




Andrew Gordon Wilson
@andrewgwils.bsky.social
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
https://cims.nyu.edu/~andrewgw
Reposted by Andrew Gordon Wilson

One of the underrated papers this year:
"Small Batch Size Training for Language Models:
When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (arxiv.org/abs/2507.07101)
(I can confirm this holds for RLVR, too! I have some experiments to share soon.)
"Small Batch Size Training for Language Models:
When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (arxiv.org/abs/2507.07101)
(I can confirm this holds for RLVR, too! I have some experiments to share soon.)

December 29, 2025 at 3:52 PM
One of the underrated papers this year:
"Small Batch Size Training for Language Models:
When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (arxiv.org/abs/2507.07101)
(I can confirm this holds for RLVR, too! I have some experiments to share soon.)
"Small Batch Size Training for Language Models:
When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (arxiv.org/abs/2507.07101)
(I can confirm this holds for RLVR, too! I have some experiments to share soon.)
Excited about our new paper that unifies discrete, Gaussian, and simplicial diffusion, enabling model comparison, likelihood evaluation, stable training, and more, including a DNA design application! Amazing work from @alannawzadamin.bsky.social, Alina, Lily, and team! arxiv.org/abs/2512.15923

A Unification of Discrete, Gaussian, and Simplicial Diffusion
To model discrete sequences such as DNA, proteins, and language using diffusion, practitioners must choose between three major methods: diffusion in discrete space, Gaussian diffusion in Euclidean spa...
arxiv.org
December 20, 2025 at 9:23 PM
Excited about our new paper that unifies discrete, Gaussian, and simplicial diffusion, enabling model comparison, likelihood evaluation, stable training, and more, including a DNA design application! Amazing work from @alannawzadamin.bsky.social, Alina, Lily, and team! arxiv.org/abs/2512.15923
Reposted by Andrew Gordon Wilson

Thrilled to start 2026 as faculty in Psych & CS
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
December 6, 2025 at 7:26 PM
Thrilled to start 2026 as faculty in Psych & CS
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
@ualberta.bsky.social + Amii.ca Fellow! 🥳 Recruiting students to develop theories of cognition in natural & artificial systems 🤖💭🧠. Find me at #NeurIPS2025 workshops (speaking coginterp.github.io/neurips2025 & organising @dataonbrainmind.bsky.social)
Excited to be speaking at the SPIGM workshop at NeurIPS tomorrow, 10:30-11 am, Room 20C. My talk will be "Probabilistic Inference is the Future of Foundation Models". See you there! spigmworkshopv3.github.io/schedule/

December 6, 2025 at 2:06 AM
Excited to be speaking at the SPIGM workshop at NeurIPS tomorrow, 10:30-11 am, Room 20C. My talk will be "Probabilistic Inference is the Future of Foundation Models". See you there! spigmworkshopv3.github.io/schedule/
A nice list. But, it doesn't actually go much beyond electronics. In terms of quality of life, I think some of these "conveniences" are a downgrade in practice. I miss blockbuster. I miss watching my favourite shows when they aired on a TV schedule. I miss 90s gaming. I miss being able to unplug.

Lot of people should read this exhaustive list of life improvements from the 90s: gwern.net/improvement

My Ordinary Life: Improvements Since the 1990s
A list of unheralded improvements to ordinary quality-of-life since the 1990s going beyond computers.
gwern.net
October 12, 2025 at 9:06 PM
A nice list. But, it doesn't actually go much beyond electronics. In terms of quality of life, I think some of these "conveniences" are a downgrade in practice. I miss blockbuster. I miss watching my favourite shows when they aired on a TV schedule. I miss 90s gaming. I miss being able to unplug.
My full interview with MLStreetTalk has just been posted. I really enjoyed this conversation! We talk about the bitter lesson, scientific discovery, Bayesian inference, mysterious phenomena, and key principles for building intelligent systems. www.youtube.com/watch?v=M-jT...

