



Yuda Song
@yus167.bsky.social
PhD at Machine Learning Department, Carnegie Mellon University | Interactive Decision Making | https://yudasong.github.io
Reposted by Yuda Song

🚨Microsoft Research NYC is hiring🚨
We're hiring postdocs and senior researchers in AI/ML broadly, and in specific areas like test-time scaling and science of DL. Postdoc applications due Oct 22, 2025. Senior researcher applications considered on a rolling basis.
Links to apply: aka.ms/msrnyc-jobs
We're hiring postdocs and senior researchers in AI/ML broadly, and in specific areas like test-time scaling and science of DL. Postdoc applications due Oct 22, 2025. Senior researcher applications considered on a rolling basis.
Links to apply: aka.ms/msrnyc-jobs

Microsoft Research Lab - New York City - Microsoft Research
Apply for a research position at Microsoft Research New York & collaborate with academia to advance economics research, prediction markets & ML.
aka.ms
September 18, 2025 at 2:37 PM
🚨Microsoft Research NYC is hiring🚨
We're hiring postdocs and senior researchers in AI/ML broadly, and in specific areas like test-time scaling and science of DL. Postdoc applications due Oct 22, 2025. Senior researcher applications considered on a rolling basis.
Links to apply: aka.ms/msrnyc-jobs
We're hiring postdocs and senior researchers in AI/ML broadly, and in specific areas like test-time scaling and science of DL. Postdoc applications due Oct 22, 2025. Senior researcher applications considered on a rolling basis.
Links to apply: aka.ms/msrnyc-jobs
Reposted by Yuda Song

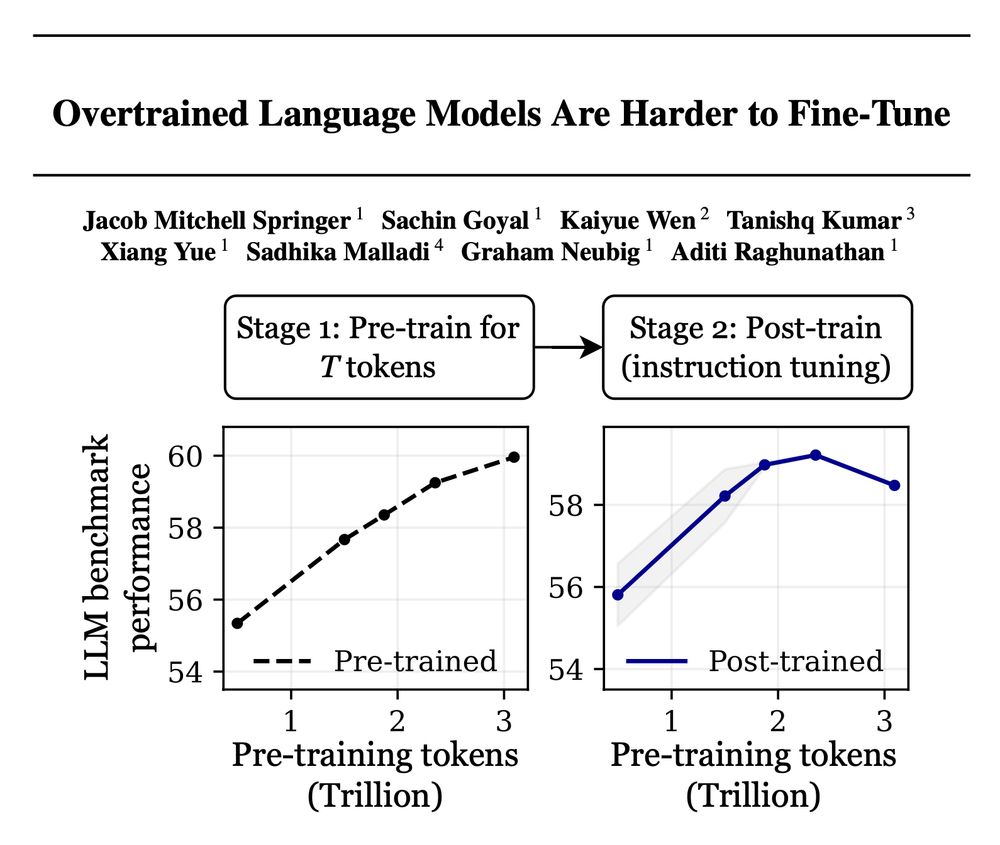
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
March 26, 2025 at 6:35 PM
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
Reposted by Yuda Song

