




Jacob Eisenstein
@jacobeisenstein.bsky.social
natural language processing and computational linguistics at google deepmind.
Reposted by Jacob Eisenstein

No better time to start learning about that #AI thing everyone's talking about...
📢 I'm recruiting PhD students in Computer Science or Information Science @cornellbowers.bsky.social!
If you're interested, apply to either department (yes, either program!) and list me as a potential advisor!
📢 I'm recruiting PhD students in Computer Science or Information Science @cornellbowers.bsky.social!
If you're interested, apply to either department (yes, either program!) and list me as a potential advisor!

November 6, 2025 at 4:19 PM
No better time to start learning about that #AI thing everyone's talking about...
📢 I'm recruiting PhD students in Computer Science or Information Science @cornellbowers.bsky.social!
If you're interested, apply to either department (yes, either program!) and list me as a potential advisor!
📢 I'm recruiting PhD students in Computer Science or Information Science @cornellbowers.bsky.social!
If you're interested, apply to either department (yes, either program!) and list me as a potential advisor!
knowing how to tie your shoes or order a drink in a crowded bar: not agi
naming the big five personality traits: definitely agi
naming the big five personality traits: definitely agi

I'll never understand why people willingly attach their names to quack pseudoscience like this. We should run some psychometrics on the coauthor list.
A Definition of AGI
A definition and measurement of Artificial General Intelligence (AGI)
www.agidefinition.ai
October 17, 2025 at 10:01 PM
knowing how to tie your shoes or order a drink in a crowded bar: not agi
naming the big five personality traits: definitely agi
naming the big five personality traits: definitely agi
nice summary of everybody’s new fave

𝑵𝒆𝒘 𝒃𝒍𝒐𝒈𝒑𝒐𝒔𝒕! A rundown of some cool papers I got to chat about at #COLM2025 and some scattered thoughts
saxon.me/blog/2025/co...
saxon.me/blog/2025/co...

COLM 2025: 9 cool papers and some thoughts
Reflections on the 2025 COLM conference, and a discussion of 9 cool COLM papers on benchmarking and eval, personas, and improving models for better long-context performance and consistency.
saxon.me
October 17, 2025 at 5:40 PM
nice summary of everybody’s new fave

Reposted by Jacob Eisenstein

October 6, 2025 at 8:26 PM
Reposted by Jacob Eisenstein

AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.

October 3, 2025 at 10:53 PM
AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.
Reposted by Jacob Eisenstein

Excited to share a new paper that aims to narrow the conceptual gap between the idealized notion of Kolmogorov complexity and practical complexity measures for neural networks.

October 1, 2025 at 2:11 PM
Excited to share a new paper that aims to narrow the conceptual gap between the idealized notion of Kolmogorov complexity and practical complexity measures for neural networks.
Reposted by Jacob Eisenstein

Cannot stress enough how good it is that you can come across a post about gorgeous little Yiddish book sitting in someone’s family collection, and within a few seconds you can find the full scanned version of the book available for free through the Yiddish Book Center’s website
August 25, 2025 at 11:49 PM
Cannot stress enough how good it is that you can come across a post about gorgeous little Yiddish book sitting in someone’s family collection, and within a few seconds you can find the full scanned version of the book available for free through the Yiddish Book Center’s website
found some books at my parents’ house


August 25, 2025 at 9:49 PM
found some books at my parents’ house

Baristas still safe from robotic automation, and not just because robots don’t know what coffee tastes like.
prompt: “I’m trying to dial in this v60 of huatusco with my vario. temp / grind recommendations?”
prompt: “I’m trying to dial in this v60 of huatusco with my vario. temp / grind recommendations?”




August 11, 2025 at 4:02 PM
Baristas still safe from robotic automation, and not just because robots don’t know what coffee tastes like.
prompt: “I’m trying to dial in this v60 of huatusco with my vario. temp / grind recommendations?”
prompt: “I’m trying to dial in this v60 of huatusco with my vario. temp / grind recommendations?”
I’d guess that the majority position of syntacticians about LLMs (and other NLP beforehand) is roughly what Chomsky says: language tech can’t possibly teach us anything about the human language capability, so whether the LLM writes well doesn’t matter at all.

