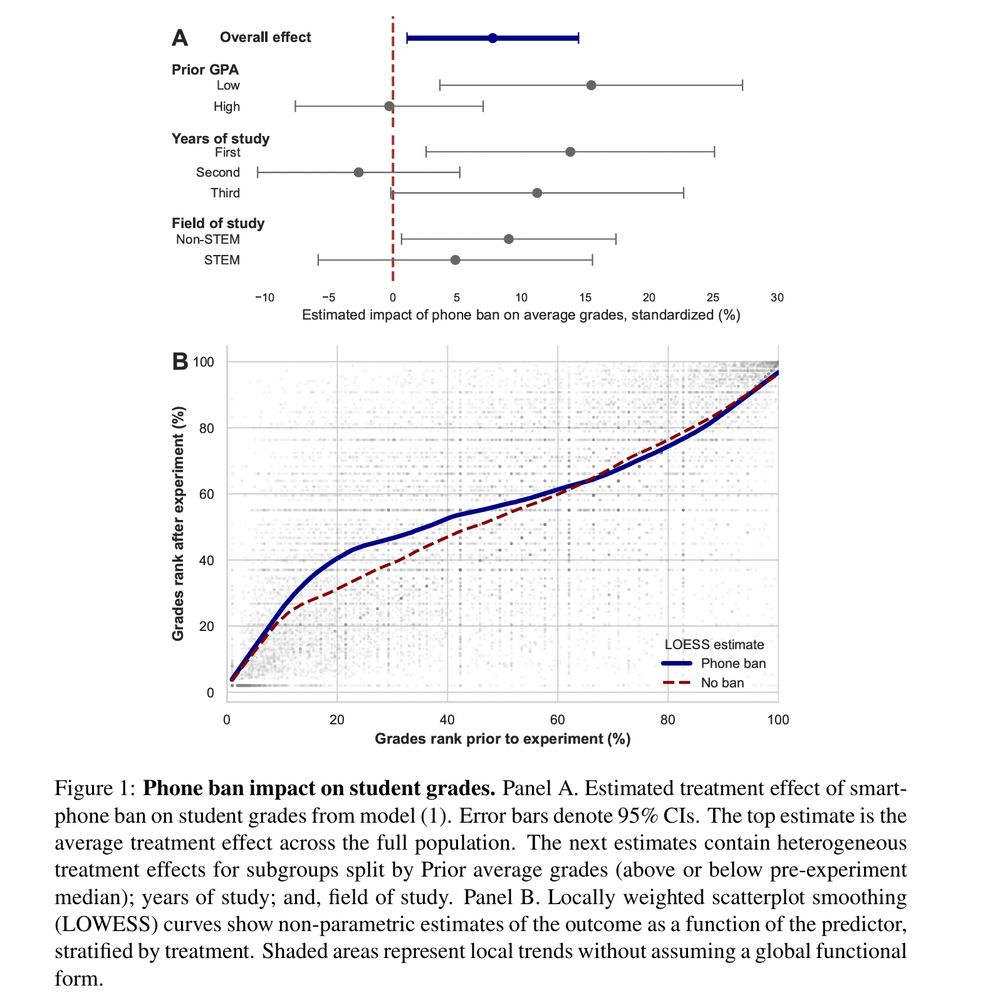
August 5, 2025 at 12:39 AM
BREAKING: new study just dropped that shows compelling evidence that cell phone bans cause student grades to modestly increase.
Grade increases are largest among low performing students.
Grade increases are largest among low performing students.
Reposted

