




Reposted by Pushpdeep

The lecture was followed by a hands-on activity where Abhisek Dash and @pushpdeep.bsky.social (MPI-SWS) guided the participants through the challenges of validating labels of content posted on Bluesky.

September 12, 2025 at 11:22 AM
The lecture was followed by a hands-on activity where Abhisek Dash and @pushpdeep.bsky.social (MPI-SWS) guided the participants through the challenges of validating labels of content posted on Bluesky.
Reposted by Pushpdeep

📄NEW PAPER📄
Ever wondered content people actually pay *attention* to online? Our new research reveals that you likely pay attention to far more varied political content than your likes and shares suggest
Ever wondered content people actually pay *attention* to online? Our new research reveals that you likely pay attention to far more varied political content than your likes and shares suggest

March 25, 2025 at 12:04 PM
📄NEW PAPER📄
Ever wondered content people actually pay *attention* to online? Our new research reveals that you likely pay attention to far more varied political content than your likes and shares suggest
Ever wondered content people actually pay *attention* to online? Our new research reveals that you likely pay attention to far more varied political content than your likes and shares suggest
Reposted by Pushpdeep

Matthias Orlikowski, Jiaxin Pei, Paul R\"ottger, Philipp Cimiano, David Jurgens, Dirk Hovy
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
https://arxiv.org/abs/2502.20897
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
https://arxiv.org/abs/2502.20897
March 3, 2025 at 7:40 AM
Matthias Orlikowski, Jiaxin Pei, Paul R\"ottger, Philipp Cimiano, David Jurgens, Dirk Hovy
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
https://arxiv.org/abs/2502.20897
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
https://arxiv.org/abs/2502.20897
Reposted by Pushpdeep
Artem Vazhentsev, Ivan Sviridov, Alvard Barseghyan, Gleb Kuzmin, Alexander Panchenko, Aleksandr Nesterov, Artem Shelmanov, Maxim Panov
Uncertainty-aware abstention in medical diagnosis based on medical texts
https://arxiv.org/abs/2502.18050
Uncertainty-aware abstention in medical diagnosis based on medical texts
https://arxiv.org/abs/2502.18050
February 26, 2025 at 8:07 AM
Artem Vazhentsev, Ivan Sviridov, Alvard Barseghyan, Gleb Kuzmin, Alexander Panchenko, Aleksandr Nesterov, Artem Shelmanov, Maxim Panov
Uncertainty-aware abstention in medical diagnosis based on medical texts
https://arxiv.org/abs/2502.18050
Uncertainty-aware abstention in medical diagnosis based on medical texts
https://arxiv.org/abs/2502.18050
Reposted by Pushpdeep
Tushar Aggarwal, Kumar Tanmay, Ayush Agrawal, Kumar Ayush, Hamid Palangi, Paul Pu Liang
Language Models' Factuality Depends on the Language of Inquiry
https://arxiv.org/abs/2502.17955
Language Models' Factuality Depends on the Language of Inquiry
https://arxiv.org/abs/2502.17955
February 26, 2025 at 8:26 AM
Tushar Aggarwal, Kumar Tanmay, Ayush Agrawal, Kumar Ayush, Hamid Palangi, Paul Pu Liang
Language Models' Factuality Depends on the Language of Inquiry
https://arxiv.org/abs/2502.17955
Language Models' Factuality Depends on the Language of Inquiry
https://arxiv.org/abs/2502.17955
Reposted by Pushpdeep

