



Sebastian Lehner
@sebaleh.bsky.social
Postdoc JKU Linz ELLIS: ML for sampling and optimization.
Reposted by Sebastian Lehner

Measuring AI Progress in Drug Discovery - A NEW LEADERBOARD IN TOWN
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744

November 19, 2025 at 6:52 AM
Measuring AI Progress in Drug Discovery - A NEW LEADERBOARD IN TOWN
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
2015-2025: turns out that there's hardly any improvement. AI bubble?
GPT is at 70% for this task, whereas the best methods get close to 85%.
Leaderboard: huggingface.co/spaces/ml-jk...
P: arxiv.org/abs/2511.14744
Reposted by Sebastian Lehner

Posting a few nice importance sampling-related finds
"Value-aware Importance Weighting for Off-policy Reinforcement Learning"
proceedings.mlr.press/v232/de-asis...
"Value-aware Importance Weighting for Off-policy Reinforcement Learning"
proceedings.mlr.press/v232/de-asis...

October 4, 2025 at 4:01 PM
Posting a few nice importance sampling-related finds
"Value-aware Importance Weighting for Off-policy Reinforcement Learning"
proceedings.mlr.press/v232/de-asis...
"Value-aware Importance Weighting for Off-policy Reinforcement Learning"
proceedings.mlr.press/v232/de-asis...
Reposted by Sebastian Lehner


September 18, 2025 at 6:59 PM
Reposted by Sebastian Lehner

I am very happy to finally share something I have been working on and off for the past year:
"The Information Dynamics of Generative Diffusion"
This paper connects entropy production, divergence of vector fields and spontaneous symmetry breaking
link: arxiv.org/abs/2508.19897
"The Information Dynamics of Generative Diffusion"
This paper connects entropy production, divergence of vector fields and spontaneous symmetry breaking
link: arxiv.org/abs/2508.19897

September 2, 2025 at 4:40 PM
I am very happy to finally share something I have been working on and off for the past year:
"The Information Dynamics of Generative Diffusion"
This paper connects entropy production, divergence of vector fields and spontaneous symmetry breaking
link: arxiv.org/abs/2508.19897
"The Information Dynamics of Generative Diffusion"
This paper connects entropy production, divergence of vector fields and spontaneous symmetry breaking
link: arxiv.org/abs/2508.19897
Reposted by Sebastian Lehner

xLSTM for multivariate time series anomaly detection: arxiv.org/abs/2506.22837
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.

July 1, 2025 at 8:30 AM
xLSTM for multivariate time series anomaly detection: arxiv.org/abs/2506.22837
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
“In our results, xLSTM showcases state-of-the-art accuracy, outperforming 23 popular anomaly detection baselines.”
Again, xLSTM excels in time series analysis.
Reposted by Sebastian Lehner

New paper on the generalization of Flow Matching www.arxiv.org/abs/2506.03719
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
June 18, 2025 at 8:08 AM
New paper on the generalization of Flow Matching www.arxiv.org/abs/2506.03719
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
Reposted by Sebastian Lehner

New preprint alert 🚨
How can you guide diffusion and flow-based generative models when data is scarce but you have domain knowledge? We introduce Minimum Excess Work, a physics-inspired method for efficiently integrating sparse constraints.
Thread below 👇https://arxiv.org/abs/2505.13375
How can you guide diffusion and flow-based generative models when data is scarce but you have domain knowledge? We introduce Minimum Excess Work, a physics-inspired method for efficiently integrating sparse constraints.
Thread below 👇https://arxiv.org/abs/2505.13375

May 26, 2025 at 9:13 AM
New preprint alert 🚨
How can you guide diffusion and flow-based generative models when data is scarce but you have domain knowledge? We introduce Minimum Excess Work, a physics-inspired method for efficiently integrating sparse constraints.
Thread below 👇https://arxiv.org/abs/2505.13375
How can you guide diffusion and flow-based generative models when data is scarce but you have domain knowledge? We introduce Minimum Excess Work, a physics-inspired method for efficiently integrating sparse constraints.
Thread below 👇https://arxiv.org/abs/2505.13375
Reposted by Sebastian Lehner