the thing about Emily Bender is that the reason she hates LLMs is that the fact that they exist -- not that they are "AGI," but the fact that they exist -- falsifies every paper she has ever written. you more or less can't be a formal grammar person in a world where statistical learning works.
August 8, 2025 at 2:26 PM
I’d guess that the majority position of syntacticians about LLMs (and other NLP beforehand) is roughly what Chomsky says: language tech can’t possibly teach us anything about the human language capability, so whether the LLM writes well doesn’t matter at all.
boston champaign pittsburgh atlanta, and, uh, let’s count seattle
glad i did it, hope i don’t have to do it again
glad i did it, hope i don’t have to do it again

under golikehellism everyone will be required to live in at least three new cities where they know less than five people from the age of 20-40
August 7, 2025 at 4:12 AM
boston champaign pittsburgh atlanta, and, uh, let’s count seattle
glad i did it, hope i don’t have to do it again
glad i did it, hope i don’t have to do it again
Reposted by Jacob Eisenstein

🤖 ICYMI: Yesterday, @hf.co and OpenAI partnered to bring open source GPT to the public. This is a Big Deal in "AI world". Allow me to explain why. 🧵
huggingface.co/openai/gpt-o...
huggingface.co/openai/gpt-o...

August 6, 2025 at 9:38 PM
🤖 ICYMI: Yesterday, @hf.co and OpenAI partnered to bring open source GPT to the public. This is a Big Deal in "AI world". Allow me to explain why. 🧵
huggingface.co/openai/gpt-o...
huggingface.co/openai/gpt-o...
Reposted by Jacob Eisenstein

roman burrito thread

you also have the laganum, which is (at some points) a pancake-ish kinda dough snack. slather on a "salsa" of garlic, onions, olives, and vinegar. pile on some roasted lamb or pork and caramelized onions, with some parsley or cilantro. chickpeas sub for beans. artichoke hearts, too
July 29, 2025 at 6:43 PM
roman burrito thread
Reposted by Jacob Eisenstein
this is very cool and i’m looking forward to reading the paper, but a basic question about this data: isn’t it likely that a congressional rep’s speeches are written by a shifting cast of speechwriters over the course of their career? wouldn’t that explain adoption of new usages?
July 29, 2025 at 9:16 PM
this is very cool and i’m looking forward to reading the paper, but a basic question about this data: isn’t it likely that a congressional rep’s speeches are written by a shifting cast of speechwriters over the course of their career? wouldn’t that explain adoption of new usages?
Reposted by Jacob Eisenstein

Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
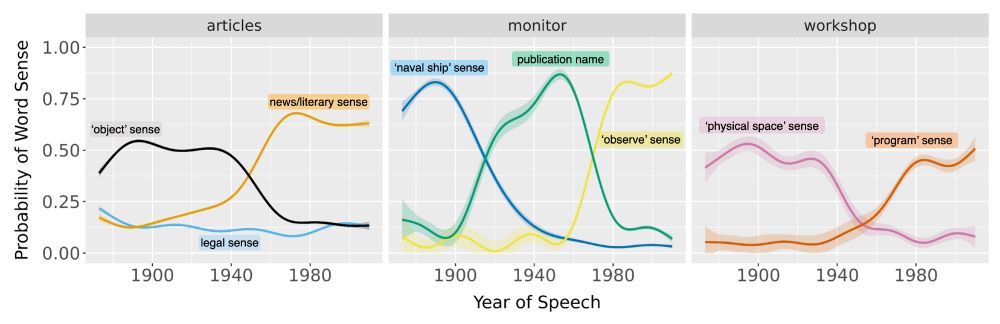
July 29, 2025 at 12:06 PM
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
There's a lot to like in this position paper - and not just the "whiff of Frankenstein" quote. www.arxiv.org/abs/2507.06268

July 25, 2025 at 10:13 PM
There's a lot to like in this position paper - and not just the "whiff of Frankenstein" quote. www.arxiv.org/abs/2507.06268
Reposted by Jacob Eisenstein
What are your favorite recent papers on using LMs for annotation (especially in a loop with human annotators), synthetic data for task-specific prediction, active learning, and similar?
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
July 23, 2025 at 8:10 AM
What are your favorite recent papers on using LMs for annotation (especially in a loop with human annotators), synthetic data for task-specific prediction, active learning, and similar?
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Reposted by Jacob Eisenstein

[Thu Jul 17]
w/ Ananth Balashankar & @jacobeisenstein.bsky.social, we present a reinforcement learning framework in view of test-time scaling. We show how to optimally calibrate & transform rewards to obtain optimal performance with a given test-time algorithm.
w/ Ananth Balashankar & @jacobeisenstein.bsky.social, we present a reinforcement learning framework in view of test-time scaling. We show how to optimally calibrate & transform rewards to obtain optimal performance with a given test-time algorithm.

Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. Standard RLHF focuses only on improving the trained model. This creates a train/inference mismatch.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.

July 9, 2025 at 10:41 PM
[Thu Jul 17]
w/ Ananth Balashankar & @jacobeisenstein.bsky.social, we present a reinforcement learning framework in view of test-time scaling. We show how to optimally calibrate & transform rewards to obtain optimal performance with a given test-time algorithm.
w/ Ananth Balashankar & @jacobeisenstein.bsky.social, we present a reinforcement learning framework in view of test-time scaling. We show how to optimally calibrate & transform rewards to obtain optimal performance with a given test-time algorithm.
Reposted by Jacob Eisenstein
[Wed Jul 16]
w/ @jacobeisenstein.bsky.social & Alekh Agarwal, we present a theoretical characterization of best-of-N (a simple yet effective method for test-time scaling & alignment). Our results justify the widespread use of BoN as a strong baseline in this space.
w/ @jacobeisenstein.bsky.social & Alekh Agarwal, we present a theoretical characterization of best-of-N (a simple yet effective method for test-time scaling & alignment). Our results justify the widespread use of BoN as a strong baseline in this space.
𝐛𝐞𝐬𝐭-𝐨𝐟-𝐧 is a strong baseline for
- improving agents
- scaling inference-time compute
- preference alignment
- jailbreaking models
How does 𝐁𝐨𝐧 work? and why is it so strong?
Find some answers in the paper we wrote over two Christmas breaks!🧵
- improving agents
- scaling inference-time compute
- preference alignment
- jailbreaking models
How does 𝐁𝐨𝐧 work? and why is it so strong?
Find some answers in the paper we wrote over two Christmas breaks!🧵

July 9, 2025 at 10:41 PM
[Wed Jul 16]
w/ @jacobeisenstein.bsky.social & Alekh Agarwal, we present a theoretical characterization of best-of-N (a simple yet effective method for test-time scaling & alignment). Our results justify the widespread use of BoN as a strong baseline in this space.
w/ @jacobeisenstein.bsky.social & Alekh Agarwal, we present a theoretical characterization of best-of-N (a simple yet effective method for test-time scaling & alignment). Our results justify the widespread use of BoN as a strong baseline in this space.
Cheap but noisy?
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949

Cost-Optimal Active AI Model Evaluation
The development lifecycle of generative AI systems requires continual evaluation, data acquisition, and annotation, which is costly in both resources and time. In practice, rapid iteration often makes...
www.arxiv.org
June 10, 2025 at 3:24 PM
Cheap but noisy?
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Reposted by Jacob Eisenstein

Everyone should check out People Time, the recording of his dates with Kenny Barron in Copenhagen three months before his death. Getz knew he was dying, and produced some of the most moving music of his career. www.youtube.com/watch?v=c3jd...
June 6, 2025 at 6:54 PM
Everyone should check out People Time, the recording of his dates with Kenny Barron in Copenhagen three months before his death. Getz knew he was dying, and produced some of the most moving music of his career. www.youtube.com/watch?v=c3jd...
Great topic! looking forward to this

I guess that now that I have 1% of my Twitter followers follow me here 😅, I should announce it here too for those of you no longer checking Twitter: my nonfiction book, "Lost in Automatic Translation" is coming out this July: lostinautomatictranslation.com. I'm very excited to share it with you!

May 28, 2025 at 12:19 AM
Great topic! looking forward to this
most relatable parenting thread

I am at war with my 9yo.
He asked me to guess how many Nerds were in a box of Nerds and I did and asked if I was right and he said “well, well never know” and I said “of course we can know.” And he said “I’m not gonna count them all.” And I said: “you don’t have to” and explained MATH.
He asked me to guess how many Nerds were in a box of Nerds and I did and asked if I was right and he said “well, well never know” and I said “of course we can know.” And he said “I’m not gonna count them all.” And I said: “you don’t have to” and explained MATH.
May 25, 2025 at 7:19 PM
most relatable parenting thread