



林煒清 | Wei-Ching Lin
@weiching-lin.bsky.social
data, data, and data
Reposted by 林煒清 | Wei-Ching Lin

Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵

July 1, 2025 at 3:41 PM
Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵
Reposted by 林煒清 | Wei-Ching Lin

Introducing Bases, a new core plugin that lets you turn any set of notes into a powerful database. With Bases you can organize everything from projects to travel plans, reading lists, and more.
Bases are now available in Obsidian 1.9.0 for early access users.
Bases are now available in Obsidian 1.9.0 for early access users.
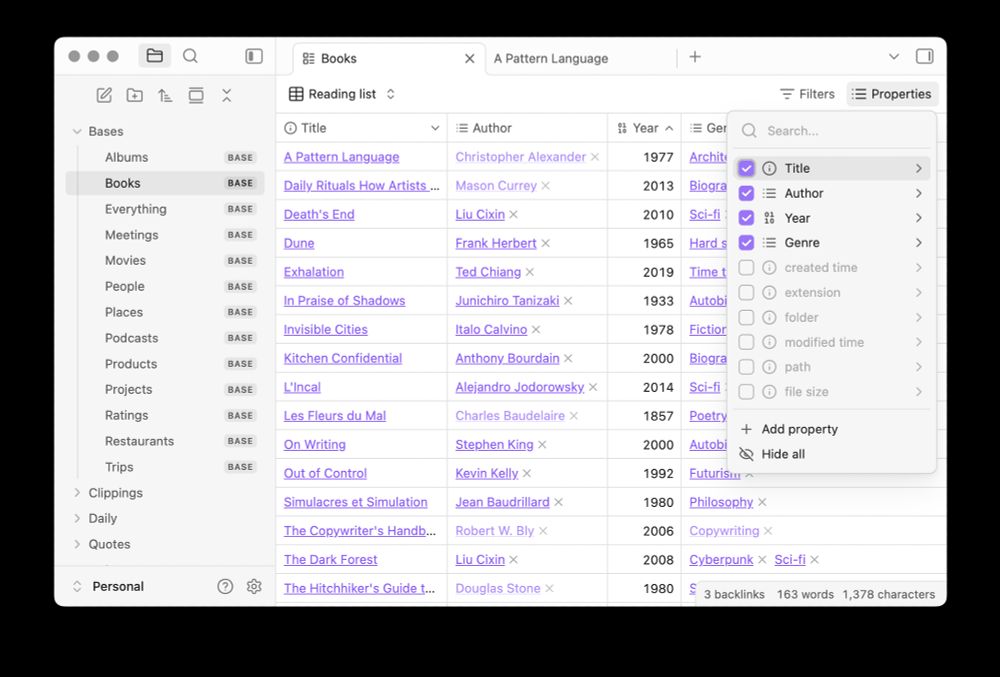
May 21, 2025 at 3:29 PM
Introducing Bases, a new core plugin that lets you turn any set of notes into a powerful database. With Bases you can organize everything from projects to travel plans, reading lists, and more.
Bases are now available in Obsidian 1.9.0 for early access users.
Bases are now available in Obsidian 1.9.0 for early access users.
Reposted by 林煒清 | Wei-Ching Lin

New blogpost: "Training as we know it might end".
It was originally a panorama of the new methods of synthetic generation but the stakes are now much higher and I openly wonder if model training is not soon going to change forever. vintagedata.org/blog/posts/t...
It was originally a panorama of the new methods of synthetic generation but the stakes are now much higher and I openly wonder if model training is not soon going to change forever. vintagedata.org/blog/posts/t...

May 8, 2025 at 8:02 PM
New blogpost: "Training as we know it might end".
It was originally a panorama of the new methods of synthetic generation but the stakes are now much higher and I openly wonder if model training is not soon going to change forever. vintagedata.org/blog/posts/t...
It was originally a panorama of the new methods of synthetic generation but the stakes are now much higher and I openly wonder if model training is not soon going to change forever. vintagedata.org/blog/posts/t...
Reposted by 林煒清 | Wei-Ching Lin

Interested in machine learning in science?
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com




November 15, 2024 at 9:46 AM
Interested in machine learning in science?
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Reposted by 林煒清 | Wei-Ching Lin

o3 can't multiply beyond a few digits...
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply


February 13, 2025 at 1:33 PM
o3 can't multiply beyond a few digits...
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
But I think multiplication, addition, maze solving and easy-to-hard generalization is actually solvable on standard transformers...
with recursive self-improvement
Below is the acc of a tiny model teaching itself how to add and multiply
Reposted by 林煒清 | Wei-Ching Lin

one of the doc info extraction tools in my newsletter yesterday just posted this rich example, with a flexible ui for exploring the data www.docetl.org/showcase/ai-...
DocETL
Powering complex document processing pipelines
www.docetl.org
May 2, 2025 at 6:25 AM
one of the doc info extraction tools in my newsletter yesterday just posted this rich example, with a flexible ui for exploring the data www.docetl.org/showcase/ai-...
Reposted by 林煒清 | Wei-Ching Lin

ChatGPT's recent update caused the model to be unbearably sycophantic - this has now been fixed through an update to the system prompt, and as far as I can tell this is what they changed simonwillison.net/2025/Apr/29/...

