



Ofir Press
@ofirpress.bsky.social
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
https://ofir.io/about
Do language models have algorithmic creativity?
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io

July 2, 2025 at 2:36 PM
Do language models have algorithmic creativity?
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!
algotune.io
I have a post where I talk about how to build good LM benchmarks. I've had to edit the part where I talk about how I think you should try to make your benchmark hard, multiple times now, since LM abilities are accelerating so rapidly.

May 11, 2025 at 9:25 PM
I have a post where I talk about how to build good LM benchmarks. I've had to edit the part where I talk about how I think you should try to make your benchmark hard, multiple times now, since LM abilities are accelerating so rapidly.
I prompted Claude 3.7 to use Javascript to animate a ride in the Kingda Ka rollercoaster at Six Flags in New Jersey. I did not give it any images/videos from the ride, or any other additional info, and it has no web access.
March 4, 2025 at 3:42 PM
I prompted Claude 3.7 to use Javascript to animate a ride in the Kingda Ka rollercoaster at Six Flags in New Jersey. I did not give it any images/videos from the ride, or any other additional info, and it has no web access.
SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.
github.com/swe-agent/sw...
github.com/swe-agent/sw...

February 13, 2025 at 3:37 PM
SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.
github.com/swe-agent/sw...
github.com/swe-agent/sw...
SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/

January 17, 2025 at 9:06 AM
SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
We just updated the SWE-bench leaderboard with *14* new submissions! Congrats to blackbox.ai & aide.dev on setting new SoTA scores on Lite & Verified!
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
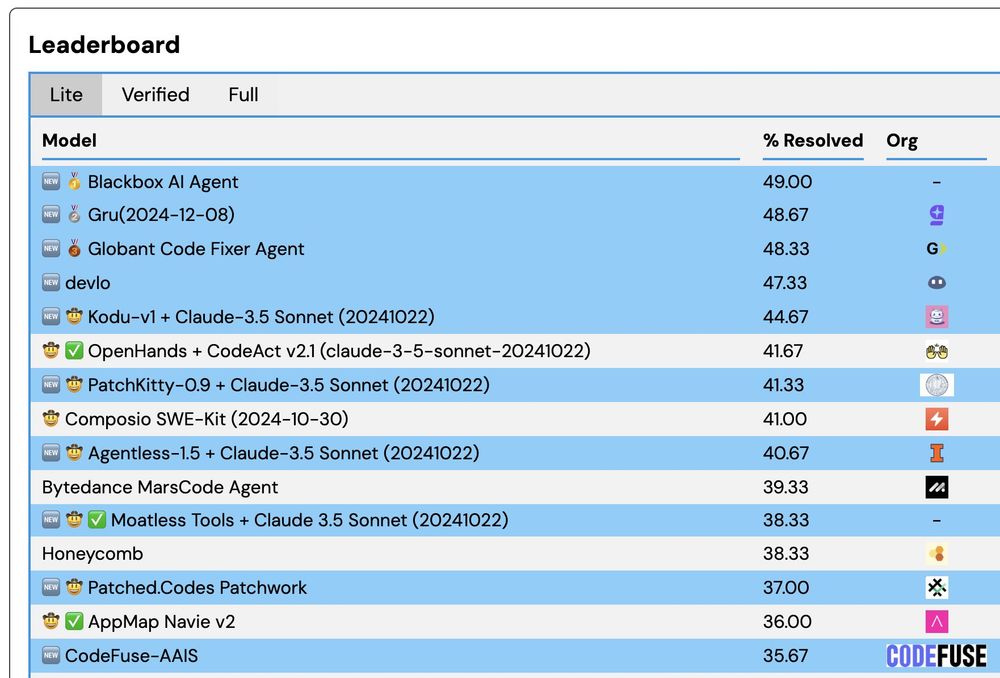
January 8, 2025 at 8:31 PM
We just updated the SWE-bench leaderboard with *14* new submissions! Congrats to blackbox.ai & aide.dev on setting new SoTA scores on Lite & Verified!
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
Congrats to Google on your first submission!
Credit to John Yang, Carlos E. Jimeneze & Kilian Lieret who maintain SWE-bench/SWE-agent
When we started working on SWE-agent the top score on SWE-bench was 2%. I told the team that if we got 6%, we'd have a good paper, and I'd buy everyone gelato.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.