Need to predict bioactivity 🧪 but only have limited data ❌?
Try our interactive app for prompting MHNfs — a state-of-the-art model for few-shot molecule–property prediction. No coding or training needed. 🚀
📄 Paper:
pubs.acs.org/doi/10.1021/...
🖥️ App:
huggingface.co/spaces/ml-jk...
Try our interactive app for prompting MHNfs — a state-of-the-art model for few-shot molecule–property prediction. No coding or training needed. 🚀
📄 Paper:
pubs.acs.org/doi/10.1021/...
🖥️ App:
huggingface.co/spaces/ml-jk...

MHNfs: Prompting In-Context Bioactivity Predictions for Low-Data Drug Discovery
Today’s drug discovery increasingly relies on computational and machine learning approaches to identify novel candidates, yet data scarcity remains a significant challenge. To address this limitation,...
pubs.acs.org
May 13, 2025 at 8:27 AM
Need to predict bioactivity 🧪 but only have limited data ❌?
Try our interactive app for prompting MHNfs — a state-of-the-art model for few-shot molecule–property prediction. No coding or training needed. 🚀
📄 Paper:
pubs.acs.org/doi/10.1021/...
🖥️ App:
huggingface.co/spaces/ml-jk...
Try our interactive app for prompting MHNfs — a state-of-the-art model for few-shot molecule–property prediction. No coding or training needed. 🚀
📄 Paper:
pubs.acs.org/doi/10.1021/...
🖥️ App:
huggingface.co/spaces/ml-jk...
Reposted by Sebastian Lehner

I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589

Optimal Transport for Machine Learners
Optimal Transport is a foundational mathematical theory that connects optimization, partial differential equations, and probability. It offers a powerful framework for comparing probability distributi...
arxiv.org
May 13, 2025 at 5:18 AM
I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589
Reposted by Sebastian Lehner

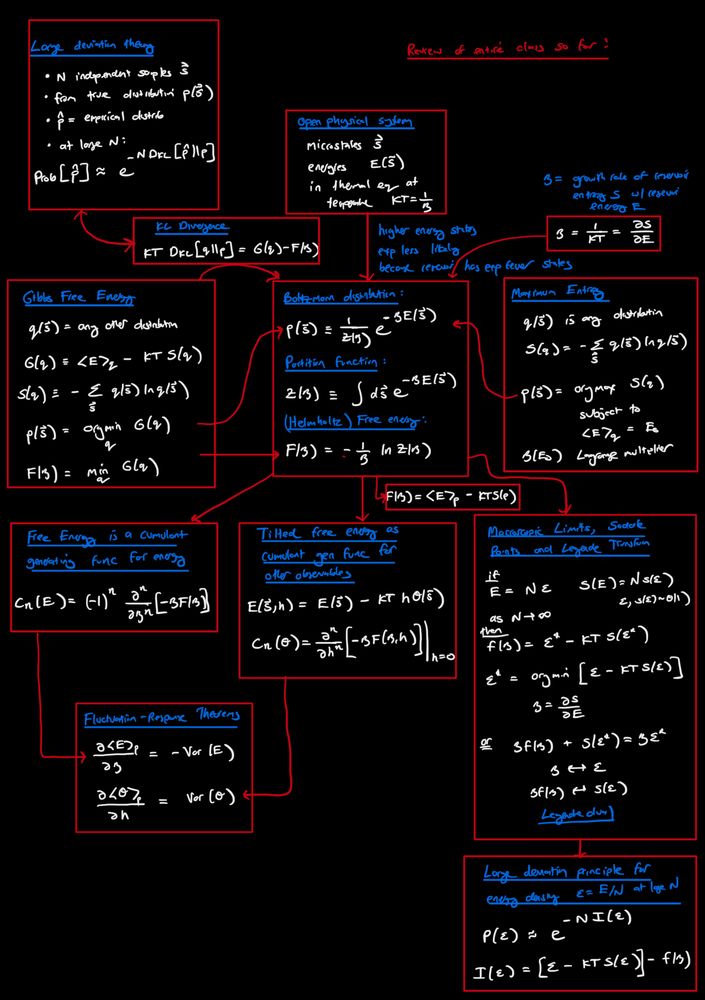
Many recent posts on free energy. Here is a summary from my class “Statistical mechanics of learning and computation” on the many relations between free energy, KL divergence, large deviation theory, entropy, Boltzmann distribution, cumulants, Legendre duality, saddle points, fluctuation-response…
May 2, 2025 at 7:22 PM
Many recent posts on free energy. Here is a summary from my class “Statistical mechanics of learning and computation” on the many relations between free energy, KL divergence, large deviation theory, entropy, Boltzmann distribution, cumulants, Legendre duality, saddle points, fluctuation-response…
Reposted by Sebastian Lehner