🚨Free data alert!! 🚨 Please share.
Large new dataset of Amazon product reviews, including full text and photos and product characteristics, with individual *reviews labeled as fake reviews*.
I believe this is the first publicly available data of this kind.
github.com/bretthollenb...
Large new dataset of Amazon product reviews, including full text and photos and product characteristics, with individual *reviews labeled as fake reviews*.
I believe this is the first publicly available data of this kind.
github.com/bretthollenb...
July 11, 2025 at 9:18 PM
🚨Free data alert!! 🚨 Please share.
Large new dataset of Amazon product reviews, including full text and photos and product characteristics, with individual *reviews labeled as fake reviews*.
I believe this is the first publicly available data of this kind.
github.com/bretthollenb...
Large new dataset of Amazon product reviews, including full text and photos and product characteristics, with individual *reviews labeled as fake reviews*.
I believe this is the first publicly available data of this kind.
github.com/bretthollenb...
@simeonschudy.bsky.social very interesting... Adaptive is the new big thing?!
link 📈🤖
Admissibility of Completely Randomized Trials: A Large-Deviation Approach (Imbens, Qin, Wager) When an experimenter has the option of running an adaptive trial, is it admissible to ignore this option and run a non-adaptive trial instead? We provide a negative answer to this question in th
Admissibility of Completely Randomized Trials: A Large-Deviation Approach (Imbens, Qin, Wager) When an experimenter has the option of running an adaptive trial, is it admissible to ignore this option and run a non-adaptive trial instead? We provide a negative answer to this question in th
June 7, 2025 at 1:40 PM
@simeonschudy.bsky.social very interesting... Adaptive is the new big thing?!
@sebkranz.bsky.social kennst du das package schon? Könnte ganz hilfreich sein!
link 📈🤖
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
June 7, 2025 at 1:35 PM
@sebkranz.bsky.social kennst du das package schon? Könnte ganz hilfreich sein!
Reposted

link 📈🤖
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
June 7, 2025 at 3:25 AM
link 📈🤖
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
require: Package dependencies for reproducible research () arXiv:2309.11058v2 Announce Type: replace
Abstract: The ability to conduct reproducible research in Stata is often limited by the lack of version control for community-contributed packages. This article introduces the require com
Reposted

🚨New paper (link in reply)🚨
Are we underestimating AI use in self-report surveys?
Yes, by as much as 30 percentage pts. We find 60% self-reported vs. truth closer to ~90% (!!)
Why? Social desirability bias, people embarrassed/worried to admit AI use, so they underreport 🧵
Are we underestimating AI use in self-report surveys?
Yes, by as much as 30 percentage pts. We find 60% self-reported vs. truth closer to ~90% (!!)
Why? Social desirability bias, people embarrassed/worried to admit AI use, so they underreport 🧵

April 29, 2025 at 9:36 PM
🚨New paper (link in reply)🚨
Are we underestimating AI use in self-report surveys?
Yes, by as much as 30 percentage pts. We find 60% self-reported vs. truth closer to ~90% (!!)
Why? Social desirability bias, people embarrassed/worried to admit AI use, so they underreport 🧵
Are we underestimating AI use in self-report surveys?
Yes, by as much as 30 percentage pts. We find 60% self-reported vs. truth closer to ~90% (!!)
Why? Social desirability bias, people embarrassed/worried to admit AI use, so they underreport 🧵
Reposted

🧵New survey paper: "Inference with Few Treated Units"
Luis Alvarez, Bruno Ferman and Kaspar Wüthrich
Tired of referees saying your standard errors are wrong?
This survey will help you understand if you really have a problem — and, if so, how to fix it!
Luis Alvarez, Bruno Ferman and Kaspar Wüthrich
Tired of referees saying your standard errors are wrong?
This survey will help you understand if you really have a problem — and, if so, how to fix it!

April 29, 2025 at 2:18 PM
🧵New survey paper: "Inference with Few Treated Units"
Luis Alvarez, Bruno Ferman and Kaspar Wüthrich
Tired of referees saying your standard errors are wrong?
This survey will help you understand if you really have a problem — and, if so, how to fix it!
Luis Alvarez, Bruno Ferman and Kaspar Wüthrich
Tired of referees saying your standard errors are wrong?
This survey will help you understand if you really have a problem — and, if so, how to fix it!
Reposted

Just posted updated version of our DID textbook! We now have drafts of all chapters, including the one on general designs! Now you can tell your friends still on X that they are DID-outdated :-) Happy easter for those of you that celebrate it. papers.ssrn.com/sol3/papers....
Credible Answers to Hard Questions: Differences-in-Differences for Natural Experiments
This book introduces applied researchers to modern Differences-in-Differences (DID) methods, that they can use to obtain credible answers to hard causal inferen
papers.ssrn.com
April 18, 2025 at 2:28 PM
Just posted updated version of our DID textbook! We now have drafts of all chapters, including the one on general designs! Now you can tell your friends still on X that they are DID-outdated :-) Happy easter for those of you that celebrate it. papers.ssrn.com/sol3/papers....
Reposted

I just heard from someone that used this paper in a class they teach. Yay!
"How Big Are Effect Sizes in International Education Studies?"
journals.sagepub.com/doi/10.3102/...
"How Big Are Effect Sizes in International Education Studies?"
journals.sagepub.com/doi/10.3102/...

