



@ycyiwei.bsky.social
Reposted

1/X Excited to present this preprint on multi-tasking, with
@david-g-clark.bsky.social and Ashok Litwin-Kumar! Timely too, as “low-D manifold” has been trending again. (If you read thru the end, we escape Flatland and return to the glorious high-D world we deserve.) www.biorxiv.org/content/10.6...
@david-g-clark.bsky.social and Ashok Litwin-Kumar! Timely too, as “low-D manifold” has been trending again. (If you read thru the end, we escape Flatland and return to the glorious high-D world we deserve.) www.biorxiv.org/content/10.6...

A theory of multi-task computation and task selection
Neural activity during the performance of a stereotyped behavioral task is often described as low-dimensional, occupying only a limited region in the space of all firing-rate patterns. This region has...
www.biorxiv.org
December 15, 2025 at 7:41 PM
1/X Excited to present this preprint on multi-tasking, with
@david-g-clark.bsky.social and Ashok Litwin-Kumar! Timely too, as “low-D manifold” has been trending again. (If you read thru the end, we escape Flatland and return to the glorious high-D world we deserve.) www.biorxiv.org/content/10.6...
@david-g-clark.bsky.social and Ashok Litwin-Kumar! Timely too, as “low-D manifold” has been trending again. (If you read thru the end, we escape Flatland and return to the glorious high-D world we deserve.) www.biorxiv.org/content/10.6...
Reposted

Want to make publication-ready figures come straight from Python without having to do any manual editing? Are you fed up with axes labels being unreadable during your presentations? Follow this short tutorial including code examples! 👇🧵

October 16, 2025 at 8:26 AM
Want to make publication-ready figures come straight from Python without having to do any manual editing? Are you fed up with axes labels being unreadable during your presentations? Follow this short tutorial including code examples! 👇🧵
Reposted

How does the brain find its way in realistic environments? 🧠 Using deep RL and neural data, we show that hippocampal-like networks support navigation, learning, and generalisation in partially observable environments—mirroring real animal behaviour. Now out:
www.nature.com/articles/s41...
#neuroAI
www.nature.com/articles/s41...
#neuroAI

Hippocampus supports multi-task reinforcement learning under partial observability - Nature Communications
Neural mechanisms underlying reinforcement learning in naturalistic environments are not fully understood. Here authors show that reinforcement learning (RL) agents with hippocampal-like recurrence, u...
www.nature.com
November 3, 2025 at 10:20 AM
How does the brain find its way in realistic environments? 🧠 Using deep RL and neural data, we show that hippocampal-like networks support navigation, learning, and generalisation in partially observable environments—mirroring real animal behaviour. Now out:
www.nature.com/articles/s41...
#neuroAI
www.nature.com/articles/s41...
#neuroAI
Reposted

When neurons change, but behavior doesn’t: Excitability changes driving representational drift
New preprint of work with Christian Machens: www.biorxiv.org/content/10.1...
New preprint of work with Christian Machens: www.biorxiv.org/content/10.1...

Representational drift without synaptic plasticity
Neural computations support stable behavior despite relying on many dynamically changing biological processes. One such process is representational drift (RD), in which neurons' responses change over ...
www.biorxiv.org
July 29, 2025 at 2:02 PM
When neurons change, but behavior doesn’t: Excitability changes driving representational drift
New preprint of work with Christian Machens: www.biorxiv.org/content/10.1...
New preprint of work with Christian Machens: www.biorxiv.org/content/10.1...
Reposted

In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)
August 5, 2025 at 2:36 PM
In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
Reposted

Does the brain learn by gradient descent?
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
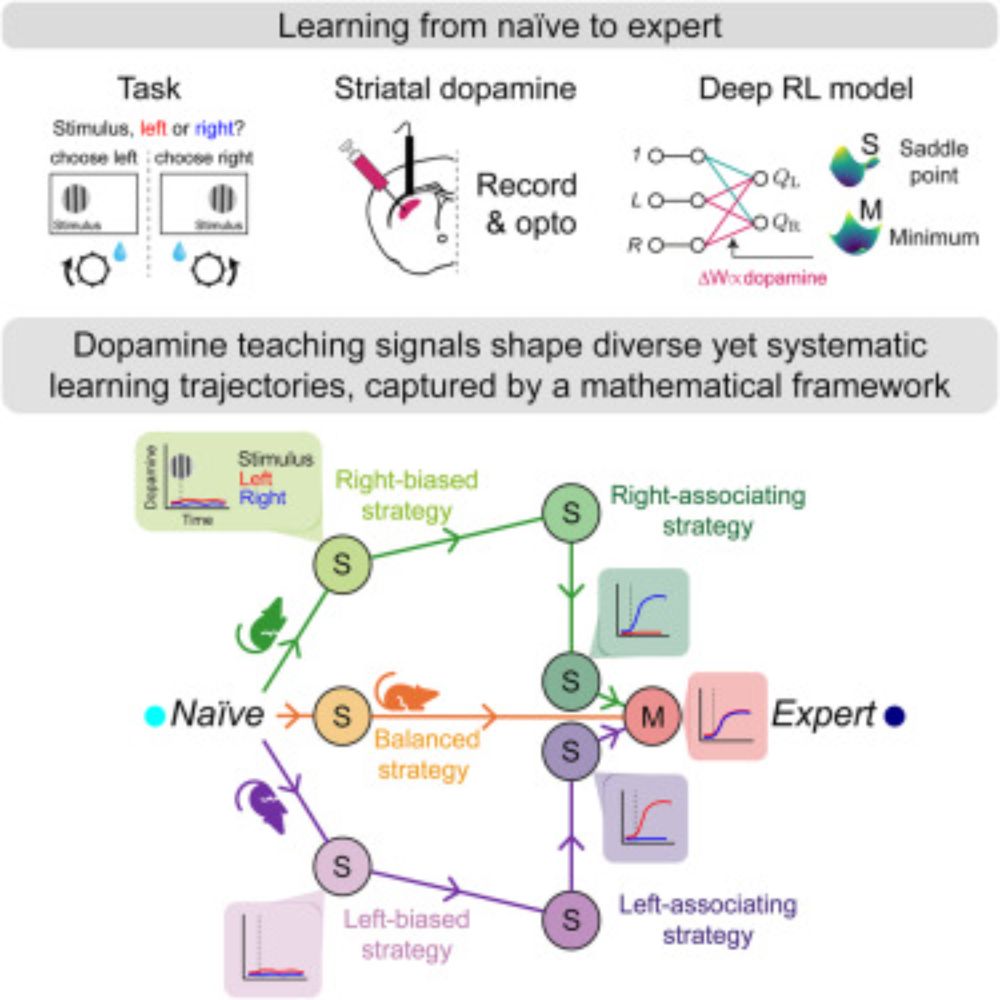
Dopamine encodes deep network teaching signals for individual learning trajectories
Longitudinal tracking of long-term learning behavior and striatal dopamine reveals
that dopamine teaching signals shape individually diverse yet systematic learning
trajectories, captured mathematical...
www.cell.com
June 15, 2025 at 9:33 AM
Does the brain learn by gradient descent?
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
Reposted