I asked "on the other platform" what were the most important improvements to the original 2017 transformer.
That was quite popular and here is a synthesis of the responses:
That was quite popular and here is a synthesis of the responses:
April 28, 2025 at 6:47 AM
I asked "on the other platform" what were the most important improvements to the original 2017 transformer.
That was quite popular and here is a synthesis of the responses:
That was quite popular and here is a synthesis of the responses:
Reposted by Sebastian Lehner

Come check out SDE Matching at the #ICLR2025 workshops, a new simulation-free framework for training fully general Latent/Neural SDEs (generalisation of diffusion and bridge models).
FPI: Morning poster session
DeLTa: Afternoon poster session
#SDE #Bayes #GenAI #Diffusion #Flow
FPI: Morning poster session
DeLTa: Afternoon poster session
#SDE #Bayes #GenAI #Diffusion #Flow

April 27, 2025 at 11:27 PM
Reposted by Sebastian Lehner

Excited to present our poster on Boltzmann priors for Implicit Transfer Operators tomorrow at @iclr-conf.bsky.social!
See you tomorrow at poster 13, 10-12:30.
See you tomorrow at poster 13, 10-12:30.

April 24, 2025 at 8:20 AM
Excited to present our poster on Boltzmann priors for Implicit Transfer Operators tomorrow at @iclr-conf.bsky.social!
See you tomorrow at poster 13, 10-12:30.
See you tomorrow at poster 13, 10-12:30.
Reposted by Sebastian Lehner

1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels

April 24, 2025 at 8:57 AM
1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
Reposted by Sebastian Lehner

My video interview with @quantamagazine.bsky.social about AI-designed physics experiments, AI as a Muse for new ideas in Science, and Artificial Scientists: www.youtube.com/watch?v=T_2Z...

The Scientist Building an 'Artificial Scientist'
YouTube video by Quanta Magazine
www.youtube.com
March 19, 2025 at 10:46 AM
My video interview with @quantamagazine.bsky.social about AI-designed physics experiments, AI as a Muse for new ideas in Science, and Artificial Scientists: www.youtube.com/watch?v=T_2Z...
Reposted by Sebastian Lehner
📢 AI-discovered Gravitational Wave Detectors
published in @apsphysics.bsky.social Phys.Rev.X, with Rana Adhikari & Yehonathan Drori @ligo.org @caltech.edu @mpi-scienceoflight.bsky.social
journals.aps.org/prx/abstract...
Extremely happy to see this paper online after 3.5 years of work.
🧵1/5
published in @apsphysics.bsky.social Phys.Rev.X, with Rana Adhikari & Yehonathan Drori @ligo.org @caltech.edu @mpi-scienceoflight.bsky.social
journals.aps.org/prx/abstract...
Extremely happy to see this paper online after 3.5 years of work.
🧵1/5