The Real Reason Huge AI Models Actually Work
YouTube video by Machine Learning Street Talk
www.youtube.com
September 23, 2025 at 5:40 PM
My full interview with MLStreetTalk has just been posted. I really enjoyed this conversation! We talk about the bitter lesson, scientific discovery, Bayesian inference, mysterious phenomena, and key principles for building intelligent systems. www.youtube.com/watch?v=M-jT...
I'm excited to be giving a keynote talk at the AutoML conference 9-10 am at Cornell Tech tomorrow! I'm presenting "Prescriptions for Universal Learning". I'll talk about how we can enable automation, which I'll argue is the defining feature of ML. 2025.automl.cc/program/

September 9, 2025 at 1:27 PM
I'm excited to be giving a keynote talk at the AutoML conference 9-10 am at Cornell Tech tomorrow! I'm presenting "Prescriptions for Universal Learning". I'll talk about how we can enable automation, which I'll argue is the defining feature of ML. 2025.automl.cc/program/
Research doesn't go in circles, but in spirals. We return to the same ideas, but in a different and augmented form.
September 1, 2025 at 6:45 PM
Research doesn't go in circles, but in spirals. We return to the same ideas, but in a different and augmented form.
Reposted by Andrew Gordon Wilson

CDS/Courant Professor Andrew Gordon Wilson (@andrewgwils.bsky.social) argues mysterious behavior in deep learning can be explained by decades-old theory, not new paradigms: PAC-Bayes bounds, soft biases, and large models with a soft simplicity bias.
nyudatascience.medium.com/deep-learnin...
nyudatascience.medium.com/deep-learnin...

Deep Learning’s Most Puzzling Phenomena Can Be Explained by Decades-Old Theory
Andrew Gordon Wilson argues that many generalization phenomena in deep learning can be explained using decades-old theoretical tools.
nyudatascience.medium.com
August 27, 2025 at 2:46 PM
CDS/Courant Professor Andrew Gordon Wilson (@andrewgwils.bsky.social) argues mysterious behavior in deep learning can be explained by decades-old theory, not new paradigms: PAC-Bayes bounds, soft biases, and large models with a soft simplicity bias.
nyudatascience.medium.com/deep-learnin...
nyudatascience.medium.com/deep-learnin...
Regardless of whether you plan to use them in applications, everyone should learn about Gaussian processes, and Bayesian methods. They provide a foundation for reasoning about model construction and all sorts of deep learning behaviour that would otherwise appear mysterious.
August 9, 2025 at 2:42 PM
Regardless of whether you plan to use them in applications, everyone should learn about Gaussian processes, and Bayesian methods. They provide a foundation for reasoning about model construction and all sorts of deep learning behaviour that would otherwise appear mysterious.
A common takeaway from "the bitter lesson" is we don't need to put effort into encoding inductive biases, we just need compute. Nothing could be further from the truth! Better inductive biases mean better scaling exponents, which means exponential improvements with computation.
August 8, 2025 at 1:47 PM
A common takeaway from "the bitter lesson" is we don't need to put effort into encoding inductive biases, we just need compute. Nothing could be further from the truth! Better inductive biases mean better scaling exponents, which means exponential improvements with computation.
Gould mostly recorded baroque and early classical. He only recorded a single Chopin piece, as a one-off broadcast. But like many of his efforts, it's profoundly thought provoking, the end product as much Gould as it is Chopin. I love the last mvt (20:55+). www.youtube.com/watch?v=NAHE...

Glenn Gould plays Chopin Piano Sonata No. 3 in B minor Op.58
YouTube video by The Piano Experience
www.youtube.com
July 29, 2025 at 5:44 PM
Gould mostly recorded baroque and early classical. He only recorded a single Chopin piece, as a one-off broadcast. But like many of his efforts, it's profoundly thought provoking, the end product as much Gould as it is Chopin. I love the last mvt (20:55+). www.youtube.com/watch?v=NAHE...
Whatever you do, just don't be boring.
July 28, 2025 at 11:19 PM
Whatever you do, just don't be boring.
I had a great time presenting "It's Time to Say Goodbye to Hard Constraints" at the Flatiron Institute. In this talk, I describe a philosophy for model construction in machine learning. Video now online! www.youtube.com/watch?v=LxuN...

