




Noah Snavely
@snavely.bsky.social
3D vision fanatic
http://snavely.io
http://snavely.io
What are some examples of computer vision papers that have attractive system diagrams?
November 10, 2025 at 3:31 AM
What are some examples of computer vision papers that have attractive system diagrams?
Reposted by Noah Snavely

Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
October 10, 2025 at 10:13 PM
Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Reposted by Noah Snavely

#TTT3R: 3D Reconstruction as Test-Time Training
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
October 1, 2025 at 6:35 AM
#TTT3R: 3D Reconstruction as Test-Time Training
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
TTT3R offers a simple state update rule to enhance length generalization for #CUT3R — No fine-tuning required!
🔗Page: rover-xingyu.github.io/TTT3R
We rebuilt @taylorswift13’s "22" live at the 2013 Billboard Music Awards - in 3D!
Reposted by Noah Snavely

We present a new approach to inference-time scene optimization, which we name Radiant Triangle Soup (RTS) www.arxiv.org/abs/2505.23642. Also check out really great concurrent work from Held et al. @janheld.bsky.social, Triangle Splatting arxiv.org/abs/2505.19175




May 30, 2025 at 8:42 PM
We present a new approach to inference-time scene optimization, which we name Radiant Triangle Soup (RTS) www.arxiv.org/abs/2505.23642. Also check out really great concurrent work from Held et al. @janheld.bsky.social, Triangle Splatting arxiv.org/abs/2505.19175
Reposted by Noah Snavely

🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
KiVA Challenge @ ICCV 2025
kiva-challenge.github.io
July 15, 2025 at 7:19 PM
🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
ChatGPT and Gemini both seem to struggle with sheet music. They both insist that this excerpt is in D major (2 sharps), and resist any attempt to tell them that there 3 sharps in the key signature. I think this is really cool and interesting!

July 11, 2025 at 10:44 PM
ChatGPT and Gemini both seem to struggle with sheet music. They both insist that this excerpt is in D major (2 sharps), and resist any attempt to tell them that there 3 sharps in the key signature. I think this is really cool and interesting!
Reposted by Noah Snavely
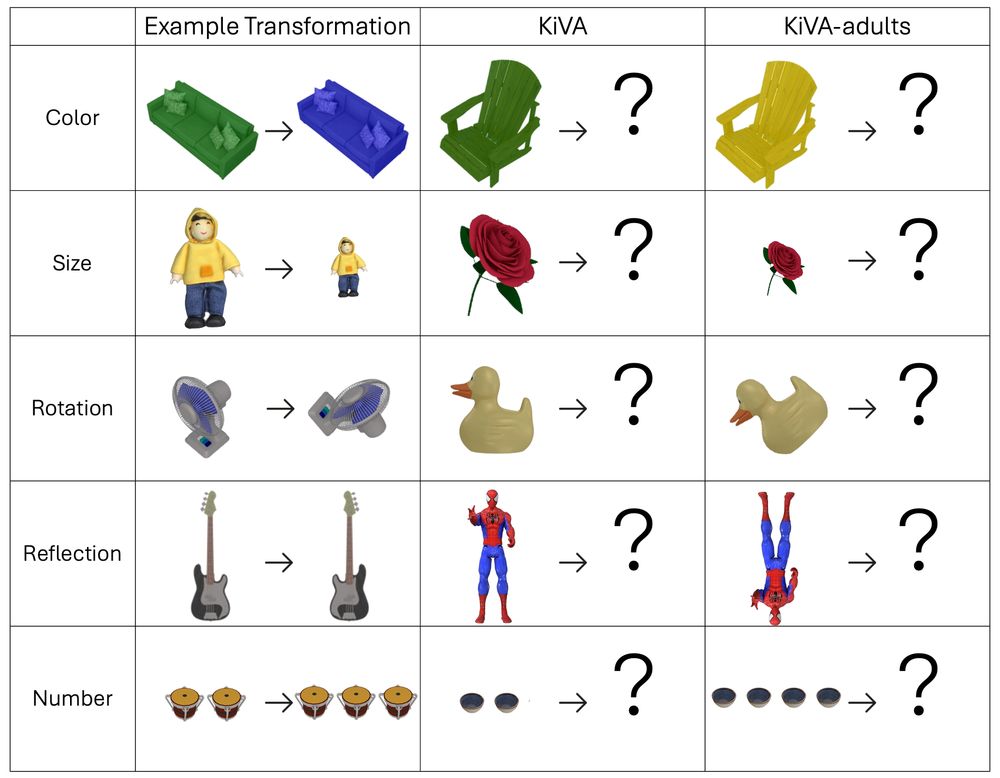
Think LMMs can reason like a 3-year-old?
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
April 23, 2025 at 10:58 PM
Think LMMs can reason like a 3-year-old?
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Reposted by Noah Snavely

