




Andrew Gordon Wilson
@andrewgwils.bsky.social
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
https://cims.nyu.edu/~andrewgw
I'm excited to be giving a keynote talk at the AutoML conference 9-10 am at Cornell Tech tomorrow! I'm presenting "Prescriptions for Universal Learning". I'll talk about how we can enable automation, which I'll argue is the defining feature of ML. 2025.automl.cc/program/

September 9, 2025 at 1:27 PM
I'm excited to be giving a keynote talk at the AutoML conference 9-10 am at Cornell Tech tomorrow! I'm presenting "Prescriptions for Universal Learning". I'll talk about how we can enable automation, which I'll argue is the defining feature of ML. 2025.automl.cc/program/
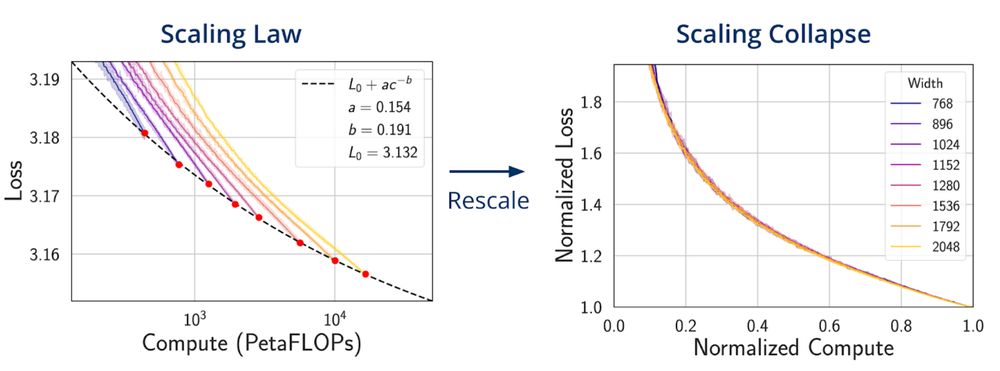
Our new ICML paper discovers scaling collapse: through a simple affine transformation, whole training loss curves across model sizes with optimally scaled hypers collapse to a single universal curve! We explain the collapse, providing a diagnostic for model scaling.
arxiv.org/abs/2507.02119
1/3
arxiv.org/abs/2507.02119
1/3
July 8, 2025 at 2:45 PM
Our new ICML paper discovers scaling collapse: through a simple affine transformation, whole training loss curves across model sizes with optimally scaled hypers collapse to a single universal curve! We explain the collapse, providing a diagnostic for model scaling.
arxiv.org/abs/2507.02119
1/3
arxiv.org/abs/2507.02119
1/3
The textbooks don't need to be rewritten -- they just needed to pay attention to what was already known about generalization, decades ago! I've had thoughts about this for 12 years, and people always ask for the paper -- so I finally wrote it. Thankful to many for feedback! 12/12

March 5, 2025 at 3:38 PM
The textbooks don't need to be rewritten -- they just needed to pay attention to what was already known about generalization, decades ago! I've had thoughts about this for 12 years, and people always ask for the paper -- so I finally wrote it. Thankful to many for feedback! 12/12
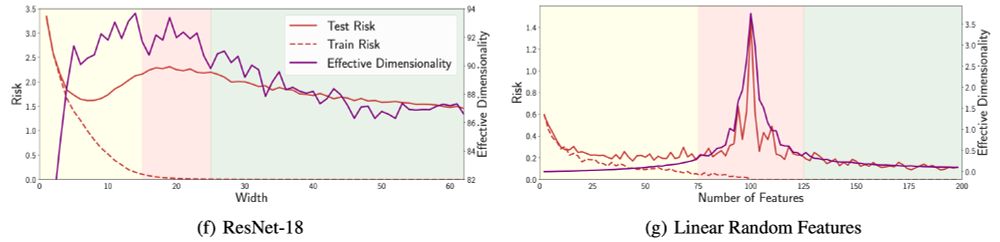
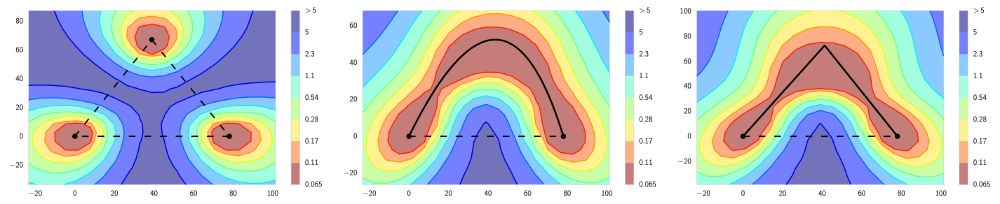
We also further consider overparametrization and double descent. Deep learning of course _is_ different, and much is not well understood. To this end, we particularly highlight representation learning, mode connectivity, and universal learning. Much more in the paper! 11/12
March 5, 2025 at 3:38 PM
We also further consider overparametrization and double descent. Deep learning of course _is_ different, and much is not well understood. To this end, we particularly highlight representation learning, mode connectivity, and universal learning. Much more in the paper! 11/12
Benign overfitting describes perfectly fitting a mix of signal and noise, but still generalizing respectably. Like with the polynomial, we can exactly reproduce this behaviour with a Gaussian process and bound it with PAC-Bayes through the marginal likelihood. 8/12

