




Anand Bhattad
@anandbhattad.bsky.social
Incoming Assistant Professor at Johns Hopkins University | RAP at Toyota Technological Institute at Chicago | web: https://anandbhattad.github.io/ | Knowledge in Generative Image Models, Intrinsic Images, Image-based Relighting, Inverse Graphics
Pinned
Anand Bhattad
@anandbhattad.bsky.social
· Sep 21

So You Want to Be an Academic? What I Wish I Knew Early in Graduate School
Blog for junior PhD students on work, visibility, community, and sanity—long before the faculty job market is on the horizon.
anandbhattad.github.io
So You Want to Be an Academic?
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
Reposted by Anand Bhattad

Join us in advancing data science and AI research! The Johns Hopkins Data Science and AI Institute Postdoctoral Fellowship Program is now accepting applications for the 2026–2027 academic year. Apply now! Deadline: Jan 23, 2026. Details and apply: apply.interfolio.com/179059

December 19, 2025 at 1:29 PM
Join us in advancing data science and AI research! The Johns Hopkins Data Science and AI Institute Postdoctoral Fellowship Program is now accepting applications for the 2026–2027 academic year. Apply now! Deadline: Jan 23, 2026. Details and apply: apply.interfolio.com/179059
Reposted by Anand Bhattad

10 new CS professors! 🥳
@anandbhattad.bsky.social @uthsav.bsky.social @gligoric.bsky.social @murat-kocaoglu.bsky.social @tiziano.bsky.social
@anandbhattad.bsky.social @uthsav.bsky.social @gligoric.bsky.social @murat-kocaoglu.bsky.social @tiziano.bsky.social
#HopkinsDSAI welcomes 22 new faculty members, who join more than 150 DSAI faculty members across @jhu.edu in advancing the study of data science, machine learning, and #AI and translation to a range of critical and emerging fields.
ai.jhu.edu/news/data-sc...
ai.jhu.edu/news/data-sc...

October 8, 2025 at 5:43 PM
I decided not to travel to #ICCV2025 because it coincides with Diwali (Oct 20). Diwali often falls near the #CVPR deadline window, but this year overlaps with ICCV. I understand it’s hard to avoid all global holidays, but I hope future conferences can keep this in mind when selecting dates.
October 6, 2025 at 7:00 PM
I will be recruiting a few students for Fall 2026. In particular, I will strongly consider a PhD applicant with training in applied/computational mechanics and computer vision/machine learning. If you or someone you know has this background, please contact me.
I’m thrilled to share that I will be joining Johns Hopkins University’s Department of Computer Science (@jhucompsci.bsky.social, @hopkinsdsai.bsky.social) as an Assistant Professor this fall.

October 6, 2025 at 6:39 PM
I will be recruiting a few students for Fall 2026. In particular, I will strongly consider a PhD applicant with training in applied/computational mechanics and computer vision/machine learning. If you or someone you know has this background, please contact me.
So You Want to Be an Academic?
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
So You Want to Be an Academic? What I Wish I Knew Early in Graduate School
Blog for junior PhD students on work, visibility, community, and sanity—long before the faculty job market is on the horizon.
anandbhattad.github.io
September 21, 2025 at 2:30 AM
So You Want to Be an Academic?
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
A couple of years into your PhD, but wondering: "Am I doing this right?"
Most of the advice is aimed at graduating students. But there's far less for junior folks who are still finding their academic path.
My candid takes: anandbhattad.github.io/blogs/jr_gra...
Reposted by Anand Bhattad

On our blog: Science is moving fast. How do we keep up? #ScholarInbox, developed by the Autonomous Vision Group led by @andreasgeiger.bsky.social, helps researchers stay ahead - by making the discovery of #openaccess papers smarter and more personal: www.machinelearningforscience.de/en/scholar-i...

Scholar Inbox: Daily Research Recommendations just for You
Science is moving fast. How can we keep up? Scholar Inbox helps researchers stay ahead by making the discovery of open access papers more personal.
www.machinelearningforscience.de
June 30, 2025 at 12:40 PM
On our blog: Science is moving fast. How do we keep up? #ScholarInbox, developed by the Autonomous Vision Group led by @andreasgeiger.bsky.social, helps researchers stay ahead - by making the discovery of #openaccess papers smarter and more personal: www.machinelearningforscience.de/en/scholar-i...
All slides from the #cvpr2025 (@cvprconference.bsky.social ) workshop "How to Stand Out in the Crowd?" are now available on our website:
sites.google.com/view/standou...
sites.google.com/view/standou...
🧵 1/3 Many at #CVPR2024 & #ECCV2024 asked what would be next in our workshop series.
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...

