




Mechanical Dirk
@mechanicaldirk.bsky.social
Training big models at @ai2.bsky.social.
Reposted by Mechanical Dirk

I'm excited to announce my RLHF Book is now in pre-order for the @manning.com Early Access Program (MEAP), and for this milestone it's 50% off.
Excited to land in print in early 2026! Lots of improvements coming soon.
Thanks for the support!
hubs.la/Q03Tc37Q0
Excited to land in print in early 2026! Lots of improvements coming soon.
Thanks for the support!
hubs.la/Q03Tc37Q0

November 14, 2025 at 9:02 PM
I'm excited to announce my RLHF Book is now in pre-order for the @manning.com Early Access Program (MEAP), and for this milestone it's 50% off.
Excited to land in print in early 2026! Lots of improvements coming soon.
Thanks for the support!
hubs.la/Q03Tc37Q0
Excited to land in print in early 2026! Lots of improvements coming soon.
Thanks for the support!
hubs.la/Q03Tc37Q0
Incredible work by Apple's UX department, enabling three different corner radii at the same time 🙈

November 12, 2025 at 11:34 PM
Incredible work by Apple's UX department, enabling three different corner radii at the same time 🙈
Reposted by Mechanical Dirk

While reviewing for #CHI2026, I've noticed four new writing issues in #HCI papers, likely due to an increased use of #LLMs / #AI. I describe them here - and how to fix them: dbuschek.medium.com/when-llms-wr...

When LLMs Write Our Papers
Four writing issues I notice as a reviewer — and how to fix them
dbuschek.medium.com
October 23, 2025 at 2:15 PM
While reviewing for #CHI2026, I've noticed four new writing issues in #HCI papers, likely due to an increased use of #LLMs / #AI. I describe them here - and how to fix them: dbuschek.medium.com/when-llms-wr...
Reposted by Mechanical Dirk

We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵

August 18, 2025 at 7:02 PM
We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵
Mein Dreijähriger: "Ich will den Lerns Geschichte Podcast hören!"
Was ist denn "Lerns Geschichte"?
Zwei Minuten später im Radio: "Lernen's a bissel @geschichte.fm, dann ..." 😲
Was ist denn "Lerns Geschichte"?
Zwei Minuten später im Radio: "Lernen's a bissel @geschichte.fm, dann ..." 😲
August 18, 2025 at 2:33 AM
Mein Dreijähriger: "Ich will den Lerns Geschichte Podcast hören!"
Was ist denn "Lerns Geschichte"?
Zwei Minuten später im Radio: "Lernen's a bissel @geschichte.fm, dann ..." 😲
Was ist denn "Lerns Geschichte"?
Zwei Minuten später im Radio: "Lernen's a bissel @geschichte.fm, dann ..." 😲
This project is a perfect model of an OLMo contribution. Well scoped, practical, sound theoretical underpinnings, and @lambdaviking.bsky.social
submitted the paper 24h before the deadline 😍.
It's integrated into the OLMo trainer here: github.com/allenai/OLMo...
submitted the paper 24h before the deadline 😍.
It's integrated into the OLMo trainer here: github.com/allenai/OLMo...
As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency. but we found gaps between the methods in the literature and our practical needs for training OLMo. 🧵

June 3, 2025 at 5:06 PM
This project is a perfect model of an OLMo contribution. Well scoped, practical, sound theoretical underpinnings, and @lambdaviking.bsky.social
submitted the paper 24h before the deadline 😍.
It's integrated into the OLMo trainer here: github.com/allenai/OLMo...
submitted the paper 24h before the deadline 😍.
It's integrated into the OLMo trainer here: github.com/allenai/OLMo...
Finally, OLMo 1B. This is the most commonly requested OLMo feature l, and it's finally here.
We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.

May 1, 2025 at 10:32 PM
Finally, OLMo 1B. This is the most commonly requested OLMo feature l, and it's finally here.
Reposted by Mechanical Dirk

I'm in Singapore for @iclr-conf.bsky.social ! Come check out our spotlight paper on the environmental impact of training OLMo (link in next tweet) during the Saturday morning poster session from 10-12:30 -- happy to chat about this or anything else! DMs should be open, email works too
April 23, 2025 at 3:22 PM
I'm in Singapore for @iclr-conf.bsky.social ! Come check out our spotlight paper on the environmental impact of training OLMo (link in next tweet) during the Saturday morning poster session from 10-12:30 -- happy to chat about this or anything else! DMs should be open, email works too
Came across arxiv.org/pdf/2504.05058 today. What a cool example of work you can do when LLM training data is open!
arxiv.org
April 18, 2025 at 5:46 PM
Came across arxiv.org/pdf/2504.05058 today. What a cool example of work you can do when LLM training data is open!
Reposted by Mechanical Dirk
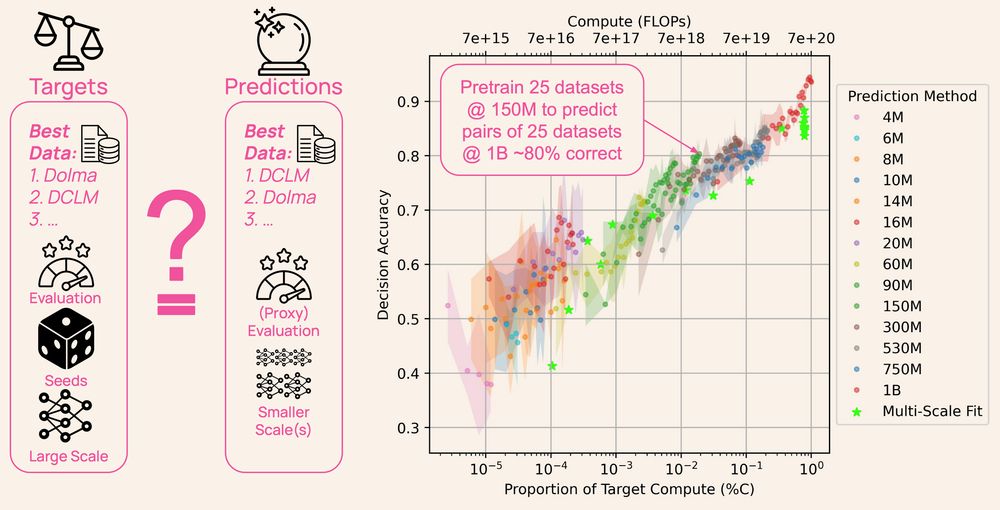
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
April 15, 2025 at 1:01 PM
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
Reposted by Mechanical Dirk

Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
April 9, 2025 at 1:37 PM
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
The fact that my Bsky feed is all tariffs and none Llama 4 means the platform is pretty much cooked for research purposes.
April 7, 2025 at 4:15 PM
The fact that my Bsky feed is all tariffs and none Llama 4 means the platform is pretty much cooked for research purposes.
Reposted by Mechanical Dirk

We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words.
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵

March 21, 2025 at 4:48 PM
We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words.
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
Error bars! @hails.computer will be so proud!

we released olmo 32b today! ☺️
🐟our largest & best fully open model to-date
🐠right up there w similar size weights-only models from big companies on popular benchmarks
🐡but we used way less compute & all our data, ckpts, code, recipe are free & open
made a nice plot of our post-trained results!✌️
🐟our largest & best fully open model to-date
🐠right up there w similar size weights-only models from big companies on popular benchmarks
🐡but we used way less compute & all our data, ckpts, code, recipe are free & open
made a nice plot of our post-trained results!✌️
March 13, 2025 at 10:32 PM
Error bars! @hails.computer will be so proud!
Reposted by Mechanical Dirk
Introducing olmOCR, our open-source tool to extract clean plain text from PDFs!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
February 25, 2025 at 5:04 PM
Introducing olmOCR, our open-source tool to extract clean plain text from PDFs!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!
Reposted by Mechanical Dirk
We took our most efficient model and made an open-source iOS app📱but why?
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ

Ai2 OLMoE: Fully open source, running entirely on-device
YouTube video by Ai2
youtu.be
February 11, 2025 at 2:04 PM
We took our most efficient model and made an open-source iOS app📱but why?
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
14.8T tokens in 2.8M hours is about 1500 tokens per second. That's a very good number for 37B active parameters, but by no means unbelievable.
January 26, 2025 at 12:57 AM
14.8T tokens in 2.8M hours is about 1500 tokens per second. That's a very good number for 37B active parameters, but by no means unbelievable.
Reposted by Mechanical Dirk
Behind the scenes with what its like to build language models and pursue (hopefully) cutting edge AI research
Interviewing OLMo 2 leads: Open secrets of training language models
What we have learned and are going to do next.
YouTube: https://buff.ly/40IlSFF
Podcast / notes:
Interviewing OLMo 2 leads: Open secrets of training language models
What we have learned and are going to do next.
YouTube: https://buff.ly/40IlSFF
Podcast / notes:

Interviewing OLMo 2 leads: Open secrets of training language models
What we have learned and are going to do next.
buff.ly
January 22, 2025 at 3:52 PM
Behind the scenes with what its like to build language models and pursue (hopefully) cutting edge AI research
Interviewing OLMo 2 leads: Open secrets of training language models
What we have learned and are going to do next.
YouTube: https://buff.ly/40IlSFF
Podcast / notes:
Interviewing OLMo 2 leads: Open secrets of training language models
What we have learned and are going to do next.
YouTube: https://buff.ly/40IlSFF
Podcast / notes:
In November, every post here was about NLP. Now it's all about TikTok. We're doing the Twitter speed run.
January 19, 2025 at 8:15 PM
In November, every post here was about NLP. Now it's all about TikTok. We're doing the Twitter speed run.
A few days ago, we did finally release the OLMo 2 tech report: arxiv.org/pdf/2501.00656. There is a lot of good stuff in there, but the stability work we did over the summer makes me particularly proud.
arxiv.org
January 6, 2025 at 8:03 PM
A few days ago, we did finally release the OLMo 2 tech report: arxiv.org/pdf/2501.00656. There is a lot of good stuff in there, but the stability work we did over the summer makes me particularly proud.
Reposted by Mechanical Dirk
Everyone wants open-source language models but no one wants to lift these heavy ass weights.
We just released our paper "2 OLMo 2 Furious"
Can't stop us in 2025. Links below.
We just released our paper "2 OLMo 2 Furious"
Can't stop us in 2025. Links below.

January 3, 2025 at 7:13 PM
Everyone wants open-source language models but no one wants to lift these heavy ass weights.
We just released our paper "2 OLMo 2 Furious"
Can't stop us in 2025. Links below.
We just released our paper "2 OLMo 2 Furious"
Can't stop us in 2025. Links below.
Some people seem to believe that LLMs give inoffensive, milquetoast answers because of overblown safety concerns ("Because of the woke!"). But that's not it.
LLMs give bland answers because they produce the average of what anyone would have said on the Internet.
LLMs give bland answers because they produce the average of what anyone would have said on the Internet.
December 25, 2024 at 4:23 AM
Some people seem to believe that LLMs give inoffensive, milquetoast answers because of overblown safety concerns ("Because of the woke!"). But that's not it.
LLMs give bland answers because they produce the average of what anyone would have said on the Internet.
LLMs give bland answers because they produce the average of what anyone would have said on the Internet.
It seems to me the second most common language spoken in the halls of NeurIPS is German.
December 14, 2024 at 1:08 AM
It seems to me the second most common language spoken in the halls of NeurIPS is German.
Reposted by Mechanical Dirk
Made a list of resources for open source language models with @soldaini.net ahead of the tutorial tomorrow at 930 AM.
github.com/allenai/awes...
github.com/allenai/awes...
GitHub - allenai/awesome-open-source-lms: Friends of OLMo and their links.
Friends of OLMo and their links. Contribute to allenai/awesome-open-source-lms development by creating an account on GitHub.
github.com
December 10, 2024 at 1:25 AM
Made a list of resources for open source language models with @soldaini.net ahead of the tutorial tomorrow at 930 AM.
github.com/allenai/awes...
github.com/allenai/awes...
Reposted by Mechanical Dirk
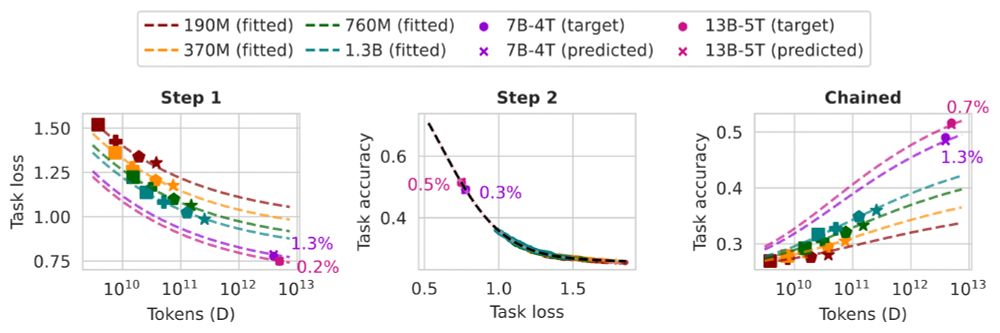
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.