Every day we get closer and closer to OG information retrieval , imagine spending billions of dollars to do the same thing that Tf-IDF did
noperator.dev/posts/docume...
noperator.dev/posts/docume...
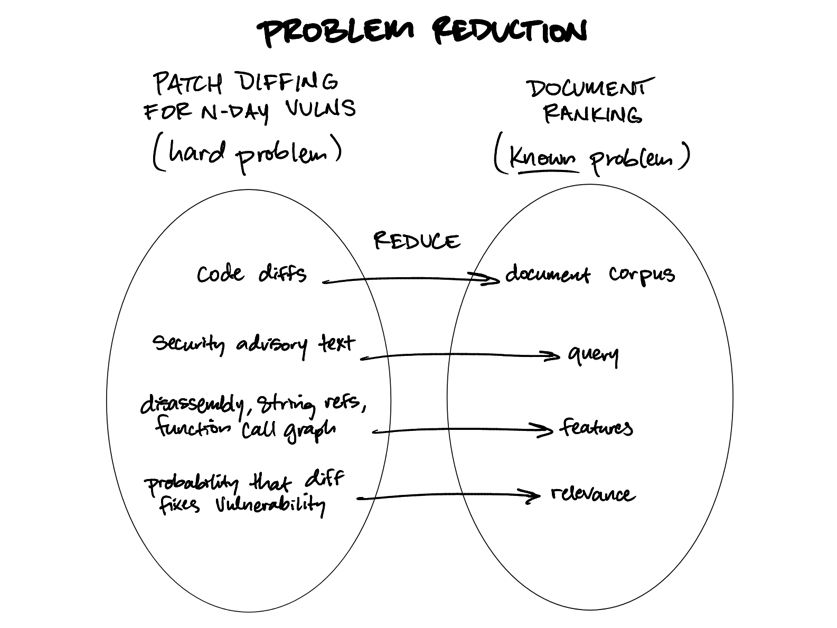
Hard problems that reduce to document ranking
There are two claims I’d like to make:
LLMs can be used effectively1 for listwise document ranking. Some complex problems can (surprisingly) be solved by transforming them into document ranking proble...
noperator.dev
February 26, 2025 at 2:07 AM
Every day we get closer and closer to OG information retrieval , imagine spending billions of dollars to do the same thing that Tf-IDF did
noperator.dev/posts/docume...
noperator.dev/posts/docume...
Reposted by Pushpdeep

A new book on mixed languages in South Asia has just been released! @PenguinBooks

February 23, 2025 at 8:23 PM
A new book on mixed languages in South Asia has just been released! @PenguinBooks
Reposted by Pushpdeep

Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)

February 21, 2025 at 6:15 PM
Do you want to know what information LLMs prioritize in text synthesis tasks? Here's a short 🧵 about our new paper, led by Jan Trienes: an interpretable framework for salience analysis in LLMs.
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
First of all, information salience is a fuzzy concept. So how can we even measure it? (1/6)
Reposted by Pushpdeep
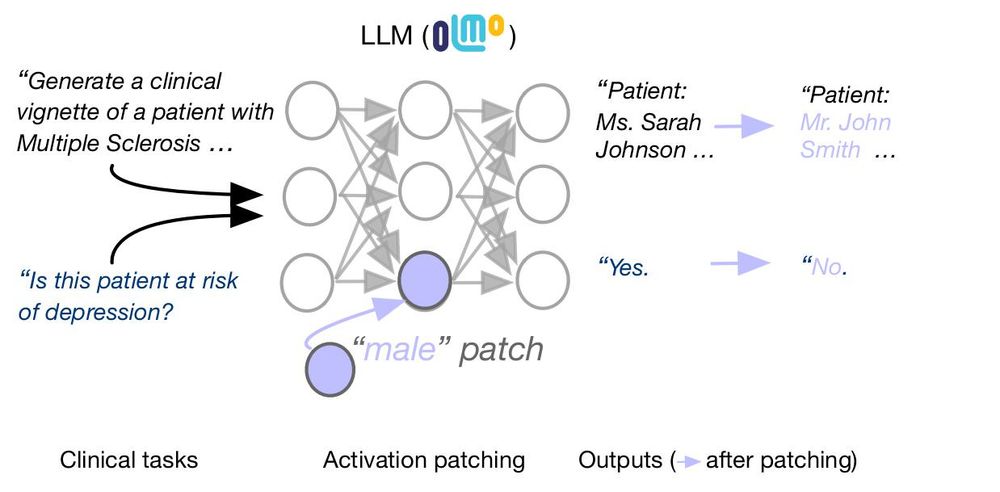
LLMs are known to perpetuate social biases in clinical tasks. Can we locate and intervene upon LLM activations that encode patient demographics like gender and race? 🧵
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319
February 22, 2025 at 4:18 AM
LLMs are known to perpetuate social biases in clinical tasks. Can we locate and intervene upon LLM activations that encode patient demographics like gender and race? 🧵
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319
Work w/ @arnabsensharma.bsky.social, @silvioamir.bsky.social, @davidbau.bsky.social, @byron.bsky.social
arxiv.org/abs/2502.13319
Reposted by Pushpdeep

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 6:10 PM
After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
Reposted by Pushpdeep

🚨New arXiv preprint!🚨
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov

February 19, 2025 at 3:50 PM
🚨New arXiv preprint!🚨
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
LLMs can hallucinate - but did you know they can do so with high certainty even when they know the correct answer? 🤯
We find those hallucinations in our latest work with @itay-itzhak.bsky.social, @fbarez.bsky.social, @gabistanovsky.bsky.social and Yonatan Belinkov
Reposted by Pushpdeep

🚀Very excited about my new paper!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!