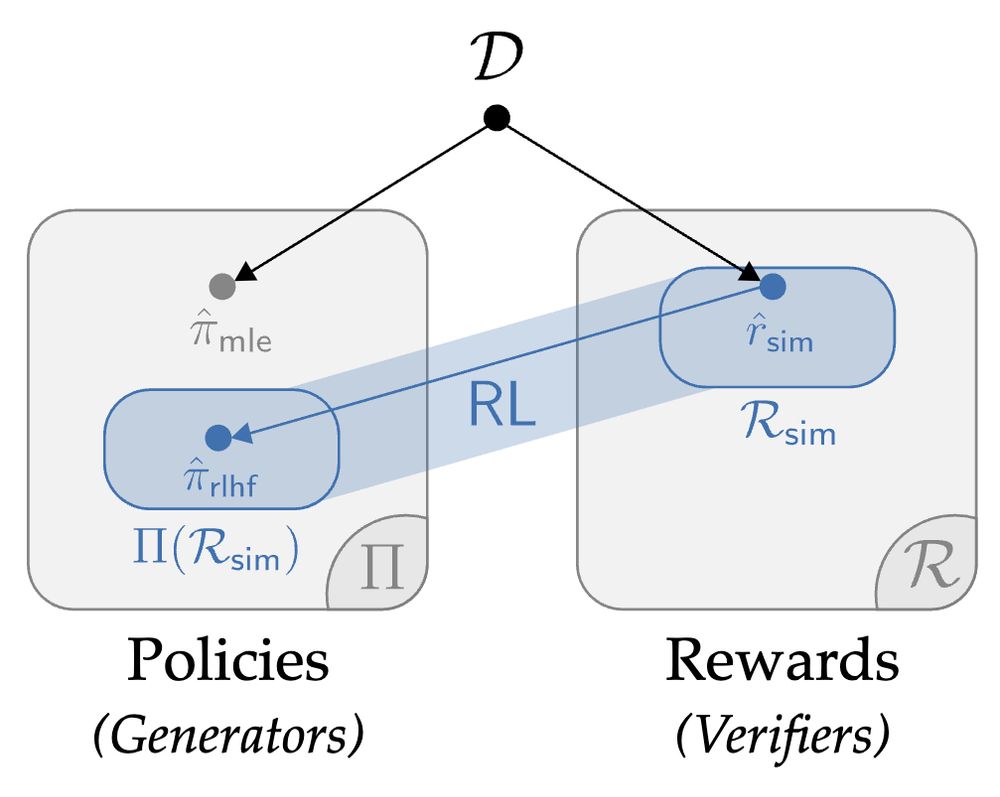
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
March 4, 2025 at 8:59 PM
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
Reposted by Yuda Song

super happy about this preprint! we can *finally* perform efficient exploration and find near-optimal stationary policies in infinite-horizon linear MDPs, and even use it for imitation learning :) working with @neu-rips.bsky.social and @lviano.bsky.social on this was so much fun!!

February 20, 2025 at 5:45 PM
super happy about this preprint! we can *finally* perform efficient exploration and find near-optimal stationary policies in infinite-horizon linear MDPs, and even use it for imitation learning :) working with @neu-rips.bsky.social and @lviano.bsky.social on this was so much fun!!
Reposted by Yuda Song

What are the minimal supervised learning primitives required to perform RL efficiently?
New paper led by my amazing intern Dhruv Rohatgi:
Necessary and Sufficient Oracles: Toward a Computational Taxonomy for Reinforcement Learning
arxiv.org/abs/2502.08632
1/
New paper led by my amazing intern Dhruv Rohatgi:
Necessary and Sufficient Oracles: Toward a Computational Taxonomy for Reinforcement Learning
arxiv.org/abs/2502.08632
1/

February 20, 2025 at 11:39 PM
What are the minimal supervised learning primitives required to perform RL efficiently?
New paper led by my amazing intern Dhruv Rohatgi:
Necessary and Sufficient Oracles: Toward a Computational Taxonomy for Reinforcement Learning
arxiv.org/abs/2502.08632
1/
New paper led by my amazing intern Dhruv Rohatgi:
Necessary and Sufficient Oracles: Toward a Computational Taxonomy for Reinforcement Learning
arxiv.org/abs/2502.08632
1/
Reposted by Yuda Song

Models can self-improve🥷 by knowing they were wrong🧘♀️ but when can they do it?
Across LLM families, tasks and mechanisms
This ability scales with pretraining, prefers CoT, non QA tasks and more in 🧵
alphaxiv.org/abs/2412.02674
@yus167.bsky.social @shamkakade.bsky.social
📈🤖
#NLP #ML
Across LLM families, tasks and mechanisms
This ability scales with pretraining, prefers CoT, non QA tasks and more in 🧵
alphaxiv.org/abs/2412.02674
@yus167.bsky.social @shamkakade.bsky.social
📈🤖
#NLP #ML

Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models | alphaXiv
View 3 comments: Delete the space?
alphaxiv.org
December 13, 2024 at 11:55 PM
Models can self-improve🥷 by knowing they were wrong🧘♀️ but when can they do it?
Across LLM families, tasks and mechanisms
This ability scales with pretraining, prefers CoT, non QA tasks and more in 🧵
alphaxiv.org/abs/2412.02674
@yus167.bsky.social @shamkakade.bsky.social
📈🤖
#NLP #ML
Across LLM families, tasks and mechanisms
This ability scales with pretraining, prefers CoT, non QA tasks and more in 🧵
alphaxiv.org/abs/2412.02674
@yus167.bsky.social @shamkakade.bsky.social
📈🤖
#NLP #ML
I will present two papers at #NeurIPS2024!
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
NeurIPS Poster The Importance of Online Data: Understanding Preference Fine-tuning via CoverageNeurIPS 2024
neurips.cc
December 9, 2024 at 7:49 PM
I will present two papers at #NeurIPS2024!
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
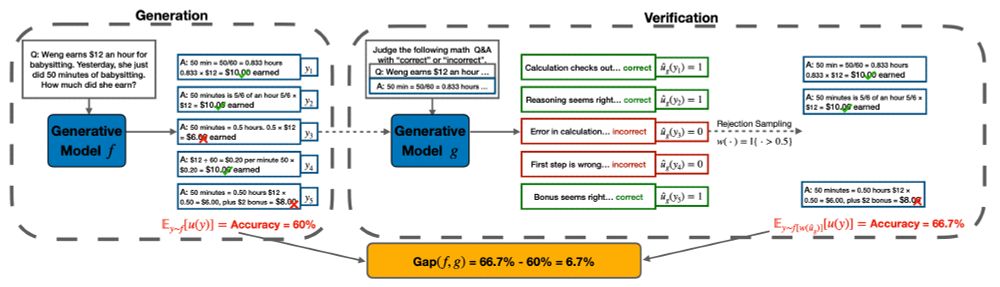
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
December 6, 2024 at 6:02 PM
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
Reposted by Yuda Song

Yuda Song, Hanlin Zhang, Carson Eisenach, Sham Kakade, Dean Foster, Udaya Ghai
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
https://arxiv.org/abs/2412.02674
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
https://arxiv.org/abs/2412.02674
December 4, 2024 at 9:09 AM
Yuda Song, Hanlin Zhang, Carson Eisenach, Sham Kakade, Dean Foster, Udaya Ghai
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
https://arxiv.org/abs/2412.02674
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
https://arxiv.org/abs/2412.02674
Reposted by Yuda Song
I think the main difference in terms of interpolation / extrapolation between DPO and RLHF is that the former only guarantees closeness to the reference policy on the training data, while RLHF usually tacks on an on-policy KL penalty. We explored this point in arxiv.org/abs/2406.01462.
November 22, 2024 at 3:38 PM
I think the main difference in terms of interpolation / extrapolation between DPO and RLHF is that the former only guarantees closeness to the reference policy on the training data, while RLHF usually tacks on an on-policy KL penalty. We explored this point in arxiv.org/abs/2406.01462.
Reposted by Yuda Song

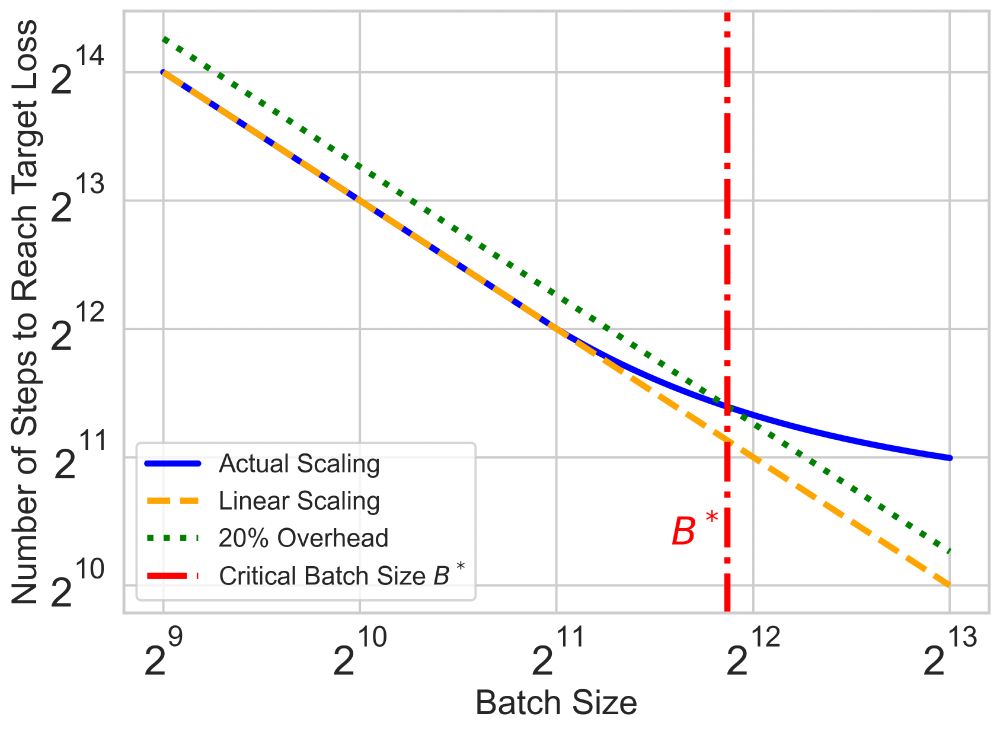
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
November 22, 2024 at 8:19 PM
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
Reposted by Yuda Song

