



Yuda Song
@yus167.bsky.social
PhD at Machine Learning Department, Carnegie Mellon University | Interactive Decision Making | https://yudasong.github.io
On Saturday I will present our LLM self-improvement paper in the workshop on Mathematics of Modern Machine Learning (M3L) and the workshop on Statistical Foundations of LLMs and Foundation Models (SFLLM).
bsky.app/profile/yus1...
bsky.app/profile/yus1...
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
December 9, 2024 at 7:49 PM
On Saturday I will present our LLM self-improvement paper in the workshop on Mathematics of Modern Machine Learning (M3L) and the workshop on Statistical Foundations of LLMs and Foundation Models (SFLLM).
bsky.app/profile/yus1...
bsky.app/profile/yus1...
Arxiv link for HyPO: arxiv.org/abs/2406.01462

The Importance of Online Data: Understanding Preference Fine-tuning via Coverage
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) ...
arxiv.org
December 9, 2024 at 7:49 PM
Arxiv link for HyPO: arxiv.org/abs/2406.01462
There are many more intriguing results that I can not fit into one post! For more details, please check out our paper: arxiv.org/abs/2412.02674. This is joint work with amazing collaborators Hanlin Zhang, Carson Eisenach, @shamkakade.bsky.social , Dean Foster and @ughai.bsky.social. (9/9)

Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights...
arxiv.org
December 6, 2024 at 6:02 PM
There are many more intriguing results that I can not fit into one post! For more details, please check out our paper: arxiv.org/abs/2412.02674. This is joint work with amazing collaborators Hanlin Zhang, Carson Eisenach, @shamkakade.bsky.social , Dean Foster and @ughai.bsky.social. (9/9)
We also dive deep into the similarity and difference between different verification mechanisms. We observed the consistency, distinction and ensemble properties of the verification methods (see the summary image). (8/9)