April 5, 2025 at 4:33 PM
I just heard from someone that used this paper in a class they teach. Yay!
"How Big Are Effect Sizes in International Education Studies?"
journals.sagepub.com/doi/10.3102/...
"How Big Are Effect Sizes in International Education Studies?"
journals.sagepub.com/doi/10.3102/...
This Post made my day

#Rstats is being rewritten in Rust, and the R Core already has a book coming out!

April 1, 2025 at 12:10 PM
This Post made my day
Reposted

Trying something new:
A 🧵 on a topic I find many students struggle with: "why do their 📊 look more professional than my 📊?"
It's *lots* of tiny decisions that aren't the defaults in many libraries, so let's break down 1 simple graph by @jburnmurdoch.bsky.social
🔗 www.ft.com/content/73a1...
A 🧵 on a topic I find many students struggle with: "why do their 📊 look more professional than my 📊?"
It's *lots* of tiny decisions that aren't the defaults in many libraries, so let's break down 1 simple graph by @jburnmurdoch.bsky.social
🔗 www.ft.com/content/73a1...
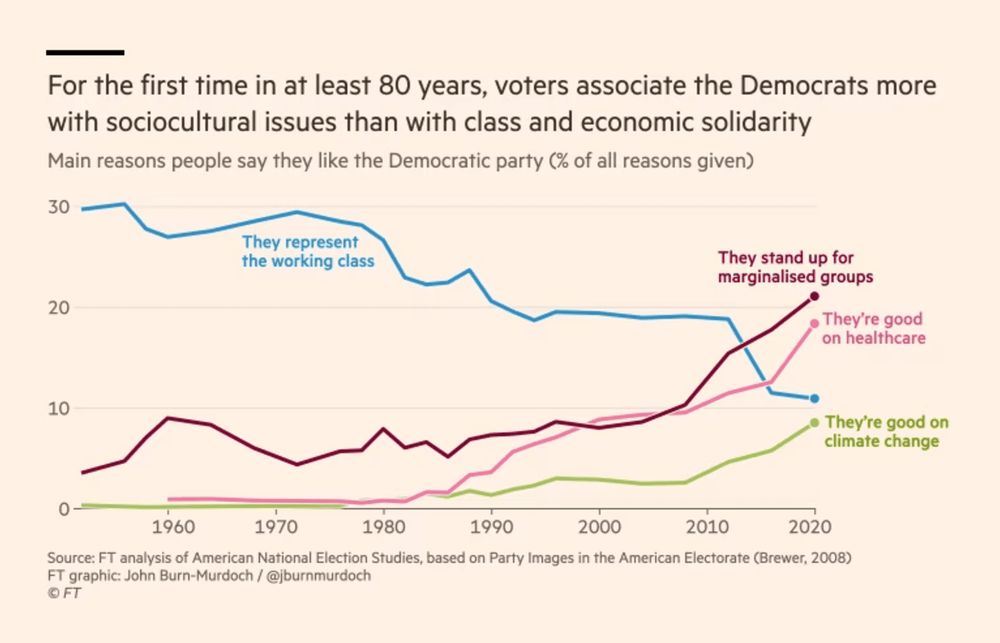
November 20, 2024 at 5:09 PM
Trying something new:
A 🧵 on a topic I find many students struggle with: "why do their 📊 look more professional than my 📊?"
It's *lots* of tiny decisions that aren't the defaults in many libraries, so let's break down 1 simple graph by @jburnmurdoch.bsky.social
🔗 www.ft.com/content/73a1...
A 🧵 on a topic I find many students struggle with: "why do their 📊 look more professional than my 📊?"
It's *lots* of tiny decisions that aren't the defaults in many libraries, so let's break down 1 simple graph by @jburnmurdoch.bsky.social
🔗 www.ft.com/content/73a1...
Reposted
Slowly but surely coming along: we have a new version of our working textbook on diffs in diffs!
papers.ssrn.com/sol3/papers....
Chapters 2 to 4, which cover the set up, classical DIDs, and relaxations of the parallel trends assumptions have been thoroughly revised and are now almost finished.
papers.ssrn.com/sol3/papers....
Chapters 2 to 4, which cover the set up, classical DIDs, and relaxations of the parallel trends assumptions have been thoroughly revised and are now almost finished.
Credible Answers to Hard Questions: Differences-in-Differences for Natural Experiments
This book introduces applied researchers to modern Differences-in-Differences (DID) methods, that they can use to obtain credible answers to hard causal inferen
papers.ssrn.com
March 12, 2025 at 3:09 PM
Slowly but surely coming along: we have a new version of our working textbook on diffs in diffs!
papers.ssrn.com/sol3/papers....
Chapters 2 to 4, which cover the set up, classical DIDs, and relaxations of the parallel trends assumptions have been thoroughly revised and are now almost finished.
papers.ssrn.com/sol3/papers....
Chapters 2 to 4, which cover the set up, classical DIDs, and relaxations of the parallel trends assumptions have been thoroughly revised and are now almost finished.
Reposted

