



Ofir Press
@ofirpress.bsky.social
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
https://ofir.io/about
Reposted by Ofir Press

We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
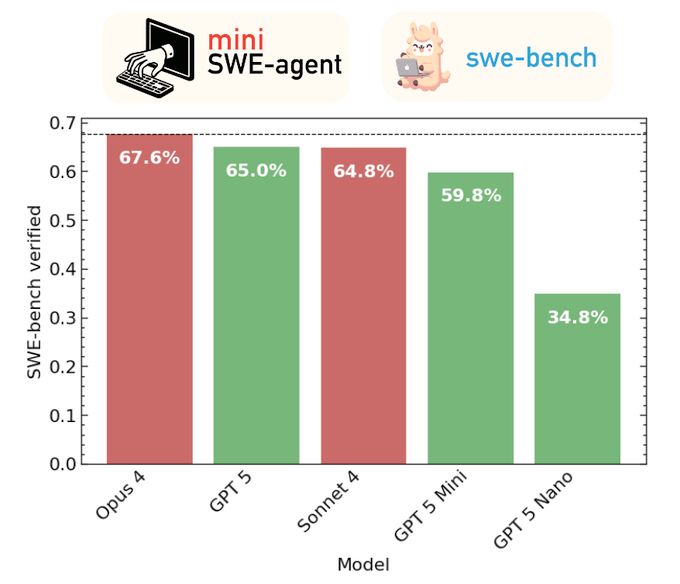
August 8, 2025 at 3:20 PM
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
Do language models have algorithmic creativity?
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io

July 2, 2025 at 2:36 PM
Do language models have algorithmic creativity?
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
I have a post where I talk about how to build good LM benchmarks. I've had to edit the part where I talk about how I think you should try to make your benchmark hard, multiple times now, since LM abilities are accelerating so rapidly.

May 11, 2025 at 9:25 PM
I have a post where I talk about how to build good LM benchmarks. I've had to edit the part where I talk about how I think you should try to make your benchmark hard, multiple times now, since LM abilities are accelerating so rapidly.
Reposted by Ofir Press

Can language model systems autonomously complete entire tasks end-to-end?
In our next Expert Exchange webinar, Ofir Press explores autonomous LM systems for software engineering, featuring SWE-bench & SWE-agent—used by OpenAI, Meta, & more.
🔗 pytorch.org/autonomous-l...
#PyTorch #AI #OpenSource
In our next Expert Exchange webinar, Ofir Press explores autonomous LM systems for software engineering, featuring SWE-bench & SWE-agent—used by OpenAI, Meta, & more.
🔗 pytorch.org/autonomous-l...
#PyTorch #AI #OpenSource

May 5, 2025 at 6:32 PM
Can language model systems autonomously complete entire tasks end-to-end?
In our next Expert Exchange webinar, Ofir Press explores autonomous LM systems for software engineering, featuring SWE-bench & SWE-agent—used by OpenAI, Meta, & more.
🔗 pytorch.org/autonomous-l...
#PyTorch #AI #OpenSource
In our next Expert Exchange webinar, Ofir Press explores autonomous LM systems for software engineering, featuring SWE-bench & SWE-agent—used by OpenAI, Meta, & more.
🔗 pytorch.org/autonomous-l...
#PyTorch #AI #OpenSource
I prompted Claude 3.7 to use Javascript to animate a ride in the Kingda Ka rollercoaster at Six Flags in New Jersey. I did not give it any images/videos from the ride, or any other additional info, and it has no web access.
March 4, 2025 at 3:42 PM
I prompted Claude 3.7 to use Javascript to animate a ride in the Kingda Ka rollercoaster at Six Flags in New Jersey. I did not give it any images/videos from the ride, or any other additional info, and it has no web access.
Reposted by Ofir Press

I spent last week in Valtournenche with @antocuni.bsky.social and Hood Chatham and managed to use SPy to accelerate my #Python code in the browser. It's too early for general adoption, but not too early to get excited!
lukasz.langa.pl/f37aa97a-9ea...
lukasz.langa.pl/f37aa97a-9ea...

