



Costa Huang
@vwxyzjn.bsky.social
RL + LLM @ai2.bsky.social; main dev of https://cleanrl.dev/
Congrats on the launch!

We're finally out of stealth: percepta.ai
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀
We're a research / engineering team working together in industries like health and logistics to ship ML tools that drastically improve productivity. If you're interested in ML and RL work that matters, come join us 😀

Percepta | A General Catalyst Transformation Company
Transforming critical institutions using applied AI. Let's harness the frontier.
percepta.ai
October 2, 2025 at 5:43 PM
Congrats on the launch!
🥘 Excited to share our latest OLMo 1 B models! Almost summer RL time. We did another two-stage RL:
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵

May 1, 2025 at 1:21 PM
🥘 Excited to share our latest OLMo 1 B models! Almost summer RL time. We did another two-stage RL:
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!

March 13, 2025 at 7:19 PM
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:33 PM
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
🤯 Check out our new iOS OLMoE app that runs the model on-device!
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵

February 11, 2025 at 3:30 PM
🤯 Check out our new iOS OLMoE app that runs the model on-device!
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
I nerd-snipped myself over the @deepseek.bsky.social GRPO's usage of John Schulman's kl3 estimator. I can now see why:
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).

January 31, 2025 at 3:21 PM
I nerd-snipped myself over the @deepseek.bsky.social GRPO's usage of John Schulman's kl3 estimator. I can now see why:
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
We released the OLMo 2 report! Ready for some more RL curves? 😏
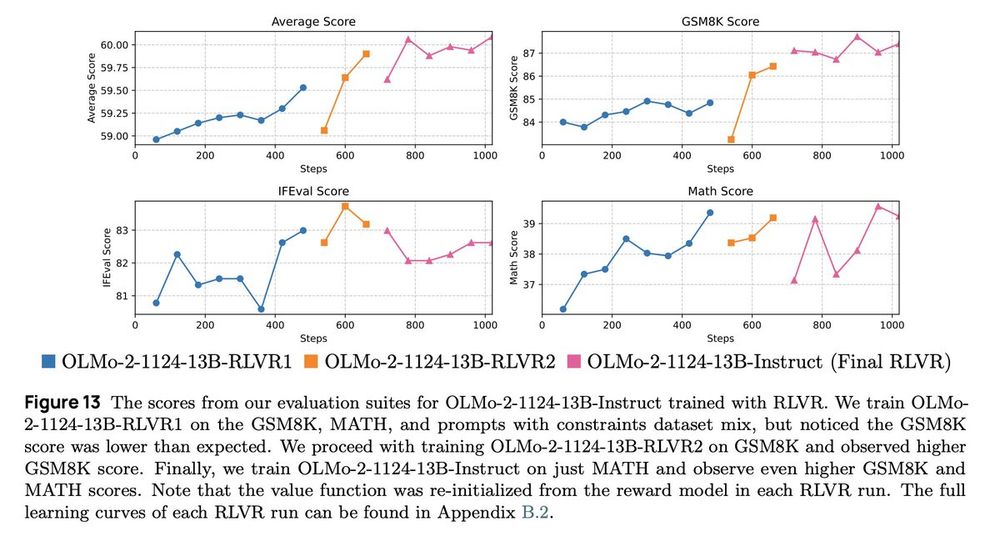
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
January 6, 2025 at 6:34 PM
We released the OLMo 2 report! Ready for some more RL curves? 😏
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
Reposted by Costa Huang

Maybe my favorite unexpected crossover model from the community.
SmolLM from HuggingFace trained with part of the Tülu 3 recipe we release a month ago :D.
Cool numerical explorations of post-training stuff. Nothing crazy.
SultanR/SmolTulu-1.7b-Instruct
https://buff.ly/41Epauv
SmolLM from HuggingFace trained with part of the Tülu 3 recipe we release a month ago :D.
Cool numerical explorations of post-training stuff. Nothing crazy.
SultanR/SmolTulu-1.7b-Instruct
https://buff.ly/41Epauv