I continue to think interneuron circuits are an untapped inspiration in neural network design for context-dependent computation.

Feature-specific inhibitory connectivity augments the accuracy of cortical representations
To interpret complex sensory scenes, animals exploit statistical regularities to infer missing features and suppress redundant or ambiguous information. Cortical microcircuits might contribute to this...
www.biorxiv.org
August 5, 2025 at 12:05 PM
I continue to think interneuron circuits are an untapped inspiration in neural network design for context-dependent computation.
Reposted

I've seen people debating the answer to this on the internet so it's safe to say GPT5 achieves human-level intelligence

A simple benchmark.
Most people can understand it.
No PhD-level intelligence needed.
Most people can understand it.
No PhD-level intelligence needed.

August 10, 2025 at 5:03 PM
I've seen people debating the answer to this on the internet so it's safe to say GPT5 achieves human-level intelligence
Reposted

Is it possible to go from spikes to rates without averaging?
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.

From Spikes To Rates
YouTube video by Gerstner Lab
youtu.be
August 8, 2025 at 3:25 PM
Is it possible to go from spikes to rates without averaging?
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
Reposted

Check out our new review/perspective (w/ @juangallego.bsky.social & Devika Narain) on neural manifolds in the brain! It was a lot of fun to think through these ideas over the past couple of years, and I'm excited it's finally out in the world!
🔗: www.nature.com/articles/s41...
📄: rdcu.be/ex8hW
🔗: www.nature.com/articles/s41...
📄: rdcu.be/ex8hW
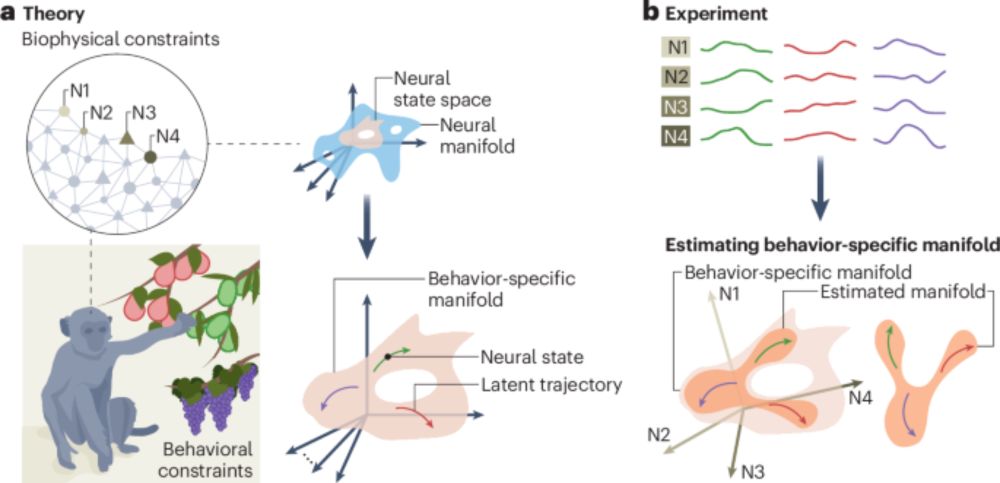
A neural manifold view of the brain - Nature Neuroscience
Recent advances in neuroscience have revealed how neural population activity underlying behavior can be well described by topological objects called neural manifolds. Understanding how nature, nurture...
www.nature.com
July 29, 2025 at 7:06 PM
Check out our new review/perspective (w/ @juangallego.bsky.social & Devika Narain) on neural manifolds in the brain! It was a lot of fun to think through these ideas over the past couple of years, and I'm excited it's finally out in the world!
🔗: www.nature.com/articles/s41...
📄: rdcu.be/ex8hW
🔗: www.nature.com/articles/s41...
📄: rdcu.be/ex8hW