April 29, 2025 at 2:34 AM
ChatGPT's recent update caused the model to be unbearably sycophantic - this has now been fixed through an update to the system prompt, and as far as I can tell this is what they changed simonwillison.net/2025/Apr/29/...
Reposted by 林煒清 | Wei-Ching Lin

I often get asked: How did I start writing? Why do I write? Who do I write for? What's my process?
I procrastinated on this because, honestly, who cares about my writing process? But after repeatedly answering the same qns, I finally wrote this.
eugeneyan.com/writing/writ...
I procrastinated on this because, honestly, who cares about my writing process? But after repeatedly answering the same qns, I finally wrote this.
eugeneyan.com/writing/writ...
Frequently Asked Questions about My Writing Process
How I started, why I write, who I write for, how I write, and more.
eugeneyan.com
April 2, 2025 at 2:06 AM
I often get asked: How did I start writing? Why do I write? Who do I write for? What's my process?
I procrastinated on this because, honestly, who cares about my writing process? But after repeatedly answering the same qns, I finally wrote this.
eugeneyan.com/writing/writ...
I procrastinated on this because, honestly, who cares about my writing process? But after repeatedly answering the same qns, I finally wrote this.
eugeneyan.com/writing/writ...
Reposted by 林煒清 | Wei-Ching Lin

We used Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papers
Generate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one click
Understand papers in minutes - not hours
Generate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one click
Understand papers in minutes - not hours
March 14, 2025 at 6:41 PM
We used Mistral OCR with Claude 3.7 to create blog-style overviews for arXiv papers
Generate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one click
Understand papers in minutes - not hours
Generate beautiful research blogs with figures, key insights, and clear explanations from the paper with just one click
Understand papers in minutes - not hours
Reposted by 林煒清 | Wei-Ching Lin

Rec systems without user controls are a disaster for human agency and the sooner they go away the better
March 8, 2025 at 8:19 PM
Rec systems without user controls are a disaster for human agency and the sooner they go away the better
Reposted by 林煒清 | Wei-Ching Lin

I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century"
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
March 6, 2025 at 1:03 PM
I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century"
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Reposted by 林煒清 | Wei-Ching Lin

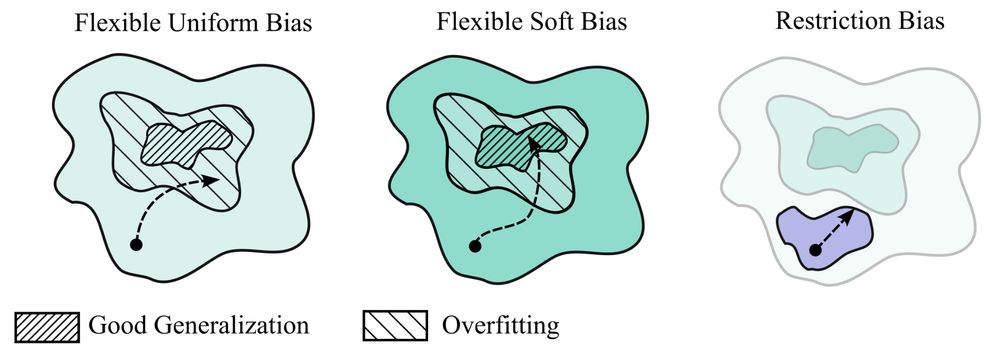
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
March 5, 2025 at 3:38 PM
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
Reposted by 林煒清 | Wei-Ching Lin

For my last class this semester, I tried to cram our Advanced Database course into one lecture. We cover the following database systems in 60min: youtu.be/fr5lIchF6pw
• Google Dremel / BigQuery
• Snowflake
• Amazon Redshift
• Yellowbrick
• Databricks Photon
• @duckdb.org
• TabDB
• Google Dremel / BigQuery
• Snowflake
• Amazon Redshift
• Yellowbrick
• Databricks Photon
• @duckdb.org
• TabDB