June 30, 2025 at 3:19 AM
All slides from the #cvpr2025 (@cvprconference.bsky.social ) workshop "How to Stand Out in the Crowd?" are now available on our website:
sites.google.com/view/standou...
sites.google.com/view/standou...
I’m thrilled to share that I will be joining Johns Hopkins University’s Department of Computer Science (@jhucompsci.bsky.social, @hopkinsdsai.bsky.social) as an Assistant Professor this fall.
June 2, 2025 at 7:46 PM
I’m thrilled to share that I will be joining Johns Hopkins University’s Department of Computer Science (@jhucompsci.bsky.social, @hopkinsdsai.bsky.social) as an Assistant Professor this fall.
Reposted by Anand Bhattad

FastMap: Revisiting Dense and Scalable Structure from Motion
Jiahao Li, Haochen Wang, @zubair-irshad.bsky.social, @ivasl.bsky.social, Matthew R. Walter, Vitor Campagnolo Guizilini, Greg Shakhnarovich
tl;dr: replace BA with epipolar error+IRLS; fully PyTorch implementation
arxiv.org/abs/2505.04612
Jiahao Li, Haochen Wang, @zubair-irshad.bsky.social, @ivasl.bsky.social, Matthew R. Walter, Vitor Campagnolo Guizilini, Greg Shakhnarovich
tl;dr: replace BA with epipolar error+IRLS; fully PyTorch implementation
arxiv.org/abs/2505.04612
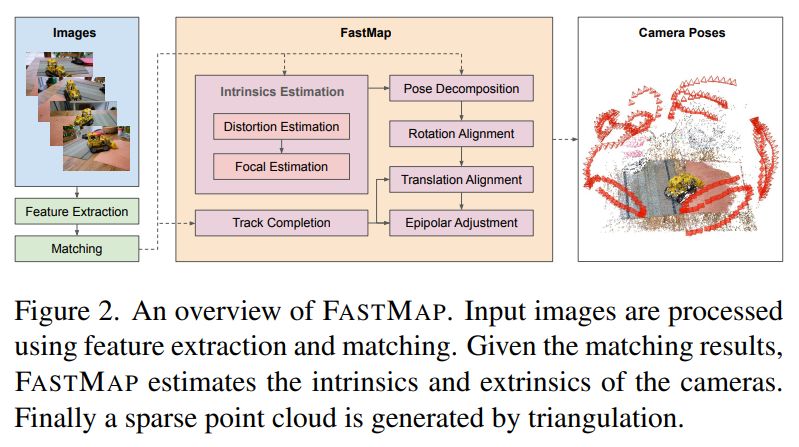

