



Costa Huang
@vwxyzjn.bsky.social
RL + LLM @ai2.bsky.social; main dev of https://cleanrl.dev/
One fun thing is that our model outperformed qwen by almost ~26 points in IFEval. What's going on? We built some nice visualization tools, finding out that basically our model can follow the instructions like "write without a comma" well.
May 1, 2025 at 1:21 PM
One fun thing is that our model outperformed qwen by almost ~26 points in IFEval. What's going on? We built some nice visualization tools, finding out that basically our model can follow the instructions like "write without a comma" well.
The model checkpoints are available in huggingface.co/collections/....
As always, we uploaded all the intermediate RL checkpoints
As always, we uploaded all the intermediate RL checkpoints

May 1, 2025 at 1:21 PM
The model checkpoints are available in huggingface.co/collections/....
As always, we uploaded all the intermediate RL checkpoints
As always, we uploaded all the intermediate RL checkpoints
🥘 Excited to share our latest OLMo 1 B models! Almost summer RL time. We did another two-stage RL:
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵

May 1, 2025 at 1:21 PM
🥘 Excited to share our latest OLMo 1 B models! Almost summer RL time. We did another two-stage RL:
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
* The first RLVR run uses allenai/RLVR-GSM-MATH-IF-Mixed-Constraints
* The final RLVR run uses allenai/RLVR-MATH for targeted MATH improvement
Short 🧵
We streamlined our release process to include the RLVR intermediate checkpoints as well. They are available in the revisions if you want to check it out.
See our updated collection here: huggingface.co/collections/...
See our updated collection here: huggingface.co/collections/...

March 13, 2025 at 7:19 PM
We streamlined our release process to include the RLVR intermediate checkpoints as well. They are available in the revisions if you want to check it out.
See our updated collection here: huggingface.co/collections/...
See our updated collection here: huggingface.co/collections/...
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!

March 13, 2025 at 7:19 PM
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!
🗡️ The training length is a confounder, but I did run a launch an ablation study on the same `allenai/RLVR-MATH` dataset, using almost identical hyperparams for PPO and GRPO:
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.

February 12, 2025 at 5:33 PM
🗡️ The training length is a confounder, but I did run a launch an ablation study on the same `allenai/RLVR-MATH` dataset, using almost identical hyperparams for PPO and GRPO:
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
The PPO's MATH score is more consistent with the Llama-3.1-Tulu-3-8B model, but GRPO got higher scores.
📈 Below is the training curve. I think part of the performance gain also comes from training RL for longer

February 12, 2025 at 5:33 PM
📈 Below is the training curve. I think part of the performance gain also comes from training RL for longer
🎆 @natolambert.bsky.social also updated this figure in our paper, for a better visualization :D

February 12, 2025 at 5:33 PM
🎆 @natolambert.bsky.social also updated this figure in our paper, for a better visualization :D
🎁 We applied the same RLVR dataset (allenai/RLVR-GSM-MATH-IF-Mixed-Constraints) using our new GRPO training script - the trained model checkpoints are better!

February 12, 2025 at 5:33 PM
🎁 We applied the same RLVR dataset (allenai/RLVR-GSM-MATH-IF-Mixed-Constraints) using our new GRPO training script - the trained model checkpoints are better!
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:33 PM
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
All of our research artifacts are fully open source and released. Check out our HF collection:
huggingface.co/collections/...
huggingface.co/collections/...
February 11, 2025 at 3:30 PM
All of our research artifacts are fully open source and released. Check out our HF collection:
huggingface.co/collections/...
huggingface.co/collections/...
This is how our new allenai/OLMoE-1B-7B-0125-Instruct models compare with the existing allenai/OLMoE-1B-7B-0924-Instruct checkpoint :)
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
Huge gains on GSM8K, DROP, MATH, and alpaca eval.

February 11, 2025 at 3:30 PM
This is how our new allenai/OLMoE-1B-7B-0125-Instruct models compare with the existing allenai/OLMoE-1B-7B-0924-Instruct checkpoint :)
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
Huge gains on GSM8K, DROP, MATH, and alpaca eval.
We found the RLVR + GSM8K recipe to work robustly, and the scores kept going up

February 11, 2025 at 3:30 PM
We found the RLVR + GSM8K recipe to work robustly, and the scores kept going up
🤯 Check out our new iOS OLMoE app that runs the model on-device!
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵

February 11, 2025 at 3:30 PM
🤯 Check out our new iOS OLMoE app that runs the model on-device!
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
We also trained new OLMoE-1B-7B-0125 this time using the Tulu 3 recipe. Very exciting that RLVR improved gsm8k by almost 10 points for OLMoE 🔥
A quick 🧵
That said, I have tried using kl3 estimator in PPO (so not directly in the loss), and it actually blows up training.
Here is an example of the PPO training curve (using kl1). As you can see, kl3 > kl2 > kl in scale.
Here is an example of the PPO training curve (using kl1). As you can see, kl3 > kl2 > kl in scale.

January 31, 2025 at 3:21 PM
That said, I have tried using kl3 estimator in PPO (so not directly in the loss), and it actually blows up training.
Here is an example of the PPO training curve (using kl1). As you can see, kl3 > kl2 > kl in scale.
Here is an example of the PPO training curve (using kl1). As you can see, kl3 > kl2 > kl in scale.

January 31, 2025 at 3:21 PM
I nerd-snipped myself over the @deepseek.bsky.social GRPO's usage of John Schulman's kl3 estimator. I can now see why:
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).

January 31, 2025 at 3:21 PM
I nerd-snipped myself over the @deepseek.bsky.social GRPO's usage of John Schulman's kl3 estimator. I can now see why:
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
When directly minimizing the KL loss, kl3 just appears much more numerically stable. And the >0 guarantee here is also really nice (kl1 could go negative).
🚀 The team is incredible! Our paper has more detail on pre-training, mid-training, infrastructure, and evaluations. Check it out!
arxiv.org/abs/2501.00656
arxiv.org/abs/2501.00656

January 6, 2025 at 6:34 PM
🚀 The team is incredible! Our paper has more detail on pre-training, mid-training, infrastructure, and evaluations. Check it out!
arxiv.org/abs/2501.00656
arxiv.org/abs/2501.00656
On the other hand, 7B RLVR reproduction was quite peaceful and just works.

January 6, 2025 at 6:34 PM
On the other hand, 7B RLVR reproduction was quite peaceful and just works.
New 13b RLVR has three full training curves 😬. We took the checkpoint with the best average score to do the iterative iirc. The main figure combines the learning curves.




January 6, 2025 at 6:34 PM
New 13b RLVR has three full training curves 😬. We took the checkpoint with the best average score to do the iterative iirc. The main figure combines the learning curves.
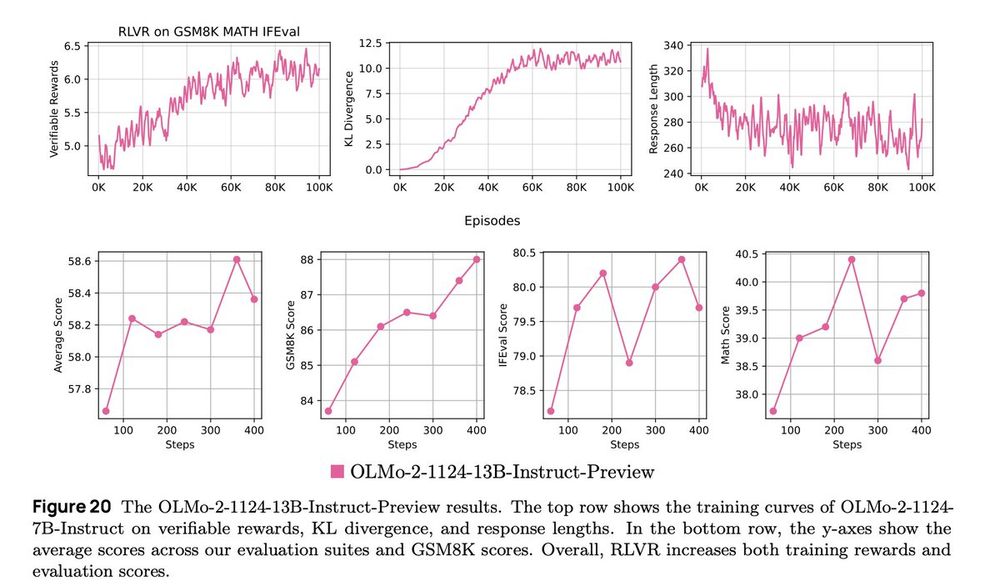
Learning curves time: The old borked tokenizer 13b RLVR has this beautiful training curve:
January 6, 2025 at 6:34 PM
Learning curves time: The old borked tokenizer 13b RLVR has this beautiful training curve:
I was quite puzzled by the regression. And thought, well, if the GSM8K is lower, I could just run it on GSM8K train and control the KL with a higher beta. That leads to 2 more RLVR checkpoints.
Our final RLVR checkpoint does look pretty good 😊
Our final RLVR checkpoint does look pretty good 😊
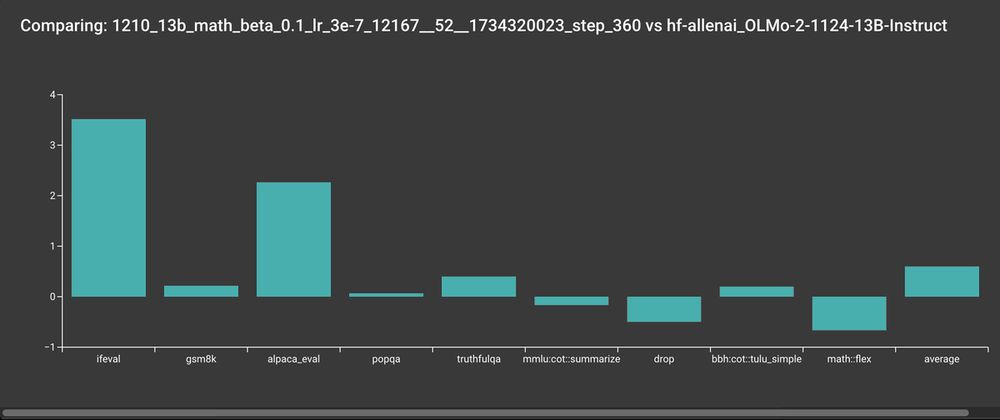
January 6, 2025 at 6:34 PM
I was quite puzzled by the regression. And thought, well, if the GSM8K is lower, I could just run it on GSM8K train and control the KL with a higher beta. That leads to 2 more RLVR checkpoints.
Our final RLVR checkpoint does look pretty good 😊
Our final RLVR checkpoint does look pretty good 😊
We kept on training by performing the mysterious technique: more hyperparameter tuning. Second attempt: the RLVR checkpoint is better, but still low on GSM8K and MATH. A lot better in IFeval. Eh. Ok.
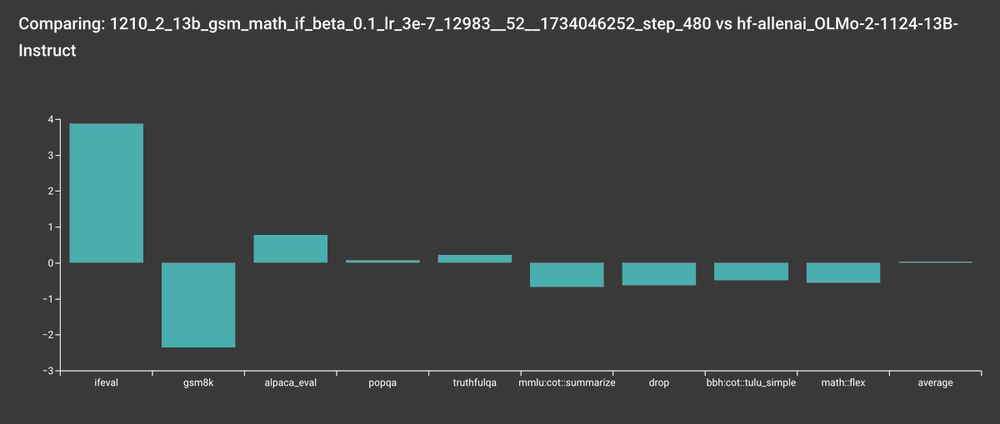
January 6, 2025 at 6:34 PM
We kept on training by performing the mysterious technique: more hyperparameter tuning. Second attempt: the RLVR checkpoint is better, but still low on GSM8K and MATH. A lot better in IFeval. Eh. Ok.
Well, well, well, we were in reproduction surprise. Modern-day LLM training feels quite "result-reproducible" but not "process-reproducible". Running the exact recipe yields worse models for some reason.
Our initial reproduction attempt shows regression on SFT / DPO / RLVR.
Our initial reproduction attempt shows regression on SFT / DPO / RLVR.