February 17, 2025 at 4:06 AM
🚀Very excited about my new paper!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!
Reposted by Pushpdeep
We have a new version of our 𝕡𝕣𝕠𝕞𝕡𝕥𝕤𝕥𝕒𝕓𝕚𝕝𝕚𝕥𝕪 paper now on arxiv!
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...

February 18, 2025 at 11:46 AM
We have a new version of our 𝕡𝕣𝕠𝕞𝕡𝕥𝕤𝕥𝕒𝕓𝕚𝕝𝕚𝕥𝕪 paper now on arxiv!
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
This is a significant update that test *a lot* more data, suggests post-processing techniques, outlines how to compare across models, and tests with new models...
Reposted by Pushpdeep
Read more in this issue of the Linguistic Discovery newsletter, where I explore the Trisolaran language from the Three-Body Problem and how it compares to human language!
https://buff.ly/3ErakOl
#Trisolarans #aliens #xenolinguistics #ThreeBodyProblem #linguistics #language #SciFi #review
https://buff.ly/3ErakOl
#Trisolarans #aliens #xenolinguistics #ThreeBodyProblem #linguistics #language #SciFi #review

What if we could hear each other's thoughts? The linguistics of The Three-Body Problem
Imagine if every word you thought could be heard by everyone around you. In this world, thinking would be the same as communicating. What would language—and society—be like?
buff.ly
February 8, 2025 at 3:25 PM
Read more in this issue of the Linguistic Discovery newsletter, where I explore the Trisolaran language from the Three-Body Problem and how it compares to human language!
https://buff.ly/3ErakOl
#Trisolarans #aliens #xenolinguistics #ThreeBodyProblem #linguistics #language #SciFi #review
https://buff.ly/3ErakOl
#Trisolarans #aliens #xenolinguistics #ThreeBodyProblem #linguistics #language #SciFi #review
Reposted by Pushpdeep
Our workshop has been extended till Feb 20. We are looking forward for your papers at NAACL's Queer in AI workshop.
1/7 🌈 BIG NEWS ALERT! The hottest Queer in AI workshop is back - and this time we're official! We're thrilled to announce we'll be at #NAACL2025 as an official workshop, meaning your work can now be published in the ACL anthology! 🎉
February 3, 2025 at 2:10 PM
Our workshop has been extended till Feb 20. We are looking forward for your papers at NAACL's Queer in AI workshop.
Reposted by Pushpdeep

This is a good start!! More *CL conferences should come 😍
@aaclmeeting.bsky.social
@aaclmeeting.bsky.social

February 1, 2025 at 1:32 PM
This is a good start!! More *CL conferences should come 😍
@aaclmeeting.bsky.social
@aaclmeeting.bsky.social
Reposted by Pushpdeep

Programming languages: "We are just a way to operate computers in a way that makes sense to humans."
Programming languages [takes a big joint hit]: "What if there were 5 kinds of nothingness?"
Programming languages [takes a big joint hit]: "What if there were 5 kinds of nothingness?"
January 31, 2025 at 8:51 AM
Programming languages: "We are just a way to operate computers in a way that makes sense to humans."
Programming languages [takes a big joint hit]: "What if there were 5 kinds of nothingness?"
Programming languages [takes a big joint hit]: "What if there were 5 kinds of nothingness?"
Reposted by Pushpdeep

A useful oversimplification
Instruction finetuning (IFT/SFT): imprinting features or shape in responses
Preference finetuning (RLHF/DPO/etc): style
Reinforcement finetuning (RFT/RLVR/etc): learning new behaviors
Instruction finetuning (IFT/SFT): imprinting features or shape in responses
Preference finetuning (RLHF/DPO/etc): style
Reinforcement finetuning (RFT/RLVR/etc): learning new behaviors
January 31, 2025 at 2:31 PM
A useful oversimplification
Instruction finetuning (IFT/SFT): imprinting features or shape in responses
Preference finetuning (RLHF/DPO/etc): style
Reinforcement finetuning (RFT/RLVR/etc): learning new behaviors
Instruction finetuning (IFT/SFT): imprinting features or shape in responses
Preference finetuning (RLHF/DPO/etc): style
Reinforcement finetuning (RFT/RLVR/etc): learning new behaviors
Reposted by Pushpdeep