December 16, 2024 at 12:47 AM
Maybe my favorite unexpected crossover model from the community.
SmolLM from HuggingFace trained with part of the Tülu 3 recipe we release a month ago :D.
Cool numerical explorations of post-training stuff. Nothing crazy.
SultanR/SmolTulu-1.7b-Instruct
https://buff.ly/41Epauv
SmolLM from HuggingFace trained with part of the Tülu 3 recipe we release a month ago :D.
Cool numerical explorations of post-training stuff. Nothing crazy.
SultanR/SmolTulu-1.7b-Instruct
https://buff.ly/41Epauv
Reposted by Costa Huang

I'll be attending NeurIPS in Vancouver next week!
I would love to chat about LLM post-training research, the Faculty job market and anything in between - ping me if you'd like to meet up!
You can also find me at the following:
I would love to chat about LLM post-training research, the Faculty job market and anything in between - ping me if you'd like to meet up!
You can also find me at the following:
December 1, 2024 at 11:56 PM
I'll be attending NeurIPS in Vancouver next week!
I would love to chat about LLM post-training research, the Faculty job market and anything in between - ping me if you'd like to meet up!
You can also find me at the following:
I would love to chat about LLM post-training research, the Faculty job market and anything in between - ping me if you'd like to meet up!
You can also find me at the following:
So happy OLMo 2 is out! We applied the same Tülu 3 RLVR recipe and it worked very nicely for our final 13B instruct model.
Here are the gains/losses of allenai/OLMo-2-1124-13B-Instruct (RLVR's checkpoint) over allenai/OLMo-2-1124-13B-DPO. More to share soon!
Here are the gains/losses of allenai/OLMo-2-1124-13B-Instruct (RLVR's checkpoint) over allenai/OLMo-2-1124-13B-DPO. More to share soon!

November 26, 2024 at 11:19 PM
So happy OLMo 2 is out! We applied the same Tülu 3 RLVR recipe and it worked very nicely for our final 13B instruct model.
Here are the gains/losses of allenai/OLMo-2-1124-13B-Instruct (RLVR's checkpoint) over allenai/OLMo-2-1124-13B-DPO. More to share soon!
Here are the gains/losses of allenai/OLMo-2-1124-13B-Instruct (RLVR's checkpoint) over allenai/OLMo-2-1124-13B-DPO. More to share soon!
Reposted by Costa Huang

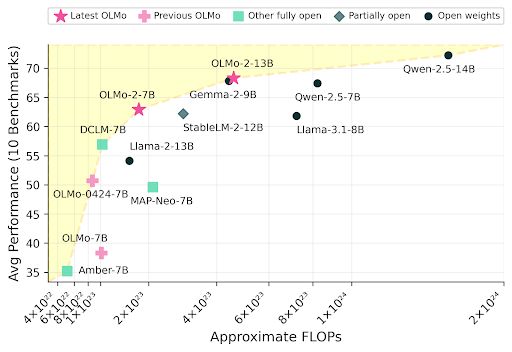
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
Reposted by Costa Huang

One of my fav projects: LeanRL, a simple RL library that provides recipes for fast RL training using torch.compile and cudagraphs.
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...

November 22, 2024 at 6:38 AM
One of my fav projects: LeanRL, a simple RL library that provides recipes for fast RL training using torch.compile and cudagraphs.
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
Using these, we got >6x speed-ups compared to the original CleanRL implementations.
github.com/pytorch-labs...
👀 @araffin.bsky.social says he can’t @ me. What’s going on? @bsky.app