It's Time to Say Goodbye to Hard (equivariance) Constraints - Andrew Gordon Wilson
YouTube video by LoG Meetup NYC
www.youtube.com
July 22, 2025 at 7:28 PM
I had a great time presenting "It's Time to Say Goodbye to Hard Constraints" at the Flatiron Institute. In this talk, I describe a philosophy for model construction in machine learning. Video now online! www.youtube.com/watch?v=LxuN...
Excited to be presenting my paper "Deep Learning is Not So Mysterious or Different" tomorrow at ICML, 11 am - 1:30 pm, East Exhibition Hall A-B, E-500. I made a little video overview as part of the ICML process (viewable from Chrome): recorder-v3.slideslive.com#/share?share...
July 17, 2025 at 12:16 AM
Excited to be presenting my paper "Deep Learning is Not So Mysterious or Different" tomorrow at ICML, 11 am - 1:30 pm, East Exhibition Hall A-B, E-500. I made a little video overview as part of the ICML process (viewable from Chrome): recorder-v3.slideslive.com#/share?share...
Our new ICML paper discovers scaling collapse: through a simple affine transformation, whole training loss curves across model sizes with optimally scaled hypers collapse to a single universal curve! We explain the collapse, providing a diagnostic for model scaling.
arxiv.org/abs/2507.02119
1/3
arxiv.org/abs/2507.02119
1/3
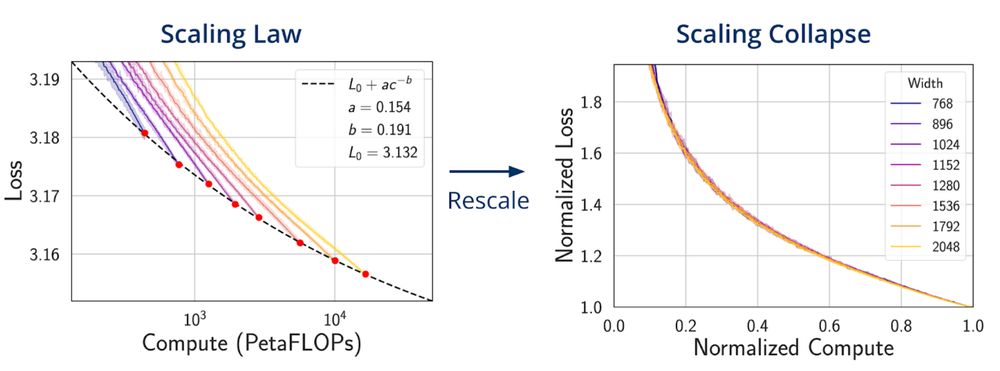
July 8, 2025 at 2:45 PM
Our new ICML paper discovers scaling collapse: through a simple affine transformation, whole training loss curves across model sizes with optimally scaled hypers collapse to a single universal curve! We explain the collapse, providing a diagnostic for model scaling.
arxiv.org/abs/2507.02119
1/3
arxiv.org/abs/2507.02119
1/3
Excited about our new ICML paper, showing how algebraic structure can be exploited for massive computational gains in population genetics.

We can make population genetics studies more powerful by building priors of variant effect size from features like binding. But we’ve been stuck on linear models! We introduce DeepWAS to learn deep priors on millions of variants! #ICML2025 Andres Potapczynski, @andrewgwils.bsky.social 1/7

June 25, 2025 at 2:06 PM
Excited about our new ICML paper, showing how algebraic structure can be exploited for massive computational gains in population genetics.
Machine learning is perhaps the only discipline that has become less mature over time. A reverse metamorphosis, from butterfly to caterpillar.
June 24, 2025 at 10:11 PM
Machine learning is perhaps the only discipline that has become less mature over time. A reverse metamorphosis, from butterfly to caterpillar.
AI this, AI that, the implications of AI for X... can we just never talk about AI again?
June 17, 2025 at 8:27 PM
AI this, AI that, the implications of AI for X... can we just never talk about AI again?
Really excited about our new paper, "Why Masking Diffusion Works: Condition on the Jump Schedule for Improved Discrete Diffusion". We explain the mysterious success of masking diffusion to propose new diffusion models that work well in a variety settings, including proteins, images, and text!
There are many domain-specific noise processes for discrete diffusion, but masking dominates! Why? We show masking exploits a key property of discrete diffusion, which we use to unlock the potential of those structured processes and beat masking! w/ Nate Gruver and @andrewgwils.bsky.social 1/7
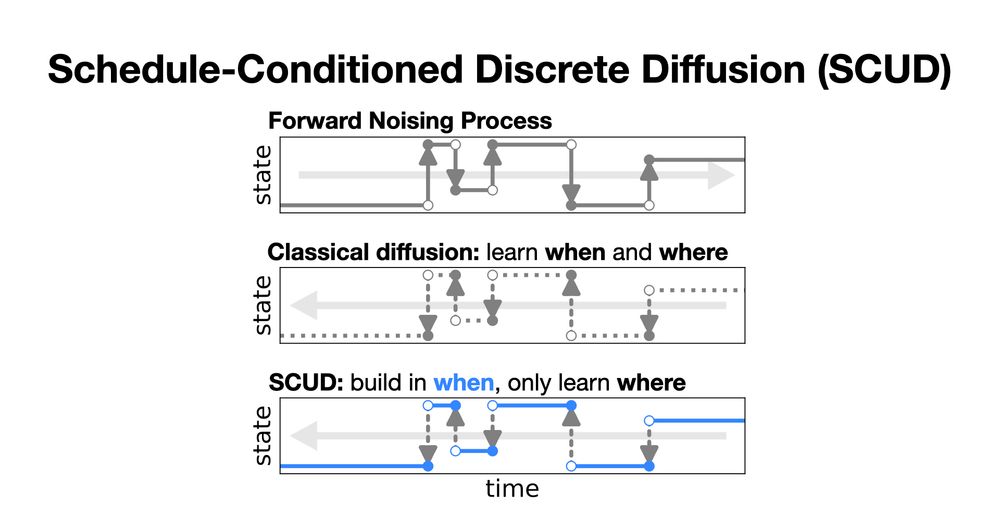
June 16, 2025 at 2:30 PM
Really excited about our new paper, "Why Masking Diffusion Works: Condition on the Jump Schedule for Improved Discrete Diffusion". We explain the mysterious success of masking diffusion to propose new diffusion models that work well in a variety settings, including proteins, images, and text!
A really outstanding interview of Terence Tao, providing an introduction to many topics, including the math of general relativity (youtube.com/watch?v=HUkB...). I love relativity, and in a recent(ish) paper we also consider the wave maps equation (section 5, arxiv.org/abs/2304.14994).