January 6, 2025 at 6:34 PM
Well, well, well, we were in reproduction surprise. Modern-day LLM training feels quite "result-reproducible" but not "process-reproducible". Running the exact recipe yields worse models for some reason.
Our initial reproduction attempt shows regression on SFT / DPO / RLVR.
Our initial reproduction attempt shows regression on SFT / DPO / RLVR.
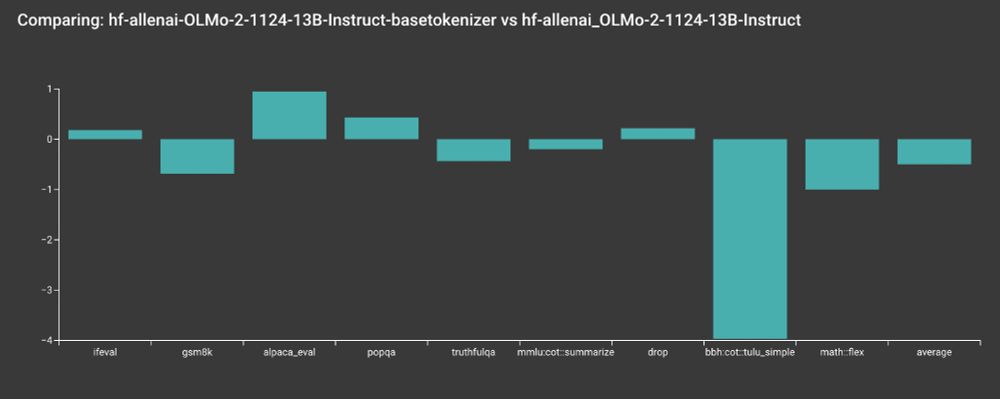
There is not an easy way to go around it. We also tested it and found a ~ 0.5 point regression in the average performance. GSM8K and MATH is also lower
So, we decided to re-train the models using the correct tokenizer.
So, we decided to re-train the models using the correct tokenizer.
January 6, 2025 at 6:34 PM
There is not an easy way to go around it. We also tested it and found a ~ 0.5 point regression in the average performance. GSM8K and MATH is also lower
So, we decided to re-train the models using the correct tokenizer.
So, we decided to re-train the models using the correct tokenizer.