Digital Discovery of Interferometric Gravitational Wave Detectors
AI-driven design of gravitational wave detectors uncovers approaches that surpass current plans, potentially boosting sensitivity more than tenfold.
journals.aps.org
April 14, 2025 at 5:32 PM
📢 AI-discovered Gravitational Wave Detectors
published in @apsphysics.bsky.social Phys.Rev.X, with Rana Adhikari & Yehonathan Drori @ligo.org @caltech.edu @mpi-scienceoflight.bsky.social
journals.aps.org/prx/abstract...
Extremely happy to see this paper online after 3.5 years of work.
🧵1/5
published in @apsphysics.bsky.social Phys.Rev.X, with Rana Adhikari & Yehonathan Drori @ligo.org @caltech.edu @mpi-scienceoflight.bsky.social
journals.aps.org/prx/abstract...
Extremely happy to see this paper online after 3.5 years of work.
🧵1/5
Reposted by Sebastian Lehner

We have been reworking the Quickstart guide of POT to show multiple examples of OT with the unified API that facilitates access to OT value/plan/potentials. It allows to select regularization/unbalancedness/lowrank/Gaussian OT with just a few parameters. pythonot.github.io/master/auto_...

March 26, 2025 at 7:39 AM
We have been reworking the Quickstart guide of POT to show multiple examples of OT with the unified API that facilitates access to OT value/plan/potentials. It allows to select regularization/unbalancedness/lowrank/Gaussian OT with just a few parameters. pythonot.github.io/master/auto_...
Reposted by Sebastian Lehner
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Meet the fastest 7B language model out there. Based on the mLSTM!
P: arxiv.org/abs/2503.13427
Meet the fastest 7B language model out there. Based on the mLSTM!
P: arxiv.org/abs/2503.13427

March 18, 2025 at 6:33 AM
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Meet the fastest 7B language model out there. Based on the mLSTM!
P: arxiv.org/abs/2503.13427
Meet the fastest 7B language model out there. Based on the mLSTM!
P: arxiv.org/abs/2503.13427
Reposted by Sebastian Lehner

Tweedie's formula is super important in diffusion models & is also one of the cornerstones of empirical Bayes methods.
Given how easy it is to derive, it's surprising how recently it was discovered ('50s). It was published a while later when Tweedie wrote Stein about it
1/n
Given how easy it is to derive, it's surprising how recently it was discovered ('50s). It was published a while later when Tweedie wrote Stein about it
1/n

March 18, 2025 at 6:12 AM
Tweedie's formula is super important in diffusion models & is also one of the cornerstones of empirical Bayes methods.
Given how easy it is to derive, it's surprising how recently it was discovered ('50s). It was published a while later when Tweedie wrote Stein about it
1/n
Given how easy it is to derive, it's surprising how recently it was discovered ('50s). It was published a while later when Tweedie wrote Stein about it
1/n
Reposted by Sebastian Lehner
Opportunity to work with @hochreitersepp.bsky.social , @jobrandstetter.bsky.social , and me!!
We have many open positions in machine learning, deep learning, LLMs!! Both for PostDocs and PhDs!
Join us!
We have many open positions in machine learning, deep learning, LLMs!! Both for PostDocs and PhDs!
Join us!
xLSTM for Automated Stock Trading: arxiv.org/abs/2503.09655
xLSTM outperforms LSTM.
"These findings mark the potential of xLSTM for enhancing DRL-based stock trading systems."
This reinforcement learning approach uses xLSTM in both actor and critic components, which increases the performance.
xLSTM outperforms LSTM.
"These findings mark the potential of xLSTM for enhancing DRL-based stock trading systems."
This reinforcement learning approach uses xLSTM in both actor and critic components, which increases the performance.

