



Graham Neubig
@gneubig.bsky.social
Associate professor at CMU, studying natural language processing and machine learning. Co-founder All Hands AI
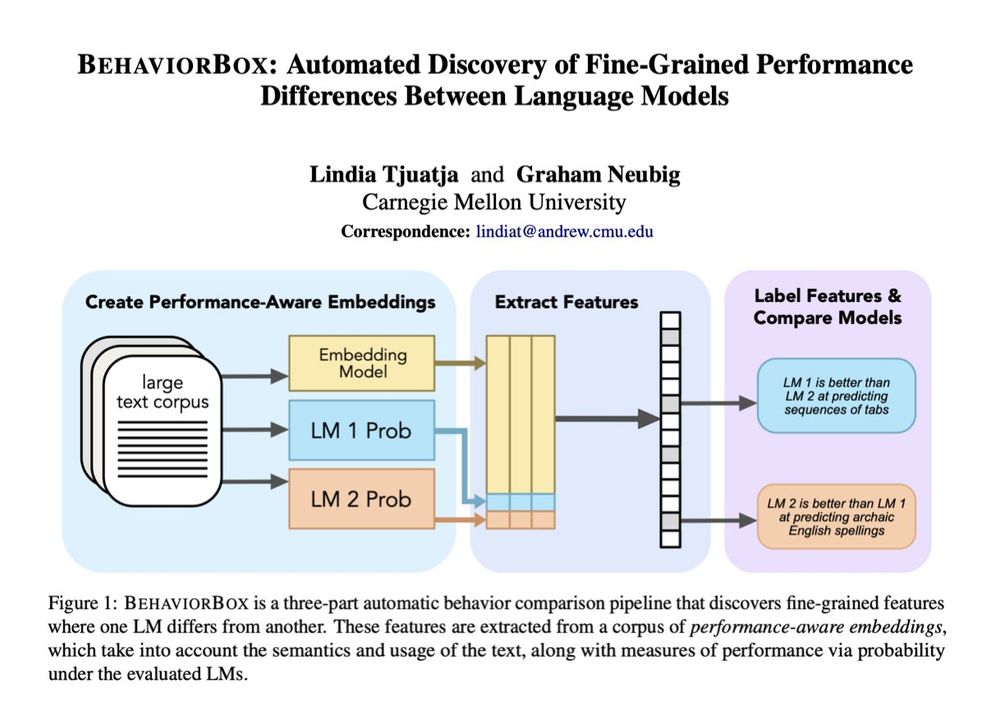
Where does one language model outperform the other?
We examine this from first principles, performing unsupervised discovery of "abilities" that one model has and the other does not.
Results show interesting differences between model classes, sizes and pre-/post-training.
We examine this from first principles, performing unsupervised discovery of "abilities" that one model has and the other does not.
Results show interesting differences between model classes, sizes and pre-/post-training.
When it comes to text prediction, where does one LM outperform another? If you've ever worked on LM evals, you know this question is a lot more complex than it seems. In our new #acl2025 paper, we developed a method to find fine-grained differences between LMs:
🧵1/9
🧵1/9
June 9, 2025 at 6:33 PM
Where does one language model outperform the other?
We examine this from first principles, performing unsupervised discovery of "abilities" that one model has and the other does not.
Results show interesting differences between model classes, sizes and pre-/post-training.
We examine this from first principles, performing unsupervised discovery of "abilities" that one model has and the other does not.
Results show interesting differences between model classes, sizes and pre-/post-training.
Reposted by Graham Neubig

Nice contribution to the understanding of Long CoT induction arxiv.org/abs/2502.03373 by Edward Yeo and colleagues (advised by @gneubig.bsky.social and @xiangyue96.bsky.social ). Its hard not to see this as mostly a negative result on induction on the 8B scale. 👇

Demystifying Long Chain-of-Thought Reasoning in LLMs
Scaling inference compute enhances reasoning in large language models (LLMs), with long chains-of-thought (CoTs) enabling strategies like backtracking and error correction. Reinforcement learning (RL)...
arxiv.org
February 8, 2025 at 7:29 PM
Nice contribution to the understanding of Long CoT induction arxiv.org/abs/2502.03373 by Edward Yeo and colleagues (advised by @gneubig.bsky.social and @xiangyue96.bsky.social ). Its hard not to see this as mostly a negative result on induction on the 8B scale. 👇
Reposted by Graham Neubig

LLM agents can code—but can they ask clarifying questions? 🤖💬
Tired of coding agents wasting time and API credits, only to output broken code? What if they asked first instead of guessing? 🚀
(New work led by Sanidhya Vijay: www.linkedin.com/in/sanidhya-...)
Tired of coding agents wasting time and API credits, only to output broken code? What if they asked first instead of guessing? 🚀
(New work led by Sanidhya Vijay: www.linkedin.com/in/sanidhya-...)

February 19, 2025 at 7:46 PM
LLM agents can code—but can they ask clarifying questions? 🤖💬
Tired of coding agents wasting time and API credits, only to output broken code? What if they asked first instead of guessing? 🚀
(New work led by Sanidhya Vijay: www.linkedin.com/in/sanidhya-...)
Tired of coding agents wasting time and API credits, only to output broken code? What if they asked first instead of guessing? 🚀
(New work led by Sanidhya Vijay: www.linkedin.com/in/sanidhya-...)
We are now done with all classes for CMU CS11-711 Advanced NLP!
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Schedule
The weekly event schedule.
phontron.com
November 27, 2024 at 10:26 PM
We are now done with all classes for CMU CS11-711 Advanced NLP!
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Slides: phontron.com/class/anlp-f...
Videos: youtube.com/playlist?lis...
Hope this is useful to people 😀
Reposted by Graham Neubig

1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
November 19, 2024 at 4:30 PM
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
Reposted by Graham Neubig

💬 Have you or a loved one compared LM probabilities to human linguistic acceptability judgments? You may be overcompensating for the effect of frequency and length!
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:

November 20, 2024 at 6:08 PM
💬 Have you or a loved one compared LM probabilities to human linguistic acceptability judgments? You may be overcompensating for the effect of frequency and length!
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵:
🌟 In our new paper, we rethink how we should be controlling for these factors 🧵: