




Jonathan Frankle
@jfrankle.com
Chief AI Scientist at Databricks. Founding team at MosaicML. MIT/Princeton alum. Lottery ticket enthusiast. Working on data intelligence.
Reposted by Jonathan Frankle

This is how it's done.
A strong and principled response by WilmerHale to the illegal Executive Order attack - a form of attempted government intimidation declared unconstitutional by a federal judge.
This is how to guard the rule of law.
A strong and principled response by WilmerHale to the illegal Executive Order attack - a form of attempted government intimidation declared unconstitutional by a federal judge.
This is how to guard the rule of law.
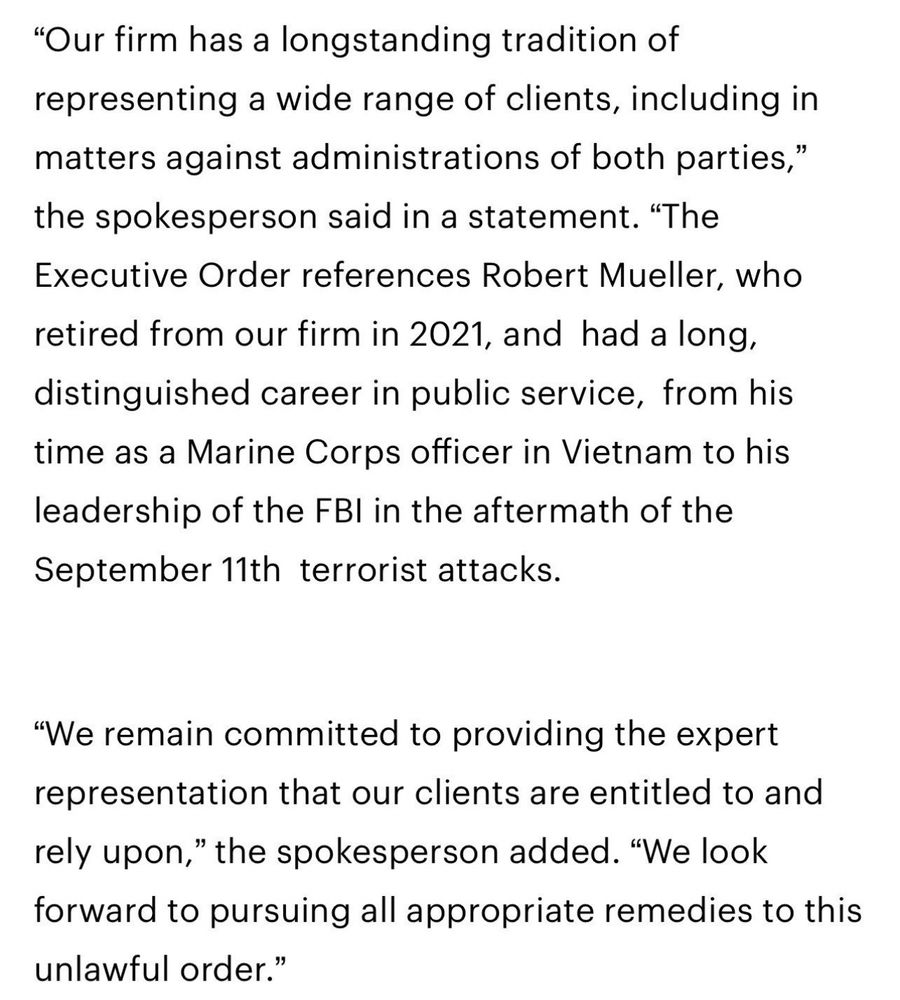
March 28, 2025 at 12:59 AM
This is how it's done.
A strong and principled response by WilmerHale to the illegal Executive Order attack - a form of attempted government intimidation declared unconstitutional by a federal judge.
This is how to guard the rule of law.
A strong and principled response by WilmerHale to the illegal Executive Order attack - a form of attempted government intimidation declared unconstitutional by a federal judge.
This is how to guard the rule of law.
The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...

TAO: Using test-time compute to train efficient LLMs without labeled data
LIFT fine-tunes LLMs without labels using reinforcement learning, boosting performance on enterprise tasks.
www.databricks.com
March 25, 2025 at 5:19 PM
The hardest part about finetuning is that people don't have labeled data. Today, @databricks.bsky.social introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data. www.databricks.com/blog/tao-usi...
Reposted by Jonathan Frankle

Join @kumarde.bsky.social Bryan, and me in CSE tomorrow as we do Hot Ones for Academics. My normally spicy research takes will get even spicier

February 27, 2025 at 1:38 AM
Join @kumarde.bsky.social Bryan, and me in CSE tomorrow as we do Hot Ones for Academics. My normally spicy research takes will get even spicier
Reposted by Jonathan Frankle

Excited to share our work with friends from MIT/Google on Learned Asynchronous Decoding! LLM responses often contain chunks of tokens that are semantically independent. What if we can train LLMs to identify such chunks and decode them in parallel, thereby speeding up inference? 1/N
February 27, 2025 at 12:38 AM
Excited to share our work with friends from MIT/Google on Learned Asynchronous Decoding! LLM responses often contain chunks of tokens that are semantically independent. What if we can train LLMs to identify such chunks and decode them in parallel, thereby speeding up inference? 1/N
Reposted by Jonathan Frankle

We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
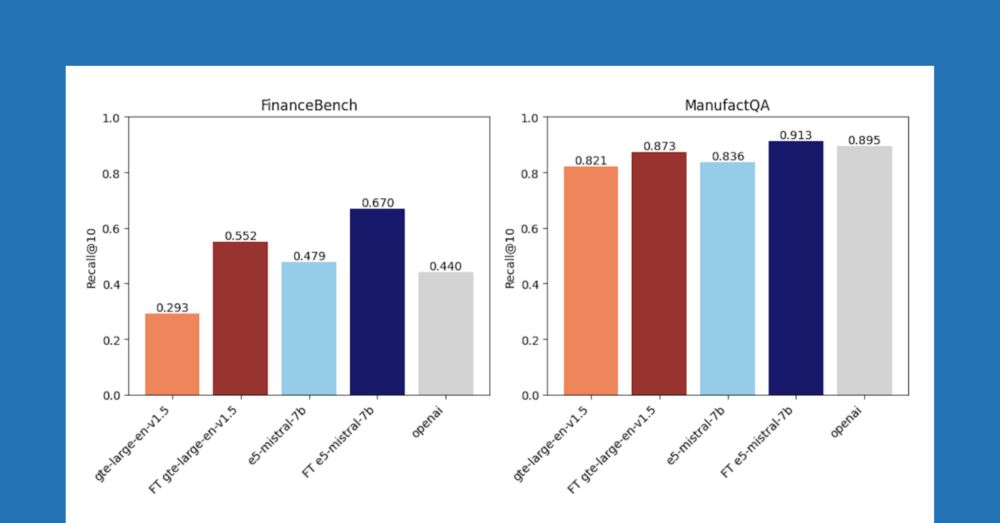
Improving Retrieval and RAG with Embedding Model Finetuning
Fine-tune embedding models on Databricks to enhance retrieval and RAG accuracy with synthetic data—no manual labeling required.
www.databricks.com
February 26, 2025 at 12:48 AM
We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
Reposted by Jonathan Frankle

In case it is not clear from my reposts, the Trump administration is engaged in an illegal AND unconstitutional to seize power over the federal government away from Congress and the courts. "Pausing" payment on the government's bills is just one part of it, but it is among the worst.
January 28, 2025 at 4:55 PM
In case it is not clear from my reposts, the Trump administration is engaged in an illegal AND unconstitutional to seize power over the federal government away from Congress and the courts. "Pausing" payment on the government's bills is just one part of it, but it is among the worst.
All the more convinced that the markets don't understand AI. Both the irrational hype and the irrational pessimism. DeepSeek is incredibly bullish for GPU sales...
January 27, 2025 at 9:20 PM
All the more convinced that the markets don't understand AI. Both the irrational hype and the irrational pessimism. DeepSeek is incredibly bullish for GPU sales...
Very excited that our Series J is complete. Especially thrilled to have our friends at Meta on board!

Meta backs Databricks as the data analytics startup inches toward IPO
Meta rarely invests in startups, but it works with Databricks on the Llama open-source models that Meta trains.
www.cnbc.com
January 22, 2025 at 4:36 PM
Very excited that our Series J is complete. Especially thrilled to have our friends at Meta on board!
Gives a new meaning to "Infrastructure Week"
January 22, 2025 at 2:51 AM
Gives a new meaning to "Infrastructure Week"
Reposted by Jonathan Frankle

Reposted by Jonathan Frankle

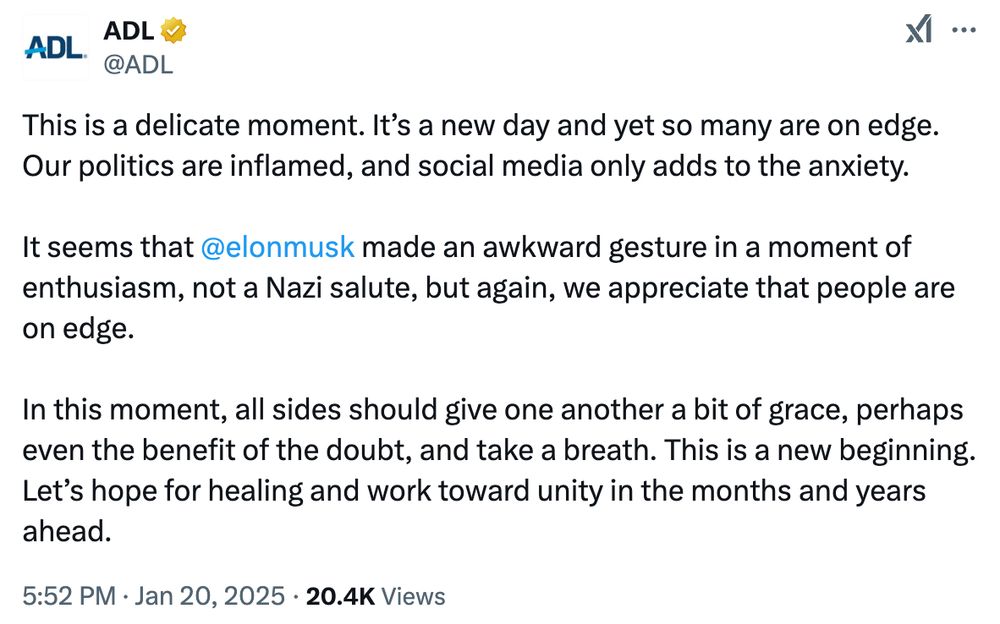
I wasn’t expecting a nazi salute on day 1 but here we are. I of course understand that due to the palm on heart there’s plausible deniability but we all understand the intent
January 20, 2025 at 9:44 PM
I wasn’t expecting a nazi salute on day 1 but here we are. I of course understand that due to the palm on heart there’s plausible deniability but we all understand the intent
Impressed by those able to talk about Deepseek right now.
January 20, 2025 at 9:32 PM
Impressed by those able to talk about Deepseek right now.
Interesting Friday evening code drop from @rajammanabrolu.bsky.social and Brandon Cui at @databricks.bsky.social. That's all I'm allowed to say for now... github.com/databricks/c...

GitHub - databricks/Compose-RL
Contribute to databricks/Compose-RL development by creating an account on GitHub.
github.com
January 18, 2025 at 2:47 AM
Interesting Friday evening code drop from @rajammanabrolu.bsky.social and Brandon Cui at @databricks.bsky.social. That's all I'm allowed to say for now... github.com/databricks/c...
Reposted by Jonathan Frankle


Congestion Pricing Program in New York - MTA
congestionreliefzone.mta.info
January 5, 2025 at 5:01 AM
Reposted by Jonathan Frankle

🧵 Super proud to finally share this work I led last quarter - the
@databricks.bsky.social Domain Intelligence Benchmark Suite (DIBS)! TL;DR: Academic benchmarks ≠ real performance and domain intelligence > general capabilities for enterprise tasks. 1/3
@databricks.bsky.social Domain Intelligence Benchmark Suite (DIBS)! TL;DR: Academic benchmarks ≠ real performance and domain intelligence > general capabilities for enterprise tasks. 1/3
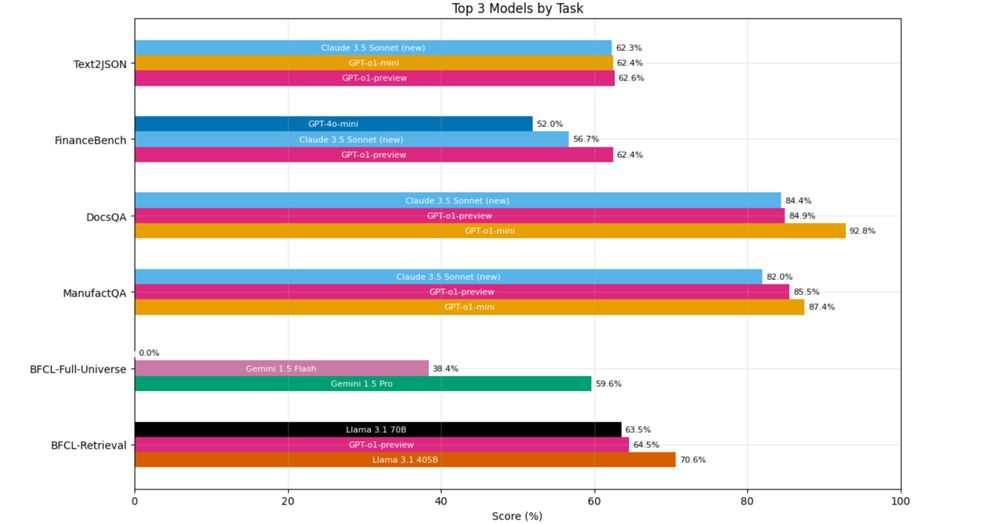
December 19, 2024 at 4:25 PM
🧵 Super proud to finally share this work I led last quarter - the
@databricks.bsky.social Domain Intelligence Benchmark Suite (DIBS)! TL;DR: Academic benchmarks ≠ real performance and domain intelligence > general capabilities for enterprise tasks. 1/3
@databricks.bsky.social Domain Intelligence Benchmark Suite (DIBS)! TL;DR: Academic benchmarks ≠ real performance and domain intelligence > general capabilities for enterprise tasks. 1/3
Reposted by Jonathan Frankle
Databricks raises $10b Series J at $62b valuation, the largest venture round ever.
www.databricks.com/company/news...
www.databricks.com/company/news...

December 17, 2024 at 3:29 PM
Databricks raises $10b Series J at $62b valuation, the largest venture round ever.
www.databricks.com/company/news...
www.databricks.com/company/news...
The world needs data intelligence, and @databricks.bsky.social is delivering. Thank you to the investors who continue to support us on this journey. 🧱🧱🧱 www.databricks.com/company/news...

Databricks is Raising $10B Series J Investment at $62B Valuation
Funding led by new investor Thrive Capital Company expects to cross $3B in revenue run rate and achieve positive free cash flow in fourth quarter
www.databricks.com
December 17, 2024 at 4:15 PM
The world needs data intelligence, and @databricks.bsky.social is delivering. Thank you to the investors who continue to support us on this journey. 🧱🧱🧱 www.databricks.com/company/news...
Reflections on NeurIPS: There's always a big theme people seem to be preoccupied with. This year, it was the continuation of scaling/progress. Will it continue? What will the next generation of models hold? I even got to sass Dylan Patel (not on bsky) over it. Here are my personal thoughts 🧵
December 13, 2024 at 5:32 PM
Reflections on NeurIPS: There's always a big theme people seem to be preoccupied with. This year, it was the continuation of scaling/progress. Will it continue? What will the next generation of models hold? I even got to sass Dylan Patel (not on bsky) over it. Here are my personal thoughts 🧵
Reposted by Jonathan Frankle
We just released the Databricks synthetic evals SDK! 🎉
We’ve found that synthesizing evals is a great way to hill climb your AI system before you’re able to get labels from domain experts.
We’ve also recently release a new diff UI that lets you both qualitatively and quantitatively view results!
We’ve found that synthesizing evals is a great way to hill climb your AI system before you’re able to get labels from domain experts.
We’ve also recently release a new diff UI that lets you both qualitatively and quantitatively view results!
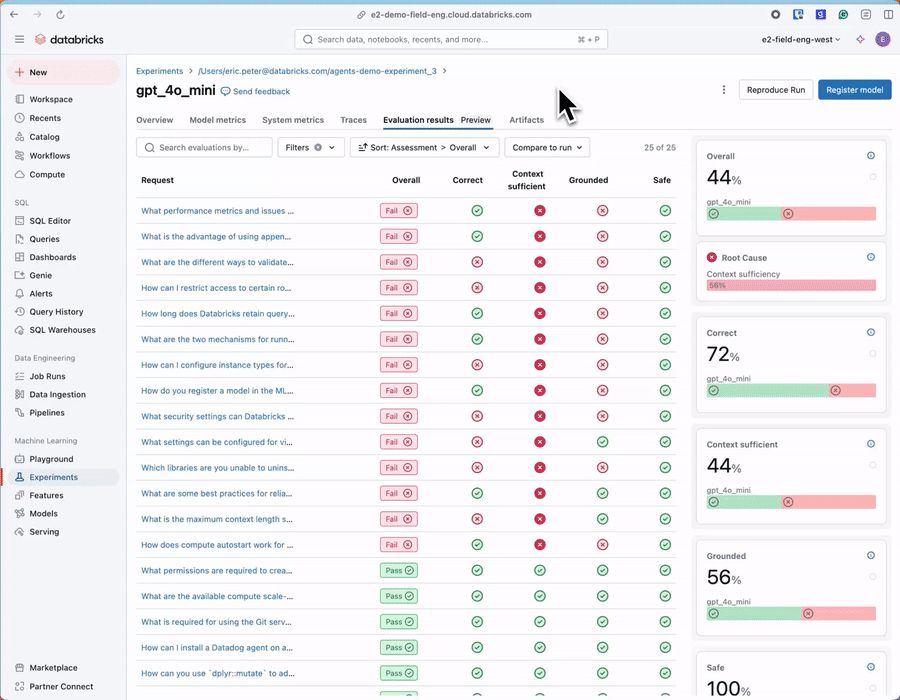
December 11, 2024 at 2:26 PM
We just released the Databricks synthetic evals SDK! 🎉
We’ve found that synthesizing evals is a great way to hill climb your AI system before you’re able to get labels from domain experts.
We’ve also recently release a new diff UI that lets you both qualitatively and quantitatively view results!
We’ve found that synthesizing evals is a great way to hill climb your AI system before you’re able to get labels from domain experts.
We’ve also recently release a new diff UI that lets you both qualitatively and quantitatively view results!
Reposted by Jonathan Frankle

Interested in massively reducing the toil of code maintenance?
Permanence AI is at #NeurIPS2024 this week! Tyler Holloway and Ethan Elenberg will be presenting work at the ML For Systems workshop, and our Founder/CEO Joseph Hackman is attending the conference as well. Let's catch up! #AI #ML
Permanence AI is at #NeurIPS2024 this week! Tyler Holloway and Ethan Elenberg will be presenting work at the ML For Systems workshop, and our Founder/CEO Joseph Hackman is attending the conference as well. Let's catch up! #AI #ML
December 10, 2024 at 4:59 PM
Interested in massively reducing the toil of code maintenance?
Permanence AI is at #NeurIPS2024 this week! Tyler Holloway and Ethan Elenberg will be presenting work at the ML For Systems workshop, and our Founder/CEO Joseph Hackman is attending the conference as well. Let's catch up! #AI #ML
Permanence AI is at #NeurIPS2024 this week! Tyler Holloway and Ethan Elenberg will be presenting work at the ML For Systems workshop, and our Founder/CEO Joseph Hackman is attending the conference as well. Let's catch up! #AI #ML
See you at NeurIPS! I'll be there Tuesday to Friday. Find me at the @databricks.bsky.social booth at the expo.
December 8, 2024 at 9:42 PM
See you at NeurIPS! I'll be there Tuesday to Friday. Find me at the @databricks.bsky.social booth at the expo.
Reposted by Jonathan Frankle

Checking some great work my team did on continued pretraining of LLMs!

What’s the most effective way to add new domain knowledge into an open LLM? A new blog post from my team covers experiments we did at the beginning of the year to start answering this question. It starts, unsurprisingly, with sweeping your learning rate… www.databricks.com/blog/charact...

Characterizing Datasets and Building Better Models with Continued Pre-Training
www.databricks.com
November 26, 2024 at 3:03 AM
Checking some great work my team did on continued pretraining of LLMs!
Reposted by Jonathan Frankle

I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
How to Build Good Language Modeling Benchmarks
Building benchmarks is important because they shine a spotlight on the weaknesses of existing language models and so can guide the community on how to improve them.
ofir.io
November 25, 2024 at 9:54 PM
I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
Reposted by Jonathan Frankle

1/5 Earlier this year, I joined @datologyai.com to give wings to the data research I had been doing in academia. Today, I am absolutely thrilled to share what we’ve been working on!
Techvember Ep 2: How we made the #1 LLM Pre-training Data Recipe.
Blog: 👉 tinyurl.com/best-llm-data 🧵
Techvember Ep 2: How we made the #1 LLM Pre-training Data Recipe.
Blog: 👉 tinyurl.com/best-llm-data 🧵

November 25, 2024 at 6:43 PM
1/5 Earlier this year, I joined @datologyai.com to give wings to the data research I had been doing in academia. Today, I am absolutely thrilled to share what we’ve been working on!
Techvember Ep 2: How we made the #1 LLM Pre-training Data Recipe.
Blog: 👉 tinyurl.com/best-llm-data 🧵
Techvember Ep 2: How we made the #1 LLM Pre-training Data Recipe.
Blog: 👉 tinyurl.com/best-llm-data 🧵