Dynamic Camera Poses and Where to Find Them
Chris Rockwell, @jtung.bsky.social, Tsung-Yi Lin, Ming-Yu Liu, David F. Fouhey, Chen-Hsuan Lin
tl;dr: a large-scale dataset of dynamic Internet videos annotated with camera poses
arxiv.org/abs/2504.17788
Chris Rockwell, @jtung.bsky.social, Tsung-Yi Lin, Ming-Yu Liu, David F. Fouhey, Chen-Hsuan Lin
tl;dr: a large-scale dataset of dynamic Internet videos annotated with camera poses
arxiv.org/abs/2504.17788




April 25, 2025 at 12:11 PM
Dynamic Camera Poses and Where to Find Them
Chris Rockwell, @jtung.bsky.social, Tsung-Yi Lin, Ming-Yu Liu, David F. Fouhey, Chen-Hsuan Lin
tl;dr: a large-scale dataset of dynamic Internet videos annotated with camera poses
arxiv.org/abs/2504.17788
Chris Rockwell, @jtung.bsky.social, Tsung-Yi Lin, Ming-Yu Liu, David F. Fouhey, Chen-Hsuan Lin
tl;dr: a large-scale dataset of dynamic Internet videos annotated with camera poses
arxiv.org/abs/2504.17788
Reposted by Noah Snavely

1/6 🔍➡️ How to transform standard videos into immersive 360° panoramas? We've designed a new AI system for video-to-360° panorama generation!
Our key insight: large-scale data is crucial for robust panoramic synthesis across diverse scenes.
Our key insight: large-scale data is crucial for robust panoramic synthesis across diverse scenes.
April 23, 2025 at 3:49 PM
1/6 🔍➡️ How to transform standard videos into immersive 360° panoramas? We've designed a new AI system for video-to-360° panorama generation!
Our key insight: large-scale data is crucial for robust panoramic synthesis across diverse scenes.
Our key insight: large-scale data is crucial for robust panoramic synthesis across diverse scenes.
Reposted by Noah Snavely

We have released the Stereo4D dataset! Explore the real-world dynamic 3D tracks: github.com/Stereo4d/ste...
April 15, 2025 at 7:59 PM
We have released the Stereo4D dataset! Explore the real-world dynamic 3D tracks: github.com/Stereo4d/ste...
This is really nice work on visual discovery from @boyangdeng.bsky.social!

Curious about how cities have changed in the past decade? We use MLLMs to analyse 40 million Street View images to answer this. Do you know that "'juice shops' became a thing in NYC" and "miles of overpasses were painted BLUE in SF"? More at→boyangdeng.com/visual-chronicles (vid ↓ w/ 🔊)
April 14, 2025 at 1:40 PM
This is really nice work on visual discovery from @boyangdeng.bsky.social!
Reposted by Noah Snavely

We're very excited to introduce TAPNext: a model that sets a new state-of-art for Tracking Any Point in videos, by formulating the task as Next Token Prediction. For more, see: tap-next.github.io
April 9, 2025 at 2:04 PM
We're very excited to introduce TAPNext: a model that sets a new state-of-art for Tracking Any Point in videos, by formulating the task as Next Token Prediction. For more, see: tap-next.github.io
Reposted by Noah Snavely

A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.

April 8, 2025 at 5:25 PM
A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.


Reposted by Noah Snavely

🚀 We’ve just released the code and checkpoints for our #ICLR2025 Oral paper: "LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias".
Check it out below 👇
🔗 Code: github.com/haian-jin/LVSM
📄 Paper: arxiv.org/abs/2410.17242
🌐 Project Page: haian-jin.github.io/projects/LVSM/
Check it out below 👇
🔗 Code: github.com/haian-jin/LVSM
📄 Paper: arxiv.org/abs/2410.17242
🌐 Project Page: haian-jin.github.io/projects/LVSM/
April 5, 2025 at 6:25 PM
🚀 We’ve just released the code and checkpoints for our #ICLR2025 Oral paper: "LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias".
Check it out below 👇
🔗 Code: github.com/haian-jin/LVSM
📄 Paper: arxiv.org/abs/2410.17242
🌐 Project Page: haian-jin.github.io/projects/LVSM/
Check it out below 👇
🔗 Code: github.com/haian-jin/LVSM
📄 Paper: arxiv.org/abs/2410.17242
🌐 Project Page: haian-jin.github.io/projects/LVSM/
This is really cool work!
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io

March 30, 2025 at 12:14 AM
This is really cool work!
Reposted by Noah Snavely

[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
March 29, 2025 at 7:36 PM
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Reposted by Noah Snavely

#Backslash at #CornellTech, dedicated to advancing new works of art and technology that escape convention, has announced Mimi Ọnụọha as its first Backslash Fellow: tech.cornell.edu/news/mimi-on...
“This work feels like a marked evolution for me personally,” said Ọnụọha.
@snavely.bsky.social
“This work feels like a marked evolution for me personally,” said Ọnụọha.
@snavely.bsky.social

March 12, 2025 at 4:44 PM
#Backslash at #CornellTech, dedicated to advancing new works of art and technology that escape convention, has announced Mimi Ọnụọha as its first Backslash Fellow: tech.cornell.edu/news/mimi-on...
“This work feels like a marked evolution for me personally,” said Ọnụọha.
@snavely.bsky.social
“This work feels like a marked evolution for me personally,” said Ọnụọha.
@snavely.bsky.social
Reposted by Noah Snavely

#CVPR2025 offers registration and travel support to students from underrepresented communities. Awards are based on need, contribution, travel distance, identity, and advisor support.
Information and form: forms.gle/uDR2Q74drC4V...
Information and form: forms.gle/uDR2Q74drC4V...