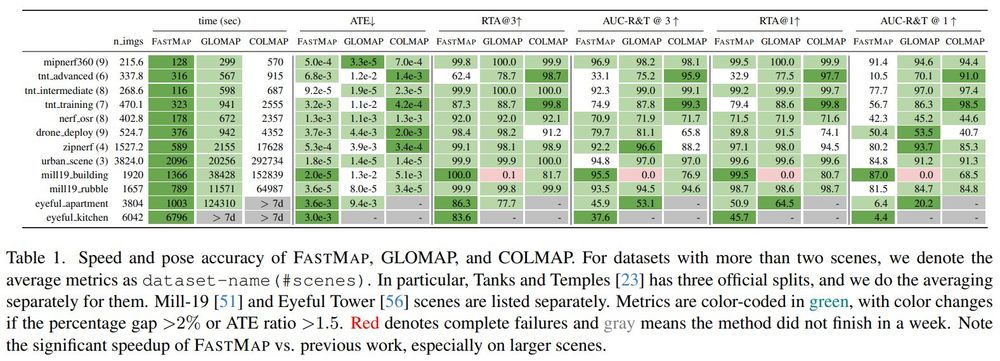
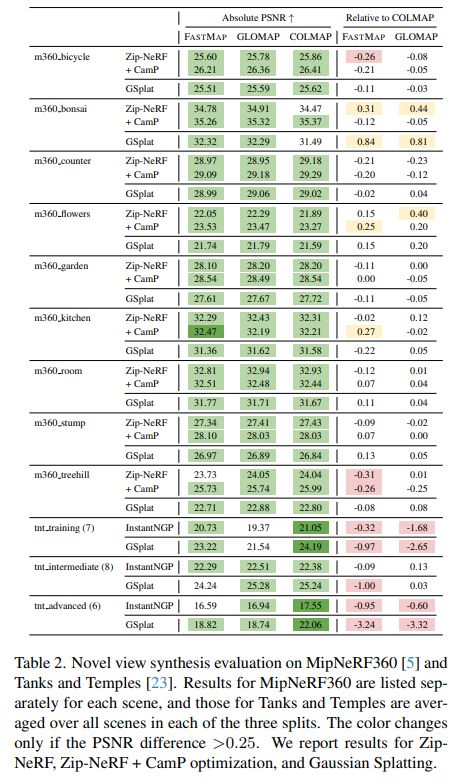
May 8, 2025 at 12:51 PM
FastMap: Revisiting Dense and Scalable Structure from Motion
Jiahao Li, Haochen Wang, @zubair-irshad.bsky.social, @ivasl.bsky.social, Matthew R. Walter, Vitor Campagnolo Guizilini, Greg Shakhnarovich
tl;dr: replace BA with epipolar error+IRLS; fully PyTorch implementation
arxiv.org/abs/2505.04612
Jiahao Li, Haochen Wang, @zubair-irshad.bsky.social, @ivasl.bsky.social, Matthew R. Walter, Vitor Campagnolo Guizilini, Greg Shakhnarovich
tl;dr: replace BA with epipolar error+IRLS; fully PyTorch implementation
arxiv.org/abs/2505.04612
Reposted by Anand Bhattad

This is really cool work!
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io

March 30, 2025 at 12:14 AM
This is really cool work!
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
March 29, 2025 at 7:36 PM
[1/10] Is scene understanding solved?
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
Models today can label pixels and detect objects with high accuracy. But does that mean they truly understand scenes?
Super excited to share our new paper and a new task in computer vision: Visual Jenga!
📄 arxiv.org/abs/2503.21770
🔗 visualjenga.github.io
I can’t believe this! Mind-blowing! There are small errors (a flipped logo, rotated chairs), but still, this is incredible!!
Xiaoyan, who’s been working with me on relighting, sent this over. It’s one of the hardest examples we’ve consistently used to stress-test LumiNet: luminet-relight.github.io
Xiaoyan, who’s been working with me on relighting, sent this over. It’s one of the hardest examples we’ve consistently used to stress-test LumiNet: luminet-relight.github.io
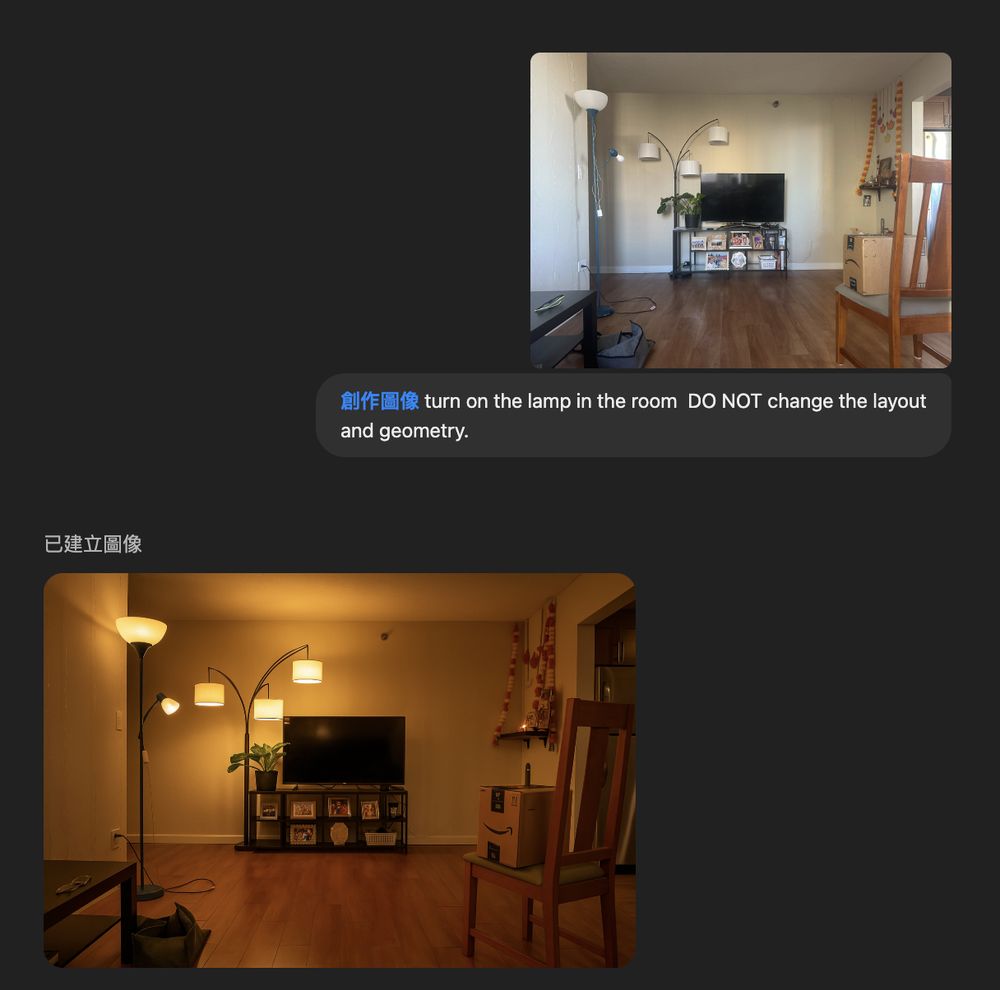
March 27, 2025 at 8:00 PM
I can’t believe this! Mind-blowing! There are small errors (a flipped logo, rotated chairs), but still, this is incredible!!
Xiaoyan, who’s been working with me on relighting, sent this over. It’s one of the hardest examples we’ve consistently used to stress-test LumiNet: luminet-relight.github.io
Xiaoyan, who’s been working with me on relighting, sent this over. It’s one of the hardest examples we’ve consistently used to stress-test LumiNet: luminet-relight.github.io
Reposted by Anand Bhattad