📄 New preprint: "Collecting Cost-Effective, High-Quality Truthfulness Assessments with LLM Summarized Evidence"
We show: fact checking w/ crowd workers is more efficient when using LLM summaries, quality doesn't suffer.
arxiv.org/abs/2501.18265
We show: fact checking w/ crowd workers is more efficient when using LLM summaries, quality doesn't suffer.
arxiv.org/abs/2501.18265

Collecting Cost-Effective, High-Quality Truthfulness Assessments with LLM Summarized Evidence
With the degradation of guardrails against mis- and disinformation online, it is more critical than ever to be able to effectively combat it. In this paper, we explore the efficiency and effectiveness...
arxiv.org
January 31, 2025 at 1:18 PM
📄 New preprint: "Collecting Cost-Effective, High-Quality Truthfulness Assessments with LLM Summarized Evidence"
We show: fact checking w/ crowd workers is more efficient when using LLM summaries, quality doesn't suffer.
arxiv.org/abs/2501.18265
We show: fact checking w/ crowd workers is more efficient when using LLM summaries, quality doesn't suffer.
arxiv.org/abs/2501.18265
Reposted by Pushpdeep

How can we interpret LLM features at scale? 🤔
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
January 28, 2025 at 7:34 PM
How can we interpret LLM features at scale? 🤔
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!
We propose efficient output-centric methods that better predict the steering effect of a feature.
New preprint led by @yoav.ml 🧵1/
Reposted by Pushpdeep

Roughly 6,000 readers answered our poll, with many declaring that Bluesky was nicer, kinder and less antagonistic to science than X
https://go.nature.com/42tH8Ai
https://go.nature.com/42tH8Ai

Bluesky’s science takeover: 70% of Nature poll respondents use platform
Roughly 6,000 readers answered our poll, with many declaring that Bluesky was nicer, kinder and less antagonistic to science than X.
go.nature.com
January 24, 2025 at 11:52 AM
Roughly 6,000 readers answered our poll, with many declaring that Bluesky was nicer, kinder and less antagonistic to science than X
https://go.nature.com/42tH8Ai
https://go.nature.com/42tH8Ai
Reposted by Pushpdeep

#ThrowbackThursday #NLProc
"My Answer is C" by Wang et al. highlights that first-token evaluation does not accurately reflect LLM behavior in user interactions, urging against sole reliance on this method.
"My Answer is C" by Wang et al. highlights that first-token evaluation does not accurately reflect LLM behavior in user interactions, urging against sole reliance on this method.

“My Answer is C”: First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
Xinpeng Wang, Bolei Ma, Chengzhi Hu, Leon Weber-Genzel, Paul Röttger, Frauke Kreuter, Dirk Hovy, Barbara Plank. Findings of the Association for Computational Linguistics: ACL 2024. 2024.
buff.ly
January 16, 2025 at 3:00 PM
#ThrowbackThursday #NLProc
"My Answer is C" by Wang et al. highlights that first-token evaluation does not accurately reflect LLM behavior in user interactions, urging against sole reliance on this method.
"My Answer is C" by Wang et al. highlights that first-token evaluation does not accurately reflect LLM behavior in user interactions, urging against sole reliance on this method.
Reposted by Pushpdeep

📕 My dissertation on #NLP for #Violence Studies has been published: mediatum.ub.tum.de?id=1751256
I've been looking at #abusive behavior online, as well as sharing of personal experiences with violence, incl. psychological #trauma.
Excited to push this research forward and connect with others 🌐
I've been looking at #abusive behavior online, as well as sharing of personal experiences with violence, incl. psychological #trauma.
Excited to push this research forward and connect with others 🌐
mediaTUM - Medien- und Publikationsserver
mediatum.ub.tum.de
January 17, 2025 at 6:12 PM
📕 My dissertation on #NLP for #Violence Studies has been published: mediatum.ub.tum.de?id=1751256
I've been looking at #abusive behavior online, as well as sharing of personal experiences with violence, incl. psychological #trauma.
Excited to push this research forward and connect with others 🌐
I've been looking at #abusive behavior online, as well as sharing of personal experiences with violence, incl. psychological #trauma.
Excited to push this research forward and connect with others 🌐