



Yuda Song
@yus167.bsky.social
PhD at Machine Learning Department, Carnegie Mellon University | Interactive Decision Making | https://yudasong.github.io
We also dive deep into the similarity and difference between different verification mechanisms. We observed the consistency, distinction and ensemble properties of the verification methods (see the summary image). (8/9)

December 6, 2024 at 6:02 PM
We also dive deep into the similarity and difference between different verification mechanisms. We observed the consistency, distinction and ensemble properties of the verification methods (see the summary image). (8/9)
In iterative self-improvement, we observe the gap diminishes to 0 in a few iterations, resembling many previous findings. We discovered that one cause of such saturation is the degradation of the "effective diversity" of the generation due to the imperfect verifier. (7/9)
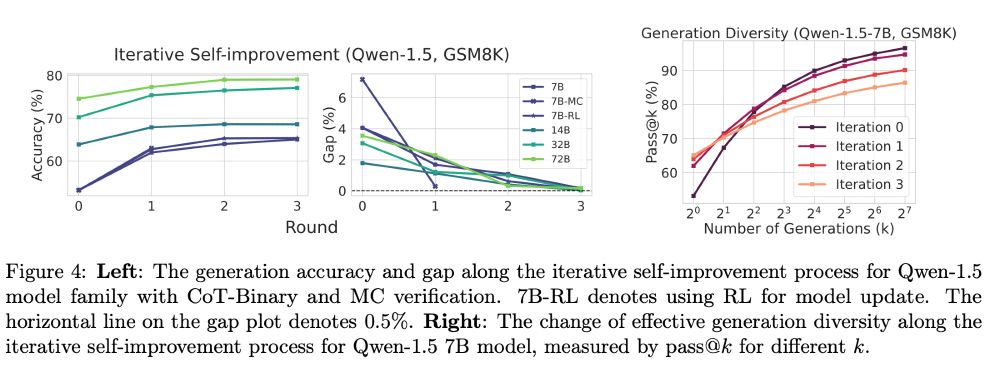
December 6, 2024 at 6:02 PM
In iterative self-improvement, we observe the gap diminishes to 0 in a few iterations, resembling many previous findings. We discovered that one cause of such saturation is the degradation of the "effective diversity" of the generation due to the imperfect verifier. (7/9)
However, self-improvement is not always possible on all tasks. We do not observe significant self-improvement signal on QA tasks like Natural Questions. Also, not all models can self-improve on sudoku, a canonical example of "verification is easier than generation". (6/9)
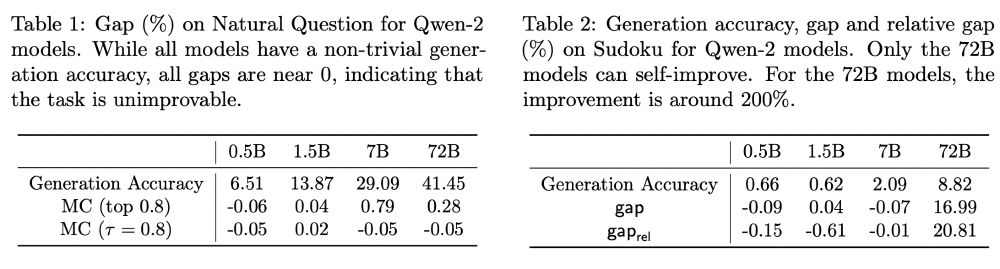
December 6, 2024 at 6:02 PM
However, self-improvement is not always possible on all tasks. We do not observe significant self-improvement signal on QA tasks like Natural Questions. Also, not all models can self-improve on sudoku, a canonical example of "verification is easier than generation". (6/9)
Our first major result is an observational scaling law: with certain verification methods, the relative gap increases monotonically (almost linear) to the log of pretrain flops, on tasks like GSM8K and MATH. (5/9)
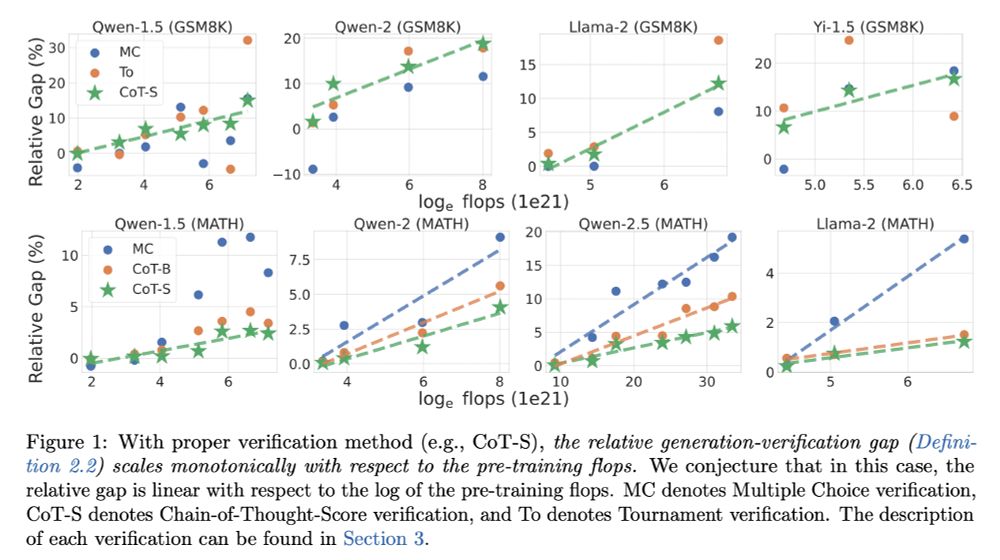
December 6, 2024 at 6:02 PM
Our first major result is an observational scaling law: with certain verification methods, the relative gap increases monotonically (almost linear) to the log of pretrain flops, on tasks like GSM8K and MATH. (5/9)
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
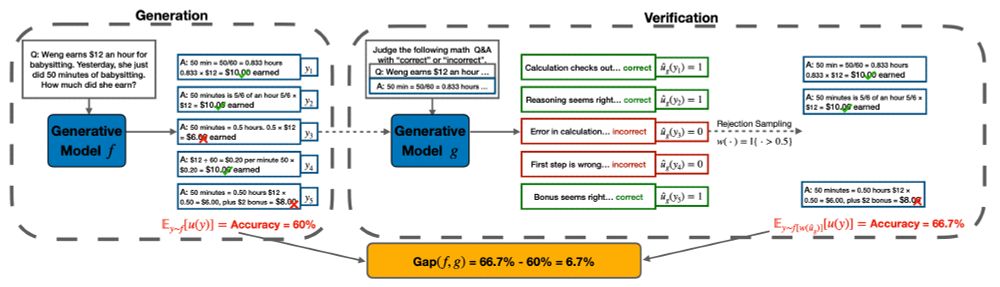
December 6, 2024 at 6:02 PM
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)