January 2, 2025 at 10:05 AM
When we started working on SWE-agent the top score on SWE-bench was 2%. I told the team that if we got 6%, we'd have a good paper, and I'd buy everyone gelato.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
I thought 6% was very ambitious but doable.
We ended up getting 12% 🤯 so I cooked dinner for everyone.
We're presenting SWE-agent tomorrow (Wed) at the 11AM poster session, East Exhibit Hall A-C #1000.
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)

December 10, 2024 at 6:16 PM
We're presenting SWE-agent tomorrow (Wed) at the 11AM poster session, East Exhibit Hall A-C #1000.
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
We're going to talk about a lot of upcoming SWE-agent features. Join @jyangballin @_carlosejimenez @KLieret and me. I also have a bunch of SWE-agent stickers to hand out :)
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!

December 4, 2024 at 4:52 PM
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
Super cool work from Daniel Geng: "What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
December 4, 2024 at 3:58 AM
Super cool work from Daniel Geng: "What happens when you train a video generation model to be conditioned on motion?
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Turns out you can perform "motion prompting," just like you might prompt an LLM! Doing so enables many different capabilities."
motion-prompting.github.io
Cool benchmark I found through Twitter. (I am not involved in this work) scalingintelligence.stanford.edu/blogs/kernel...
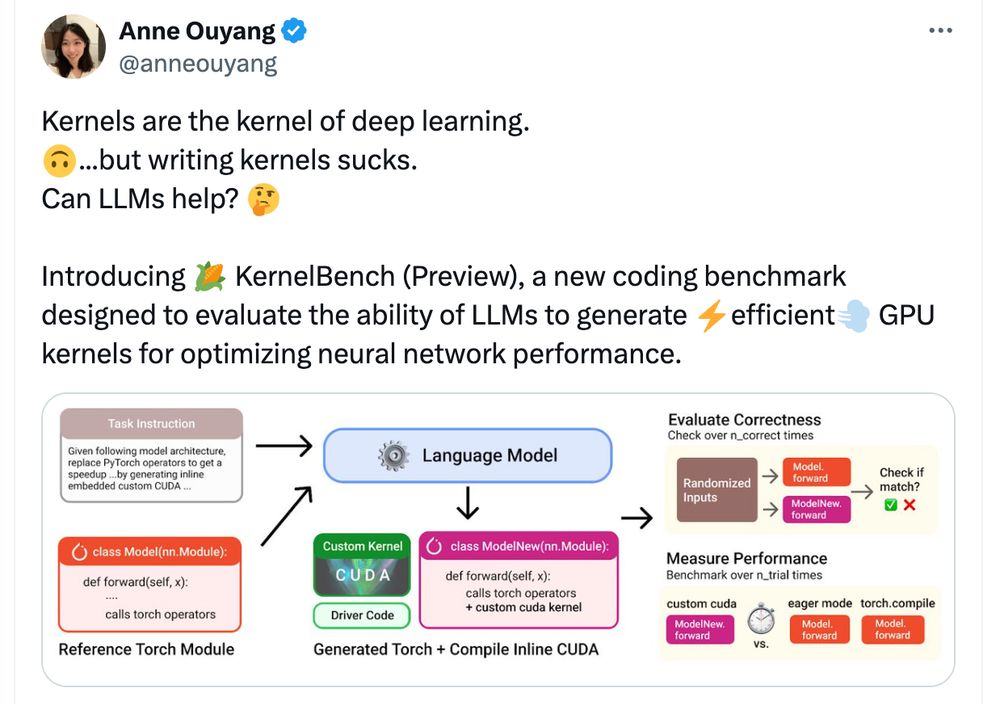
December 3, 2024 at 11:17 PM
Cool benchmark I found through Twitter. (I am not involved in this work) scalingintelligence.stanford.edu/blogs/kernel...
Lots of new SWEbench.com results have just been posted. Congrats everyone on the amazing results!

December 3, 2024 at 10:08 PM
Lots of new SWEbench.com results have just been posted. Congrats everyone on the amazing results!
The Amazon thing that summarizes all of the reviews into both a sentence and a bullet point list is so awesome and I wish I could figure out a way to make a benchmark out of it :)

December 1, 2024 at 5:18 AM
The Amazon thing that summarizes all of the reviews into both a sentence and a bullet point list is so awesome and I wish I could figure out a way to make a benchmark out of it :)
Quantized SWE-bench coming soon?

November 28, 2024 at 8:04 PM
Quantized SWE-bench coming soon?