December 6, 2024 at 6:02 PM
We also dive deep into the similarity and difference between different verification mechanisms. We observed the consistency, distinction and ensemble properties of the verification methods (see the summary image). (8/9)
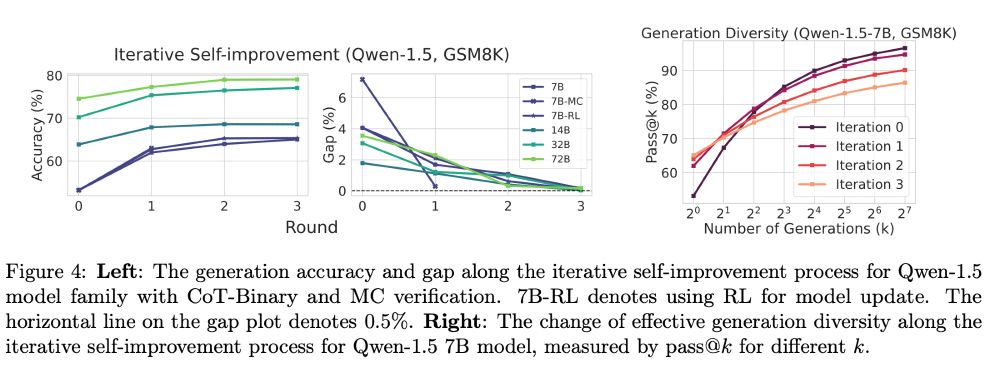
In iterative self-improvement, we observe the gap diminishes to 0 in a few iterations, resembling many previous findings. We discovered that one cause of such saturation is the degradation of the "effective diversity" of the generation due to the imperfect verifier. (7/9)
December 6, 2024 at 6:02 PM
In iterative self-improvement, we observe the gap diminishes to 0 in a few iterations, resembling many previous findings. We discovered that one cause of such saturation is the degradation of the "effective diversity" of the generation due to the imperfect verifier. (7/9)
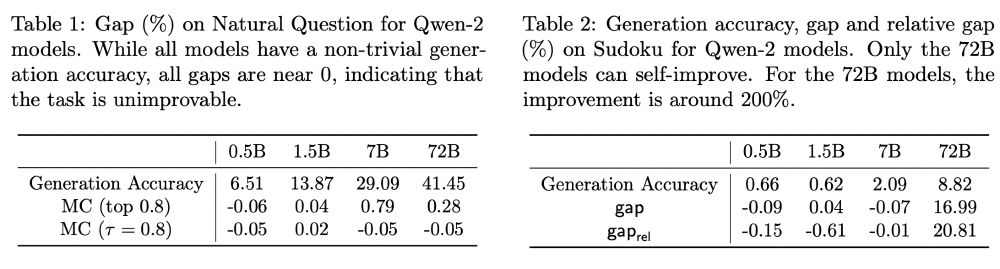
However, self-improvement is not always possible on all tasks. We do not observe significant self-improvement signal on QA tasks like Natural Questions. Also, not all models can self-improve on sudoku, a canonical example of "verification is easier than generation". (6/9)
December 6, 2024 at 6:02 PM
However, self-improvement is not always possible on all tasks. We do not observe significant self-improvement signal on QA tasks like Natural Questions. Also, not all models can self-improve on sudoku, a canonical example of "verification is easier than generation". (6/9)
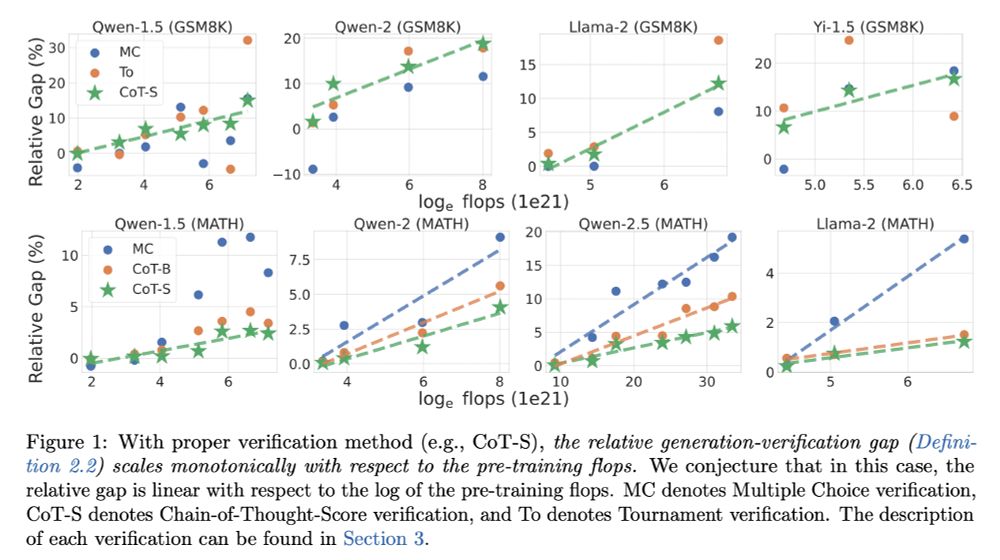
Our first major result is an observational scaling law: with certain verification methods, the relative gap increases monotonically (almost linear) to the log of pretrain flops, on tasks like GSM8K and MATH. (5/9)
December 6, 2024 at 6:02 PM
Our first major result is an observational scaling law: with certain verification methods, the relative gap increases monotonically (almost linear) to the log of pretrain flops, on tasks like GSM8K and MATH. (5/9)
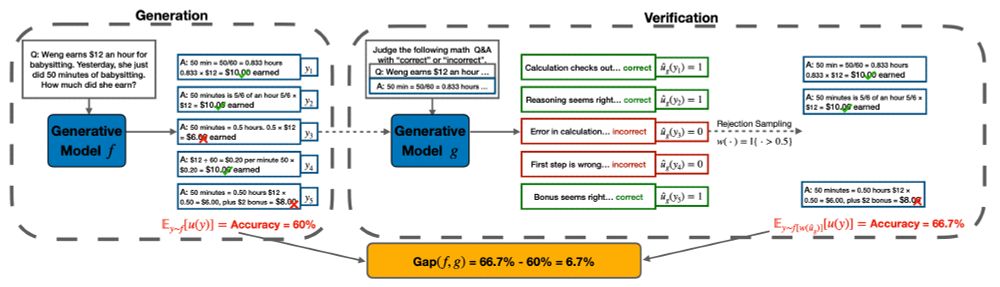
We propose to use the performance difference between the reweighted and original responses (2-1) -- the "generation-verification gap". We also study the relative gap -- gap weighted by the error rate. Intuitively, improvement is harder if the model makes fewer mistakes. (4/9)
December 6, 2024 at 6:02 PM
We propose to use the performance difference between the reweighted and original responses (2-1) -- the "generation-verification gap". We also study the relative gap -- gap weighted by the error rate. Intuitively, improvement is harder if the model makes fewer mistakes. (4/9)
While previous works measure self-improvement using the performance difference between the models (3-1), we found out that step 3 (distillation) introduces confounders (for example, the models can just be better at following certain formats). (3/9)
December 6, 2024 at 6:02 PM
While previous works measure self-improvement using the performance difference between the models (3-1), we found out that step 3 (distillation) introduces confounders (for example, the models can just be better at following certain formats). (3/9)
We study self-improvement as the following process:
1. Model generates many candidate responses.
2. Model filters/reweights responses based on its verifications.
3. Distill the reweighted responses into a new model.
(2/9)
1. Model generates many candidate responses.
2. Model filters/reweights responses based on its verifications.
3. Distill the reweighted responses into a new model.
(2/9)
December 6, 2024 at 6:02 PM
We study self-improvement as the following process:
1. Model generates many candidate responses.
2. Model filters/reweights responses based on its verifications.
3. Distill the reweighted responses into a new model.
(2/9)
1. Model generates many candidate responses.
2. Model filters/reweights responses based on its verifications.
3. Distill the reweighted responses into a new model.
(2/9)
Reposted by Yuda Song

I think the main difference in terms of interpolation / extrapolation between DPO and RLHF is that the former only guarantees closeness to the reference policy on the training data, while RLHF usually tacks on an on-policy KL penalty. We explored this point in arxiv.org/abs/2406.01462.
November 22, 2024 at 3:38 PM
I think the main difference in terms of interpolation / extrapolation between DPO and RLHF is that the former only guarantees closeness to the reference policy on the training data, while RLHF usually tacks on an on-policy KL penalty. We explored this point in arxiv.org/abs/2406.01462.