I created a starter pack for people who are or have been affiliated with the Machine Learning Department at CMU. Let me know if I missed someone!
go.bsky.app/QLTVEph
#AcademicSky
go.bsky.app/QLTVEph
#AcademicSky
November 18, 2024 at 3:46 PM
I created a starter pack for people who are or have been affiliated with the Machine Learning Department at CMU. Let me know if I missed someone!
go.bsky.app/QLTVEph
#AcademicSky
go.bsky.app/QLTVEph
#AcademicSky
Reposted by Yuda Song

Ojash Neopane, Aaditya Ramdas, Aarti Singh
Logarithmic Neyman Regret for Adaptive Estimation of the Average Treatment Effect
https://arxiv.org/abs/2411.14341
Logarithmic Neyman Regret for Adaptive Estimation of the Average Treatment Effect
https://arxiv.org/abs/2411.14341
November 22, 2024 at 5:01 AM
Ojash Neopane, Aaditya Ramdas, Aarti Singh
Logarithmic Neyman Regret for Adaptive Estimation of the Average Treatment Effect
https://arxiv.org/abs/2411.14341
Logarithmic Neyman Regret for Adaptive Estimation of the Average Treatment Effect
https://arxiv.org/abs/2411.14341
Reposted by Yuda Song

Intro 🦋
I am a final-year PhD student from CMU Robotics. I work on humanoid control, perception, and behavior in both simulation and real life, using mostly RL:
🏃🏻PHC: zhengyiluo.com/PHC
💫PULSE: zhengyiluo.com/PULSE
🔩Omnigrasp: zhengyiluo.com/Omnigrasp
🤖OmniH2O: omni.human2humanoid.com
I am a final-year PhD student from CMU Robotics. I work on humanoid control, perception, and behavior in both simulation and real life, using mostly RL:
🏃🏻PHC: zhengyiluo.com/PHC
💫PULSE: zhengyiluo.com/PULSE
🔩Omnigrasp: zhengyiluo.com/Omnigrasp
🤖OmniH2O: omni.human2humanoid.com
November 19, 2024 at 8:34 PM
Intro 🦋
I am a final-year PhD student from CMU Robotics. I work on humanoid control, perception, and behavior in both simulation and real life, using mostly RL:
🏃🏻PHC: zhengyiluo.com/PHC
💫PULSE: zhengyiluo.com/PULSE
🔩Omnigrasp: zhengyiluo.com/Omnigrasp
🤖OmniH2O: omni.human2humanoid.com
I am a final-year PhD student from CMU Robotics. I work on humanoid control, perception, and behavior in both simulation and real life, using mostly RL:
🏃🏻PHC: zhengyiluo.com/PHC
💫PULSE: zhengyiluo.com/PULSE
🔩Omnigrasp: zhengyiluo.com/Omnigrasp
🤖OmniH2O: omni.human2humanoid.com
Reposted by Yuda Song
Hi Bsky people 👋 I'm a PhD candidate in Machine Learning at Carnegie Mellon University.
My research focuses on interactive AI, involving:
🤖 reinforcement learning,
🧠 foundation models, and
👩💻 human-centered AI.
Also a founding co-organizer of the MineRL competitions 🖤 Follow me for ML updates!
My research focuses on interactive AI, involving:
🤖 reinforcement learning,
🧠 foundation models, and
👩💻 human-centered AI.
Also a founding co-organizer of the MineRL competitions 🖤 Follow me for ML updates!

November 18, 2024 at 3:05 PM
Hi Bsky people 👋 I'm a PhD candidate in Machine Learning at Carnegie Mellon University.
My research focuses on interactive AI, involving:
🤖 reinforcement learning,
🧠 foundation models, and
👩💻 human-centered AI.
Also a founding co-organizer of the MineRL competitions 🖤 Follow me for ML updates!
My research focuses on interactive AI, involving:
🤖 reinforcement learning,
🧠 foundation models, and
👩💻 human-centered AI.
Also a founding co-organizer of the MineRL competitions 🖤 Follow me for ML updates!