March 5, 2025 at 3:38 PM
Benign overfitting describes perfectly fitting a mix of signal and noise, but still generalizing respectably. Like with the polynomial, we can exactly reproduce this behaviour with a Gaussian process and bound it with PAC-Bayes through the marginal likelihood. 8/12
We can use a Solomonoff prior, which represents a maximally overparametrized model, but assigns exponentially higher weights to simpler (shorter) programs with lower Kolmogorov complexity, leading to non-vacuous generalization bounds on even billion parameter neural nets. 7/12

March 5, 2025 at 3:38 PM
We can use a Solomonoff prior, which represents a maximally overparametrized model, but assigns exponentially higher weights to simpler (shorter) programs with lower Kolmogorov complexity, leading to non-vacuous generalization bounds on even billion parameter neural nets. 7/12
While this behaviour cannot be explained by Rademacher complexity or VC dimension (which measures a model's ability to fit noise), it _can_ be described by decades-old countable hypothesis bounds with a prior, which do not penalize the size of the hypothesis space. 6/12

March 5, 2025 at 3:38 PM
While this behaviour cannot be explained by Rademacher complexity or VC dimension (which measures a model's ability to fit noise), it _can_ be described by decades-old countable hypothesis bounds with a prior, which do not penalize the size of the hypothesis space. 6/12
This model also performs well over a range of data sizes and complexities. But wait... a central observation in "understanding DL requires rethinking generalization" was a neural net can fit noise perfectly, but still generalize on structured data, just like this polynomial. 5/12

March 5, 2025 at 3:38 PM
This model also performs well over a range of data sizes and complexities. But wait... a central observation in "understanding DL requires rethinking generalization" was a neural net can fit noise perfectly, but still generalize on structured data, just like this polynomial. 5/12
Let's consider the simplest possible example: a polynomial. We’ll use an arbitrarily high-order polynomial with order-dependent regularization that penalizes the norms of higher order coefficients more. This model scales its complexity as needed, and can also fit pure noise! 4/12

March 5, 2025 at 3:38 PM
Let's consider the simplest possible example: a polynomial. We’ll use an arbitrarily high-order polynomial with order-dependent regularization that penalizes the norms of higher order coefficients more. This model scales its complexity as needed, and can also fit pure noise! 4/12
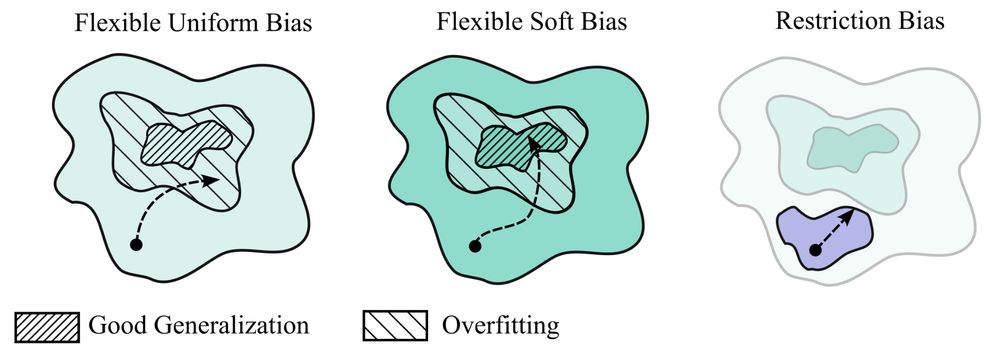
Rather than restricting the solutions a model can represent, specify a preference for certain solutions over others, through _soft_ inductive biases. This approach guides us towards structure where it exists, without significant penalty where it doesn't. 3/12

March 5, 2025 at 3:38 PM
Rather than restricting the solutions a model can represent, specify a preference for certain solutions over others, through _soft_ inductive biases. This approach guides us towards structure where it exists, without significant penalty where it doesn't. 3/12
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
March 5, 2025 at 3:38 PM
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
Nice crowd and lots of engagement at our NeurIPS poster today, with Sanae Lotfi presenting on token-level generalization bounds for LLMs! arxiv.org/abs/2407.18158

December 12, 2024 at 7:19 AM
Nice crowd and lots of engagement at our NeurIPS poster today, with Sanae Lotfi presenting on token-level generalization bounds for LLMs! arxiv.org/abs/2407.18158
Yes! It will exploit structure within matrices and compositions for better computational complexity. E.g., there may be an order of operations that is more efficient, or structure that leads to special algorithms that have better complexity. We explored multiplication in arxiv.org/abs/2406.06248.

December 8, 2024 at 6:01 PM
Yes! It will exploit structure within matrices and compositions for better computational complexity. E.g., there may be an order of operations that is more efficient, or structure that leads to special algorithms that have better complexity. We explored multiplication in arxiv.org/abs/2406.06248.
By combining a linear operator abstraction with compositional dispatch rules, CoLA accelerates algebraic operations, while making it easy to prototype matrix structures and algorithms. There is the potential to impact virtually any computational effort in ML and beyond, including your project! 3/4

December 5, 2024 at 3:15 PM
By combining a linear operator abstraction with compositional dispatch rules, CoLA accelerates algebraic operations, while making it easy to prototype matrix structures and algorithms. There is the potential to impact virtually any computational effort in ML and beyond, including your project! 3/4
I wanted to make my first post about a project close to my heart. Linear algebra is an underappreciated foundation for machine learning. Our new framework CoLA (Compositional Linear Algebra) exploits algebraic structure arising from modelling assumptions for significant computational savings! 1/4

December 5, 2024 at 3:15 PM
I wanted to make my first post about a project close to my heart. Linear algebra is an underappreciated foundation for machine learning. Our new framework CoLA (Compositional Linear Algebra) exploits algebraic structure arising from modelling assumptions for significant computational savings! 1/4