A peek into a possible future of Python in the browser - Łukasz Langa
My Python code was too slow, so I made it faster with Python. For some definition of “Python”.
lukasz.langa.pl
February 24, 2025 at 7:10 PM
I spent last week in Valtournenche with @antocuni.bsky.social and Hood Chatham and managed to use SPy to accelerate my #Python code in the browser. It's too early for general adoption, but not too early to get excited!
lukasz.langa.pl/f37aa97a-9ea...
lukasz.langa.pl/f37aa97a-9ea...
SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.
github.com/swe-agent/sw...
github.com/swe-agent/sw...

February 13, 2025 at 3:37 PM
SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.
github.com/swe-agent/sw...
github.com/swe-agent/sw...
Reposted by Ofir Press

Hi, the Microsoft Translator research team is looking for an intern for the summer. If you a PhD student in Machine Translation, Natural Language Processing, or related, check it out: aka.ms/mtintern
Search Jobs | Microsoft Careers
aka.ms
January 28, 2025 at 5:55 PM
Hi, the Microsoft Translator research team is looking for an intern for the summer. If you a PhD student in Machine Translation, Natural Language Processing, or related, check it out: aka.ms/mtintern
SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/

January 17, 2025 at 9:06 AM
SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
Reposted by Ofir Press

SWE-Bench has been one of the most important tasks measuring the progress of agents tackling software engineering in 2024. I caught up with two of its creators, @ofirpress.bsky.social and Carlos E. Jimenez to share their ideas on the state of LLM-backed agents.
www.youtube.com/watch?v=bivZ...
www.youtube.com/watch?v=bivZ...

SWE-Bench authors reflect on the state of LLM agents at Neurips 2024
YouTube video by Jay Alammar
www.youtube.com
January 13, 2025 at 2:29 PM
SWE-Bench has been one of the most important tasks measuring the progress of agents tackling software engineering in 2024. I caught up with two of its creators, @ofirpress.bsky.social and Carlos E. Jimenez to share their ideas on the state of LLM-backed agents.
www.youtube.com/watch?v=bivZ...
www.youtube.com/watch?v=bivZ...
We just updated the SWE-bench leaderboard with *14* new submissions! Congrats to blackbox.ai & aide.dev on setting new SoTA scores on Lite & Verified!
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
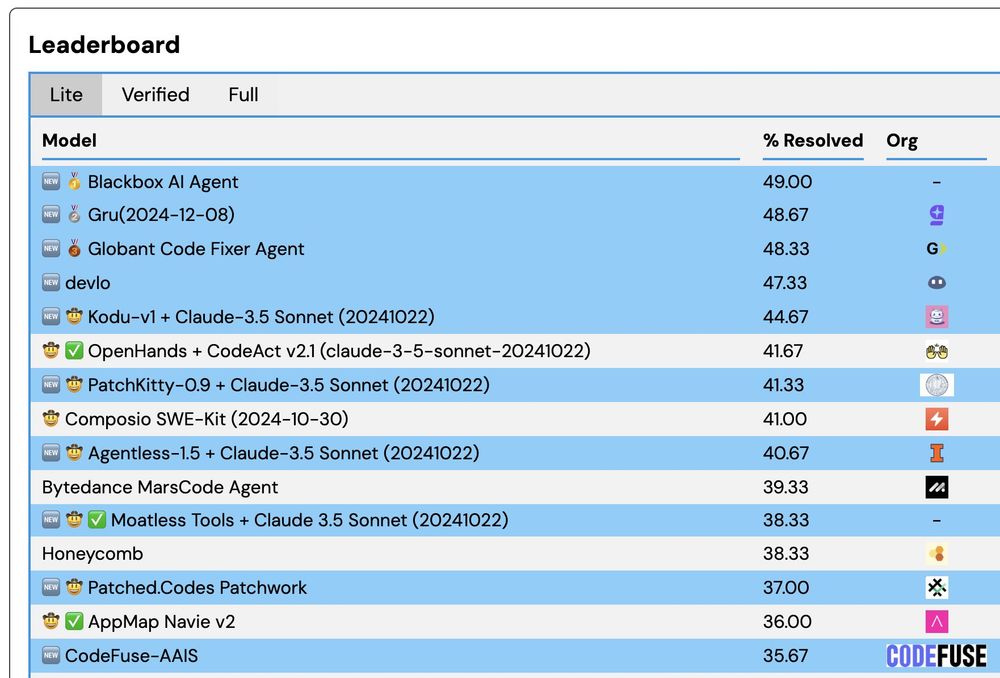
January 8, 2025 at 8:31 PM
We just updated the SWE-bench leaderboard with *14* new submissions! Congrats to blackbox.ai & aide.dev on setting new SoTA scores on Lite & Verified!
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
When we started working on SWE-agent the top score on SWE-bench was 2%. I told the team that if we got 6%, we'd have a good paper, and I'd buy everyone gelato.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.