#25 - BigQuery + Snowflake + Redshift + Databricks + DuckDB (CMU Intro to Database Systems)
YouTube video by CMU Database Group
youtu.be
December 5, 2024 at 10:39 PM
For my last class this semester, I tried to cram our Advanced Database course into one lecture. We cover the following database systems in 60min: youtu.be/fr5lIchF6pw
• Google Dremel / BigQuery
• Snowflake
• Amazon Redshift
• Yellowbrick
• Databricks Photon
• @duckdb.org
• TabDB
• Google Dremel / BigQuery
• Snowflake
• Amazon Redshift
• Yellowbrick
• Databricks Photon
• @duckdb.org
• TabDB
Reposted by 林煒清 | Wei-Ching Lin

In this week’s Gradient Updates issue Matthew Barnett, argues that reasoning models will enable superhuman capabilities in “pure reasoning tasks” such as mathematics and abstract problem-solving. But, he predicts that this won’t be very economically valuable.

February 28, 2025 at 9:51 PM
In this week’s Gradient Updates issue Matthew Barnett, argues that reasoning models will enable superhuman capabilities in “pure reasoning tasks” such as mathematics and abstract problem-solving. But, he predicts that this won’t be very economically valuable.
Reposted by 林煒清 | Wei-Ching Lin

Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...

Distiling DeepSeek reasoning to ModernBERT classifiers
How can we use the reasoning ability of DeepSeek to generate synthetic labels for fine tuning a ModernBERT model?
danielvanstrien.xyz
January 29, 2025 at 10:07 AM
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Reposted by 林煒清 | Wei-Ching Lin

apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...

jiayipan
Weights & Biases, developer tools for machine learning
wandb.ai
January 25, 2025 at 6:46 PM
apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
Reposted by 林煒清 | Wei-Ching Lin
GRPO — Group Rewards Policy Optimization
with r1-zero, they took qwen and applied GRPO and only GRPO and got a model that does self-reflection (!!)
i'm learning this too, so let me take a whack at this...
with r1-zero, they took qwen and applied GRPO and only GRPO and got a model that does self-reflection (!!)
i'm learning this too, so let me take a whack at this...
January 21, 2025 at 3:52 PM
GRPO — Group Rewards Policy Optimization
with r1-zero, they took qwen and applied GRPO and only GRPO and got a model that does self-reflection (!!)
i'm learning this too, so let me take a whack at this...
with r1-zero, they took qwen and applied GRPO and only GRPO and got a model that does self-reflection (!!)
i'm learning this too, so let me take a whack at this...
Reposted by 林煒清 | Wei-Ching Lin
To this day, the Interpretable Machine Learning book is still my most impactful project. But as time went on, I dreaded working on it. Fortunately, I found the motivation again and I'm working on the 3rd edition. 😁
Read more here:
Read more here:

Why I almost stopped working on Interpretable Machine Learning
7 years ago I started writing the book Interpretable Machine Learning.
buff.ly
January 21, 2025 at 2:38 PM
To this day, the Interpretable Machine Learning book is still my most impactful project. But as time went on, I dreaded working on it. Fortunately, I found the motivation again and I'm working on the 3rd edition. 😁
Read more here:
Read more here:
Reposted by 林煒清 | Wei-Ching Lin

We are now done with all classes for CMU CS11-711 Advanced NLP!
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Schedule
The weekly event schedule.
phontron.com
November 27, 2024 at 10:26 PM
We are now done with all classes for CMU CS11-711 Advanced NLP!
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Reposted by 林煒清 | Wei-Ching Lin

10 short videos about LLM infrastructure to help you appreciate Pages 12-18 of the DeepSeek-v3 paper (arxiv.org/abs/2412.19437)
www.youtube.com/watch?v=76gu...
www.youtube.com/watch?v=76gu...

Flash LLMs: Pipeline Parallel
YouTube video by Sasha Rush 🤗
www.youtube.com
January 7, 2025 at 3:01 PM
10 short videos about LLM infrastructure to help you appreciate Pages 12-18 of the DeepSeek-v3 paper (arxiv.org/abs/2412.19437)
www.youtube.com/watch?v=76gu...
www.youtube.com/watch?v=76gu...
Reposted by 林煒清 | Wei-Ching Lin