Terence Tao: Hardest Problems in Mathematics, Physics & the Future of AI | Lex Fridman Podcast #472
YouTube video by Lex Fridman
youtube.com
June 15, 2025 at 8:25 PM
A really outstanding interview of Terence Tao, providing an introduction to many topics, including the math of general relativity (youtube.com/watch?v=HUkB...). I love relativity, and in a recent(ish) paper we also consider the wave maps equation (section 5, arxiv.org/abs/2304.14994).
AI benchmarking culture is completely out of control. Tables with dozens of methods, datasets, and bold numbers, trying to answer a question that perhaps no one should be asking anymore.
May 30, 2025 at 9:55 PM
AI benchmarking culture is completely out of control. Tables with dozens of methods, datasets, and bold numbers, trying to answer a question that perhaps no one should be asking anymore.
We have a strong bias to overestimate the speed of technological innovation and impact. See past claims about autonomous driving, AI curing diseases... or the timeline in every sci-fi book ever written. Where is my flying car?
May 5, 2025 at 10:28 PM
We have a strong bias to overestimate the speed of technological innovation and impact. See past claims about autonomous driving, AI curing diseases... or the timeline in every sci-fi book ever written. Where is my flying car?
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
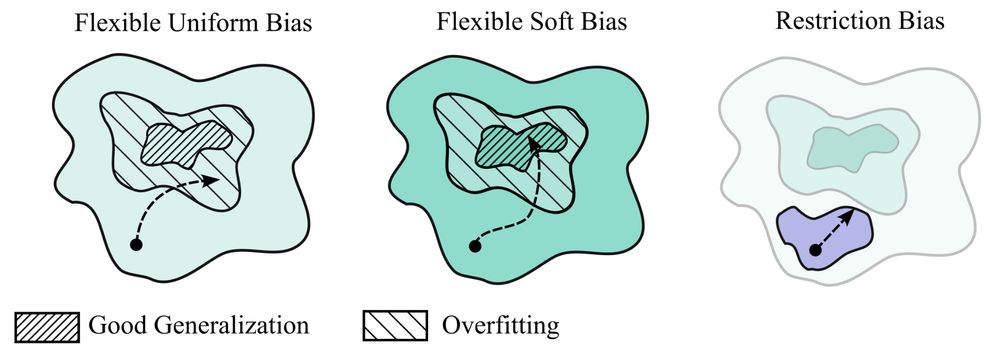
March 5, 2025 at 3:38 PM
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
I had a great time talking with @anilananth.bsky.social as part of the Simons Institute Polylogues. We cover universal learning, generalization phenomena, how transformers are both surprisingly general but also limited, and the difference between statistics and ML! www.youtube.com/watch?v=Aja0...

Andrew Gordon Wilson | Polylogues
YouTube video by Simons Institute
www.youtube.com
February 28, 2025 at 2:52 PM
I had a great time talking with @anilananth.bsky.social as part of the Simons Institute Polylogues. We cover universal learning, generalization phenomena, how transformers are both surprisingly general but also limited, and the difference between statistics and ML! www.youtube.com/watch?v=Aja0...