January 2, 2025 at 10:05 AM
When we started working on SWE-agent the top score on SWE-bench was 2%. I told the team that if we got 6%, we'd have a good paper, and I'd buy everyone gelato.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.

Until recently, we didn't have models that were *trained* for tough multi-turn tasks like SWE-bench.
My hypothesis: now, with the new Gemini and O3, we're finally seeing how much accuracy can improve when models are trained for these tasks.
This is just the beginning!
My hypothesis: now, with the new Gemini and O3, we're finally seeing how much accuracy can improve when models are trained for these tasks.
This is just the beginning!
December 20, 2024 at 9:10 PM
Until recently, we didn't have models that were *trained* for tough multi-turn tasks like SWE-bench.
My hypothesis: now, with the new Gemini and O3, we're finally seeing how much accuracy can improve when models are trained for these tasks.
This is just the beginning!
My hypothesis: now, with the new Gemini and O3, we're finally seeing how much accuracy can improve when models are trained for these tasks.
This is just the beginning!

When ChatGPT came out, and for a year afterwards, it seemed like OpenAI had a huge moat that was insurmountable.
Now Anthropic is matching their performance, Google and Meta are close, and it seems like the academic/open source community understands how to build these models ->
Now Anthropic is matching their performance, Google and Meta are close, and it seems like the academic/open source community understands how to build these models ->
December 18, 2024 at 8:10 PM
When ChatGPT came out, and for a year afterwards, it seemed like OpenAI had a huge moat that was insurmountable.
Now Anthropic is matching their performance, Google and Meta are close, and it seems like the academic/open source community understands how to build these models ->
Now Anthropic is matching their performance, Google and Meta are close, and it seems like the academic/open source community understands how to build these models ->
Reposted by Ofir Press

The team behind the Chatbot Arena LLM leaderboard just released a new variant: web.lmarena.ai
This one tests models on their React, TypeScript and Tailwind abilities. My notes (including a leaked copy of the system prompt) here: simonwillison.net/2024/Dec/16/...
This one tests models on their React, TypeScript and Tailwind abilities. My notes (including a leaked copy of the system prompt) here: simonwillison.net/2024/Dec/16/...

WebDev Arena
New leaderboard from the [Chatbot Arena](https://lmarena.ai/) team (formerly known as LMSYS), this time focused on evaluating how good different models are at "web development" - though it turns out t...
simonwillison.net
December 16, 2024 at 6:40 PM
The team behind the Chatbot Arena LLM leaderboard just released a new variant: web.lmarena.ai
This one tests models on their React, TypeScript and Tailwind abilities. My notes (including a leaked copy of the system prompt) here: simonwillison.net/2024/Dec/16/...
This one tests models on their React, TypeScript and Tailwind abilities. My notes (including a leaked copy of the system prompt) here: simonwillison.net/2024/Dec/16/...
We're presenting SWE-agent tomorrow (Wed) at the 11AM poster session, East Exhibit Hall A-C #1000.
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)

December 10, 2024 at 6:16 PM
We're presenting SWE-agent tomorrow (Wed) at the 11AM poster session, East Exhibit Hall A-C #1000.
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
We chatted with Matthew Berman about the origins of SWE-bench / SWE-agent and how we're thinking about the current agent landscape. www.youtube.com/watch?v=fcr8...

SWE-Agent Team Interview - Agents, Programming, and Benchmarks!
YouTube video by Matthew Berman
www.youtube.com
December 7, 2024 at 7:50 PM
We chatted with Matthew Berman about the origins of SWE-bench / SWE-agent and how we're thinking about the current agent landscape. www.youtube.com/watch?v=fcr8...
Reposted by Ofir Press

EnIGMA sets new state-of-the-art results on @stanfordnlp.bsky.social's CyBench, which tasks LMs to find security vulnerabilities.
Such Capture The Flag tasks make for challenging benchmarks—demanding high-level reasoning, persistence and adaptability. Even expert humans find them hard!
Such Capture The Flag tasks make for challenging benchmarks—demanding high-level reasoning, persistence and adaptability. Even expert humans find them hard!