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
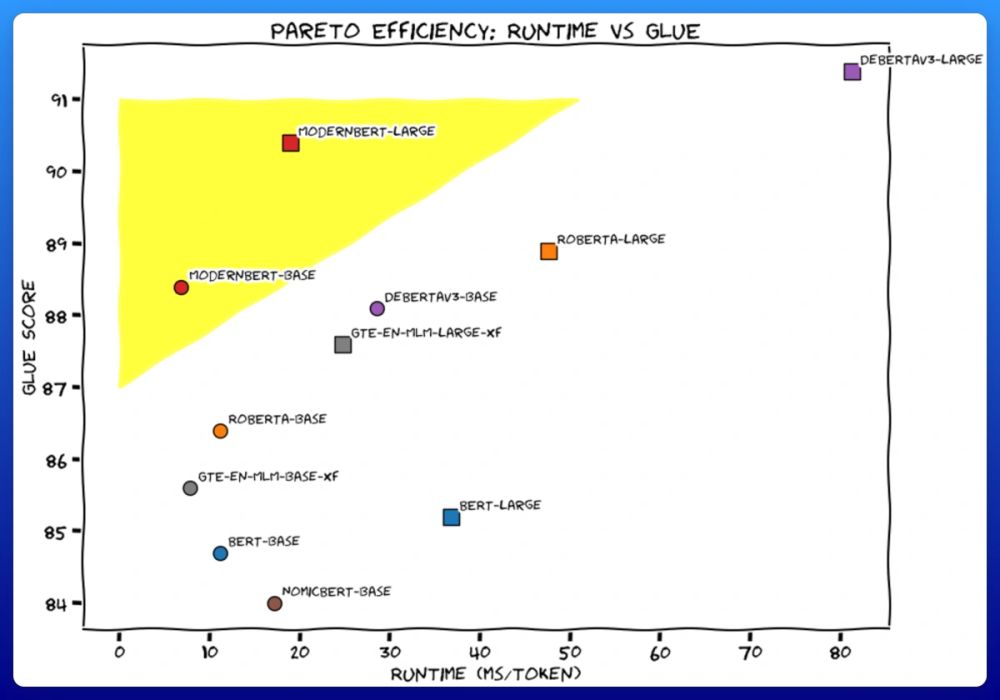
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted by 林煒清 | Wei-Ching Lin

We're going live in a bit with a new livestream. In this one we're giving ModernBERT a spin. It is very early days for the project, but there are some interesting milestones already.
Join here at 12:30 CET:
youtube.com/live/ZWo6Q85...
Join here at 12:30 CET:
youtube.com/live/ZWo6Q85...
YouTube
Share your videos with friends, family, and the world
youtube.com
January 10, 2025 at 9:37 AM
We're going live in a bit with a new livestream. In this one we're giving ModernBERT a spin. It is very early days for the project, but there are some interesting milestones already.
Join here at 12:30 CET:
youtube.com/live/ZWo6Q85...
Join here at 12:30 CET:
youtube.com/live/ZWo6Q85...
Reposted by 林煒清 | Wei-Ching Lin

Getting myself set up here. I found the Sky Follower Bridge Chrome plugin pretty helpful (thanks @kawamataryo.bsky.social!)
chromewebstore.google.com/detail/sky-f...
chromewebstore.google.com/detail/sky-f...

Sky Follower Bridge - Chrome Web Store
Easily transfer your following users and list members from X to Bluesky.
chromewebstore.google.com
January 5, 2025 at 10:51 PM
Getting myself set up here. I found the Sky Follower Bridge Chrome plugin pretty helpful (thanks @kawamataryo.bsky.social!)
chromewebstore.google.com/detail/sky-f...
chromewebstore.google.com/detail/sky-f...
Reposted by 林煒清 | Wei-Ching Lin
Buckle up because we're banging into the new year with my annual retrospective of the last year in databases! Highlights include license change blowback, Databricks vs. Snowflake gangwar, @duckdb.org's shotgun weddings, and buying a quarterback to impress your lover: www.cs.cmu.edu/~pavlo/blog/...

Databases in 2024: A Year in Review
Andy rises from the ashes of his dead startup and discusses what happened in 2024 in the database game.
www.cs.cmu.edu
January 1, 2025 at 2:02 PM
Buckle up because we're banging into the new year with my annual retrospective of the last year in databases! Highlights include license change blowback, Databricks vs. Snowflake gangwar, @duckdb.org's shotgun weddings, and buying a quarterback to impress your lover: www.cs.cmu.edu/~pavlo/blog/...
Reposted by 林煒清 | Wei-Ching Lin

It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
So far the blog post draft is winning the distraction battle. Prepare for a very long and opinionated update about all the new tools and apps I’ve been using for work.
Flight prep for someone who hates flying:
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
- Switch with Nine Sols loaded
- iPad with Black Doves loaded
- laptop with data, python notebook, blog post draft loaded
- silk eye mask
- REI inflatable neck pillow
- vitamin C juice
- Journey to the East by Hermann Hesse
- compression socks
- many snacks
December 31, 2024 at 5:38 AM
It's ready! 💫
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.
A new blog post in which I list of all the tools and apps I've been using for work, plus all my opinions about them.
maria-antoniak.github.io/2024/12/30/o...
Featuring @kagi.com, @warp.dev, @paperpile.bsky.social, @are.na, Fantastical, @obsidian.md, Claude, and more.