Check out UrbanIR - Inverse rendering of unbounded scenes from a single video!
It’s a super cool project led by the amazing Chih-Hao!
@chih-hao.bsky.social is a rising star in 3DV! Follow him!
Learn more here👇
It’s a super cool project led by the amazing Chih-Hao!
@chih-hao.bsky.social is a rising star in 3DV! Follow him!
Learn more here👇

✨What if we could transform a daytime driving video into a realistic nighttime scene—without ever stepping outside again?
We introduce UrbanIR, a neural rendering framework for 💡relighting, 🌃nighttime simulation, and 🚘 object insertion—all from a single video of urban scenes!
We introduce UrbanIR, a neural rendering framework for 💡relighting, 🌃nighttime simulation, and 🚘 object insertion—all from a single video of urban scenes!
March 15, 2025 at 1:49 PM
Check out UrbanIR - Inverse rendering of unbounded scenes from a single video!
It’s a super cool project led by the amazing Chih-Hao!
@chih-hao.bsky.social is a rising star in 3DV! Follow him!
Learn more here👇
It’s a super cool project led by the amazing Chih-Hao!
@chih-hao.bsky.social is a rising star in 3DV! Follow him!
Learn more here👇
Can we create realistic renderings of urban scenes from a single video while enabling controllable editing: relighting, object compositing, and nighttime simulation?
Check out our #3DV2025 UrbanIR paper, led by @chih-hao.bsky.social that does exactly this.
🔗: urbaninverserendering.github.io
Check out our #3DV2025 UrbanIR paper, led by @chih-hao.bsky.social that does exactly this.
🔗: urbaninverserendering.github.io
March 16, 2025 at 3:39 AM
Can we create realistic renderings of urban scenes from a single video while enabling controllable editing: relighting, object compositing, and nighttime simulation?
Check out our #3DV2025 UrbanIR paper, led by @chih-hao.bsky.social that does exactly this.
🔗: urbaninverserendering.github.io
Check out our #3DV2025 UrbanIR paper, led by @chih-hao.bsky.social that does exactly this.
🔗: urbaninverserendering.github.io
Reposted by Anand Bhattad

Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
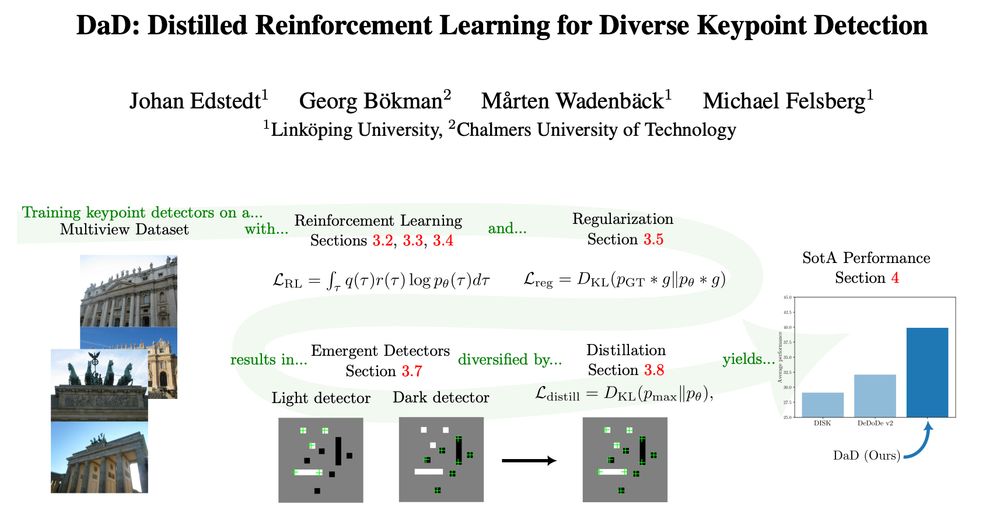
March 11, 2025 at 3:05 AM
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
Reposted by Anand Bhattad

Last was an intriguing talk by @anandbhattad.bsky.social on the degree to which physical properties are encoded in generative image models at the @grasplab.bsky.social www.youtube.com/watch?v=Idcb... (7/7)

Fall 2024 GRASP Seminar Anand Bhattad, Toyota Technological Institute at Chicago
YouTube video by GRASP Lab
www.youtube.com
March 6, 2025 at 3:29 AM
Last was an intriguing talk by @anandbhattad.bsky.social on the degree to which physical properties are encoded in generative image models at the @grasplab.bsky.social www.youtube.com/watch?v=Idcb... (7/7)
ZeroComp will be presented as an Oral at #WACV2025!
Train a diffusion model as a renderer that takes intrinsic images as input. Once trained, we can perform zero-shot object compositing & can easily extend this to other object editing tasks, such as material swapping.
arxiv.org/abs/2410.08168
Train a diffusion model as a renderer that takes intrinsic images as input. Once trained, we can perform zero-shot object compositing & can easily extend this to other object editing tasks, such as material swapping.
arxiv.org/abs/2410.08168

February 28, 2025 at 6:32 PM
ZeroComp will be presented as an Oral at #WACV2025!
Train a diffusion model as a renderer that takes intrinsic images as input. Once trained, we can perform zero-shot object compositing & can easily extend this to other object editing tasks, such as material swapping.
arxiv.org/abs/2410.08168
Train a diffusion model as a renderer that takes intrinsic images as input. Once trained, we can perform zero-shot object compositing & can easily extend this to other object editing tasks, such as material swapping.
arxiv.org/abs/2410.08168
LumiNet is going to be at #CVPR2025!
Excited about this work—fully data-driven, with zero reliance on computer graphics datasets.
It builds upon our previous works—StyLitGAN provided the training data, while Latent Intrinsics abstracted lighting and albedo for diffusion models.
And more to come! 🤓
Excited about this work—fully data-driven, with zero reliance on computer graphics datasets.
It builds upon our previous works—StyLitGAN provided the training data, while Latent Intrinsics abstracted lighting and albedo for diffusion models.
And more to come! 🤓
I'm super stoked to share LumiNet! 🎉
💡LumiNet combines latent intrinsic representations with a powerful generative image model. It lets us relight complex indoor images by transferring lighting from one image to another. It is completely data-driven: no labels, mark-up, not even depth or normals.
💡LumiNet combines latent intrinsic representations with a powerful generative image model. It lets us relight complex indoor images by transferring lighting from one image to another. It is completely data-driven: no labels, mark-up, not even depth or normals.
February 27, 2025 at 4:30 AM
LumiNet is going to be at #CVPR2025!
Excited about this work—fully data-driven, with zero reliance on computer graphics datasets.
It builds upon our previous works—StyLitGAN provided the training data, while Latent Intrinsics abstracted lighting and albedo for diffusion models.
And more to come! 🤓
Excited about this work—fully data-driven, with zero reliance on computer graphics datasets.
It builds upon our previous works—StyLitGAN provided the training data, while Latent Intrinsics abstracted lighting and albedo for diffusion models.
And more to come! 🤓
Reposted by Anand Bhattad