December 5, 2024 at 5:45 PM
EnIGMA sets new state-of-the-art results on @stanfordnlp.bsky.social's CyBench, which tasks LMs to find security vulnerabilities.
Such Capture The Flag tasks make for challenging benchmarks—demanding high-level reasoning, persistence and adaptability. Even expert humans find them hard!
Such Capture The Flag tasks make for challenging benchmarks—demanding high-level reasoning, persistence and adaptability. Even expert humans find them hard!
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!

December 4, 2024 at 4:52 PM
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
Super cool work from Daniel Geng: "What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
December 4, 2024 at 3:58 AM
Super cool work from Daniel Geng: "What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Cool benchmark I found through Twitter. (I am not involved in this work) scalingintelligence.stanford.edu/blogs/kernel...
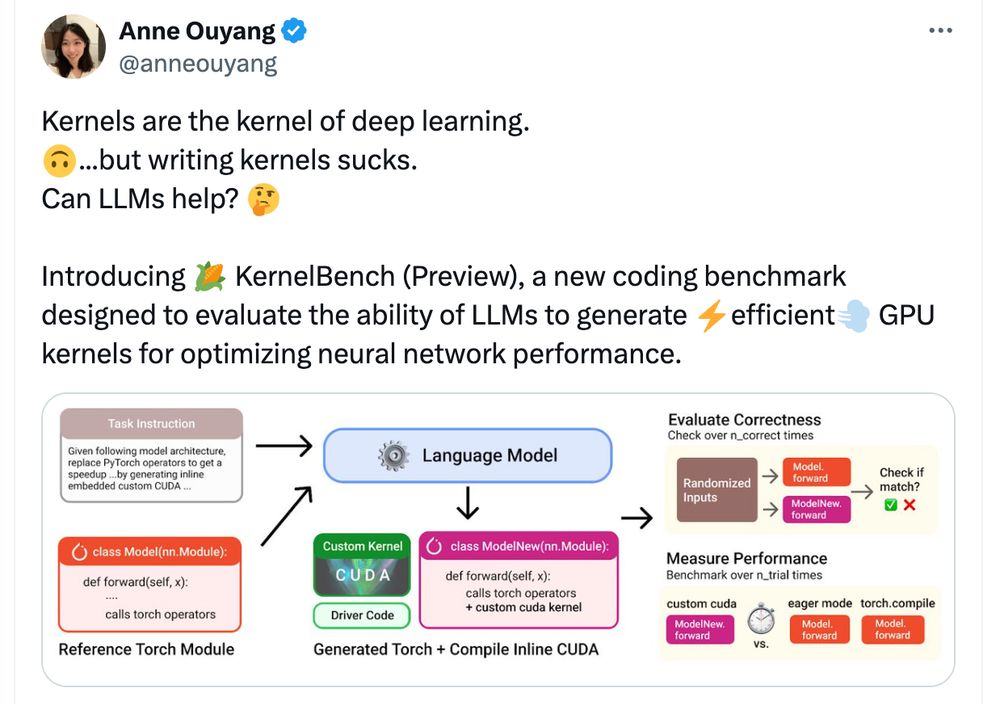
December 3, 2024 at 11:17 PM
Cool benchmark I found through Twitter. (I am not involved in this work) scalingintelligence.stanford.edu/blogs/kernel...
Lots of new SWEbench.com results have just been posted. Congrats everyone on the amazing results!

December 3, 2024 at 10:08 PM
Lots of new SWEbench.com results have just been posted. Congrats everyone on the amazing results!
The Amazon thing that summarizes all of the reviews into both a sentence and a bullet point list is so awesome and I wish I could figure out a way to make a benchmark out of it :)

December 1, 2024 at 5:18 AM
The Amazon thing that summarizes all of the reviews into both a sentence and a bullet point list is so awesome and I wish I could figure out a way to make a benchmark out of it :)