A Deep Reinforcement Learning Approach to Automated Stock Trading, using xLSTM Networks
Traditional Long Short-Term Memory (LSTM) networks are effective for handling sequential data but have limitations such as gradient vanishing and difficulty in capturing long-term dependencies, which ...
arxiv.org
March 14, 2025 at 12:31 PM
Opportunity to work with @hochreitersepp.bsky.social , @jobrandstetter.bsky.social , and me!!
We have many open positions in machine learning, deep learning, LLMs!! Both for PostDocs and PhDs!
Join us!
We have many open positions in machine learning, deep learning, LLMs!! Both for PostDocs and PhDs!
Join us!
Reposted by Sebastian Lehner

We provide a classical simulation of DWave quantum "s-word" paper.
Here it is arxiv.org/abs/2503.08247 , great work by Linda Mauron at the CQS Lab, check it out! (1/4)
Here it is arxiv.org/abs/2503.08247 , great work by Linda Mauron at the CQS Lab, check it out! (1/4)

Challenging the Quantum Advantage Frontier with Large-Scale Classical Simulations of Annealing Dynamics
Recent demonstrations of D-Wave's annealing-based quantum simulators have established new benchmarks for quantum computational advantage [arXiv:2403.00910]. However, the precise location of the classi...
arxiv.org
March 12, 2025 at 9:30 AM
We provide a classical simulation of DWave quantum "s-word" paper.
Here it is arxiv.org/abs/2503.08247 , great work by Linda Mauron at the CQS Lab, check it out! (1/4)
Here it is arxiv.org/abs/2503.08247 , great work by Linda Mauron at the CQS Lab, check it out! (1/4)
Reposted by Sebastian Lehner

I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century"
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
March 6, 2025 at 1:03 PM
I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century"
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Here: thomwolf.io/blog/scienti...
It's an extension of this interview discussion from the AI summit: youtu.be/AxBd3G0lFLs?...
Reposted by Sebastian Lehner

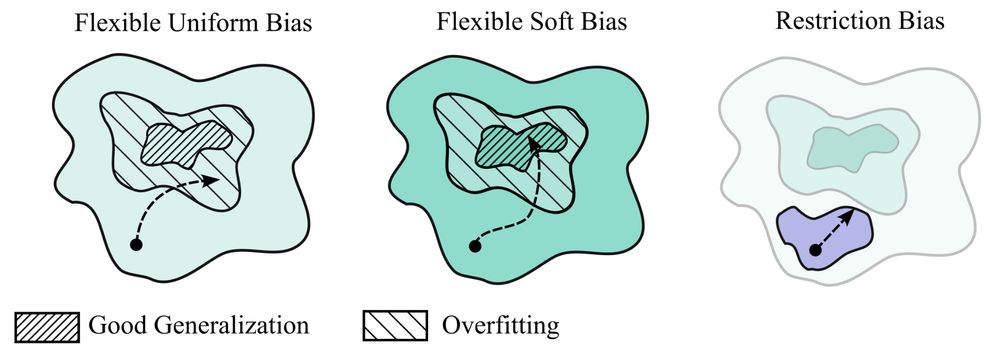
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
March 5, 2025 at 3:38 PM
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
Reposted by Sebastian Lehner

Thanks @zlatko-minev.bsky.social and hello bluesky world!
March 4, 2025 at 3:47 PM
Thanks @zlatko-minev.bsky.social and hello bluesky world!
Reposted by Sebastian Lehner

Luca (Martino) once told me (when I said "MCMC does not have weights") that this is incorrect (in his Sicilian style): When you reject in MCMC, you increase the weight of the current sample. Chains do have replicates, can be written like a weighted sample. High rejection rate *is* weight degeneracy.
February 28, 2025 at 11:29 AM
Luca (Martino) once told me (when I said "MCMC does not have weights") that this is incorrect (in his Sicilian style): When you reject in MCMC, you increase the weight of the current sample. Chains do have replicates, can be written like a weighted sample. High rejection rate *is* weight degeneracy.