Really excited to put together this #CVPR2025 workshop on "4D Vision: Modeling the Dynamic World" -- one of the most fascinating areas in computer vision today!
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io

February 12, 2025 at 10:34 AM
Really excited to put together this #CVPR2025 workshop on "4D Vision: Modeling the Dynamic World" -- one of the most fascinating areas in computer vision today!
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
We've invited incredible researchers who are leading fantastic work at various related fields.
4dvisionworkshop.github.io
Reposted by Anand Bhattad

New paper about pictures: I identify trends in geometric perspective in my own drawings and photos, and compare them to how the original scenes looked. I discuss what these trends might say about art history and vision science. Published in _Art & Perception_. #visionscience
psyarxiv.com/pq8nb
psyarxiv.com/pq8nb
OSF
psyarxiv.com
February 6, 2025 at 10:58 PM
New paper about pictures: I identify trends in geometric perspective in my own drawings and photos, and compare them to how the original scenes looked. I discuss what these trends might say about art history and vision science. Published in _Art & Perception_. #visionscience
psyarxiv.com/pq8nb
psyarxiv.com/pq8nb
Encouraging to see a civilized & thoughtful discussion on a few papers in my AC batch. We need more reviewers like this!
Also chasing down a few reviewers to update their justification beyond 'my concerns were not addressed in the rebuttal, so I’ll maintain my original score.' 😅 #CVPR2025
Also chasing down a few reviewers to update their justification beyond 'my concerns were not addressed in the rebuttal, so I’ll maintain my original score.' 😅 #CVPR2025
February 6, 2025 at 4:26 PM
Encouraging to see a civilized & thoughtful discussion on a few papers in my AC batch. We need more reviewers like this!
Also chasing down a few reviewers to update their justification beyond 'my concerns were not addressed in the rebuttal, so I’ll maintain my original score.' 😅 #CVPR2025
Also chasing down a few reviewers to update their justification beyond 'my concerns were not addressed in the rebuttal, so I’ll maintain my original score.' 😅 #CVPR2025
Not a big fan of Borderline ratings in the review process. They offer an easy way for reviewers to be non-committal—or even lazy. I’ve never liked this, as it rarely adds value. Clear, decisive ratings with concrete justifications of a paper’s contributions are far more constructive. #CVPR2025
February 5, 2025 at 6:06 PM
Not a big fan of Borderline ratings in the review process. They offer an easy way for reviewers to be non-committal—or even lazy. I’ve never liked this, as it rarely adds value. Clear, decisive ratings with concrete justifications of a paper’s contributions are far more constructive. #CVPR2025
It's great to see renewed interest in Barrow and Tenenbaum's seminal 1978 work on "Intrinsic Images." This foundational paper has significantly influenced the field, even though it has historically received fewer citations than it deserves.
February 1, 2025 at 6:33 PM
It's great to see renewed interest in Barrow and Tenenbaum's seminal 1978 work on "Intrinsic Images." This foundational paper has significantly influenced the field, even though it has historically received fewer citations than it deserves.
Scholar Inbox provides the best paper recommendations—I rarely miss papers relevant to my interests or related to my work.
I wish this could be integrated with paper submission services to flag missing related works.
I wish this could be integrated with paper submission services to flag missing related works.

Excited to share that today our paper recommender platform www.scholar-inbox.com has reached 20k users! We hope to reach 100k by the end of the year.. Lots of new features are being worked on currently and rolled out soon.

January 17, 2025 at 1:50 AM
Scholar Inbox provides the best paper recommendations—I rarely miss papers relevant to my interests or related to my work.
I wish this could be integrated with paper submission services to flag missing related works.
I wish this could be integrated with paper submission services to flag missing related works.
🧵 1/3 Many at #CVPR2024 & #ECCV2024 asked what would be next in our workshop series.
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...
January 13, 2025 at 4:16 PM
🧵 1/3 Many at #CVPR2024 & #ECCV2024 asked what would be next in our workshop series.
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...
We're excited to announce "How to Stand Out in the Crowd?" at #CVPR2025 Nashville - our 4th community-building workshop featuring this incredible speaker lineup!
🔗 sites.google.com/view/standou...