Broadening Participation Scholarship Form
CVPR 2025 Travel and Registration Support Application CVPR'25 is committed to supporting students from communities that do not traditionally attend CVPR through registration and travel support. Allocation is based on a combination of need, contribution to the conference, where you are traveling from, the community(ies) you identify with and advisor support. Travel support will be issued in fixed amounts that will be based on availability of funds and travel distance. If you would like to be considered for this support, please complete the following application. Decisions will be made on a rolling basis. Applications will be accepted until April 19 2025 (anywhere on earth).
forms.gle
March 11, 2025 at 7:13 PM
#CVPR2025 offers registration and travel support to students from underrepresented communities. Awards are based on need, contribution, travel distance, identity, and advisor support.
Information and form: forms.gle/uDR2Q74drC4V...
Information and form: forms.gle/uDR2Q74drC4V...
Reposted by Noah Snavely

Exciting news! MegaSAM code is out🔥 & the updated Shape of Motion results with MegaSAM are really impressive! A year ago I didn't think we could make any progress on these videos: shape-of-motion.github.io/results.html
Huge congrats to everyone involved and the community 🎉
Huge congrats to everyone involved and the community 🎉
February 24, 2025 at 6:52 PM
Exciting news! MegaSAM code is out🔥 & the updated Shape of Motion results with MegaSAM are really impressive! A year ago I didn't think we could make any progress on these videos: shape-of-motion.github.io/results.html
Huge congrats to everyone involved and the community 🎉
Huge congrats to everyone involved and the community 🎉
I think Qianqian et al's work is really cool! The problem of modeling state within a 3D reasoning system is quite interesting.
(And I believe it's pronounced "cuter".)
(And I believe it's pronounced "cuter".)
Late to post, but excited to introduce CUT3R!
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
February 18, 2025 at 5:09 PM
I think Qianqian et al's work is really cool! The problem of modeling state within a 3D reasoning system is quite interesting.
(And I believe it's pronounced "cuter".)
(And I believe it's pronounced "cuter".)
Reposted by Noah Snavely

Late to post, but excited to introduce CUT3R!
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
February 18, 2025 at 5:03 PM
Late to post, but excited to introduce CUT3R!
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
An online 3D reasoning framework for many 3D tasks directly from just RGB. For static or dynamic scenes. Video or image collections, all in one!
Project Page: cut3r.github.io
Code and Model: github.com/CUT3R/CUT3R
This is really unimportant, but I keep seeing the word "advancements" in writing where I would have seen the word "advances" before.
I'm taking this to mean that LLMs are at play and therefore, they will influence the language such that the two words will eventually come to mean the same thing!
I'm taking this to mean that LLMs are at play and therefore, they will influence the language such that the two words will eventually come to mean the same thing!
February 18, 2025 at 3:49 PM
This is really unimportant, but I keep seeing the word "advancements" in writing where I would have seen the word "advances" before.
I'm taking this to mean that LLMs are at play and therefore, they will influence the language such that the two words will eventually come to mean the same thing!
I'm taking this to mean that LLMs are at play and therefore, they will influence the language such that the two words will eventually come to mean the same thing!
This is a really fun podcast episode for people whose favorite part of the Empire Strikes Back film score is when the Millenium Falcon flies out of the giant space slug!
www.settlingthescorepodcast.com/66-the-empir...
@scoresettlers.bsky.social
www.settlingthescorepodcast.com/66-the-empir...
@scoresettlers.bsky.social
#66 – The Empire Strikes Back – Settling the Score
www.settlingthescorepodcast.com
February 13, 2025 at 2:08 AM
This is a really fun podcast episode for people whose favorite part of the Empire Strikes Back film score is when the Millenium Falcon flies out of the giant space slug!
www.settlingthescorepodcast.com/66-the-empir...
@scoresettlers.bsky.social
www.settlingthescorepodcast.com/66-the-empir...
@scoresettlers.bsky.social
My question for the history heads out there:
In the 1960s, did they call the 1880s "the Eighties"?
In the 1960s, did they call the 1880s "the Eighties"?
February 12, 2025 at 3:50 PM
My question for the history heads out there:
In the 1960s, did they call the 1880s "the Eighties"?
In the 1960s, did they call the 1880s "the Eighties"?