After being alerted about possible misconduct, the I4R are reproducing published papers that use data from a specific NGO (GDRI). This thread releases the first 2 reports and provides more information about the work and responses/statements from authors journals and journals. 🧵


February 24, 2025 at 1:55 AM
After being alerted about possible misconduct, the I4R are reproducing published papers that use data from a specific NGO (GDRI). This thread releases the first 2 reports and provides more information about the work and responses/statements from authors journals and journals. 🧵
Reposted

We have a new version of our 𝕡𝕣𝕠𝕞𝕡𝕥𝕤𝕥𝕒𝕓𝕚𝕝𝕚𝕥𝕪 paper now on arxiv!
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...

February 18, 2025 at 11:46 AM
We have a new version of our 𝕡𝕣𝕠𝕞𝕡𝕥𝕤𝕥𝕒𝕓𝕚𝕝𝕚𝕥𝕪 paper now on arxiv!
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
Sounds really refreshing

Hello! Severine @oxfordecondept.bsky.social and I @uofebusiness.bsky.social are organising an online Behind-the-Scenes Seminar series, focussing on the story behind research papers + an interactive survey during the seminar to measure & discuss audience beliefs. Find out more here: bts-seminar.net
Home | BTS Seminar Series
The Behind-the-Scenes Seminar Series is designed to learn about the production process of research papers, offering an opportunity for students and researchers in all fields and at all career stages t...
bts-seminar.net
February 9, 2025 at 9:15 PM
Sounds really refreshing
Reposted
Modern-Day Oracles or Bullshit Machines?
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com

INTRODUCTION
thebullshitmachines.com
February 4, 2025 at 4:12 PM
Modern-Day Oracles or Bullshit Machines?
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
@simeonschudy.bsky.social @sebkranz.bsky.social very interesting discussion!

🚨 Oprea (2024 AER) argued that prospect theory choice anomalies were not due to risk, but due to complexity-driven mistakes.
But this new analysis convinces me that Oprea (2024) is substantially wrong. In my opinion, the paper should be retracted.
But this new analysis convinces me that Oprea (2024) is substantially wrong. In my opinion, the paper should be retracted.

A new working paper with Daniel Banki, @urisohn.bsky.social and Robert Walatka, just submitted to SSRN.
The paper is comment on Ryan Oprea's recent AER paper.
The paper is processing, but you, my friends, get early entry.
papers.ssrn.com/sol3/papers....
The paper is comment on Ryan Oprea's recent AER paper.
The paper is processing, but you, my friends, get early entry.
papers.ssrn.com/sol3/papers....
February 7, 2025 at 9:04 AM
@simeonschudy.bsky.social @sebkranz.bsky.social very interesting discussion!
Reposted