@qgallouedec.bsky.social for SB3 and trl
Costa huang for clean rl (i couldn't manage to @ him...)
bsky.app/profile/vwxy...
Costa huang for clean rl (i couldn't manage to @ him...)
bsky.app/profile/vwxy...
bsky.app
November 23, 2024 at 8:44 PM
👀 @araffin.bsky.social says he can’t @ me. What’s going on? @bsky.app
Reposted by Costa Huang
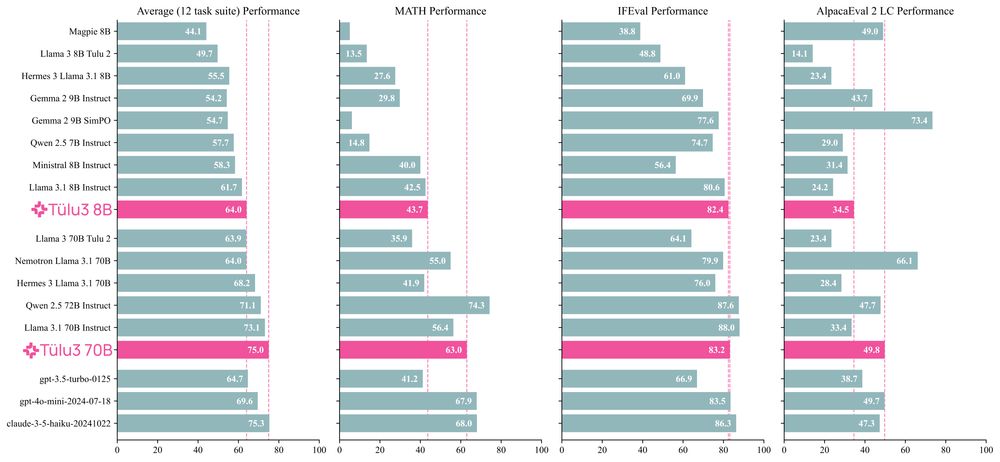
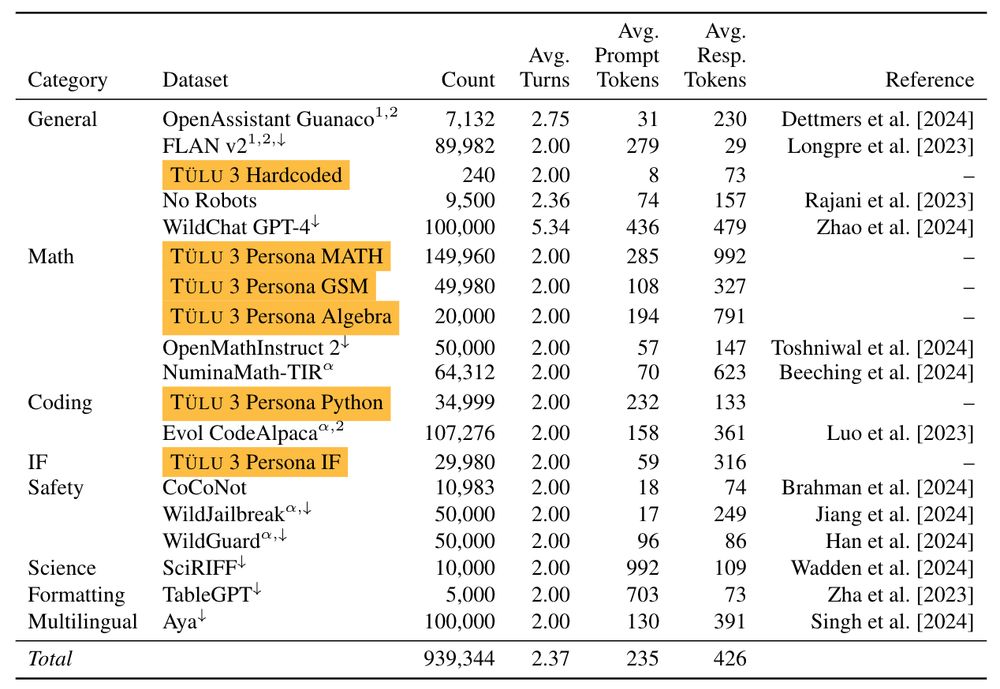
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
November 21, 2024 at 5:01 PM
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.