



Emma Roscow
@emmaroscow.bsky.social
Machine learning @ EcoVadis | ex-neuroscience-postdoc who still dabbles
Pinned
Emma Roscow
@emmaroscow.bsky.social
· Nov 29

Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals
Nature Communications - It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the...
rdcu.be
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Reposted by Emma Roscow

Andrej Karpathy is worried about keeping up with software engineering practices

December 27, 2025 at 9:40 AM
Andrej Karpathy is worried about keeping up with software engineering practices
Reposted by Emma Roscow

Where is the story in a book?

Where are thoughts in the brain? Are they in the brain?
December 21, 2025 at 10:32 AM
Where is the story in a book?
Reposted by Emma Roscow

Seven feel-good science stories to round up 2025. All too often we forget to celebrate the positives
🧪
#AcademicSky
www.nature.com/articles/d41...
🧪
#AcademicSky
www.nature.com/articles/d41...

Seven feel-good science stories to restore your faith in 2025
Immense progress in gene-editing, drug discovery and conservation are just some of the reasons to be cheerful about 2025.
www.nature.com
December 18, 2025 at 8:15 AM
Seven feel-good science stories to round up 2025. All too often we forget to celebrate the positives
🧪
#AcademicSky
www.nature.com/articles/d41...
🧪
#AcademicSky
www.nature.com/articles/d41...
Reposted by Emma Roscow

Ok, this is nuts. Once you see it you cannot unsee it. Do you see it?
(OP @drgbuckingham.bsky.social )
(OP @drgbuckingham.bsky.social )

December 16, 2025 at 7:39 PM
Ok, this is nuts. Once you see it you cannot unsee it. Do you see it?
(OP @drgbuckingham.bsky.social )
(OP @drgbuckingham.bsky.social )
Reposted by Emma Roscow

I’ve been hearing two things:
- People are happy they can ask questions quickly without judgment or looking for the Right Person to ask in the office.
- People are unhappy that nobody asksthem questions, because that is how they get to know colleagues and win their trust.
- People are happy they can ask questions quickly without judgment or looking for the Right Person to ask in the office.
- People are unhappy that nobody asksthem questions, because that is how they get to know colleagues and win their trust.

In the AI social sphere:
- Developers like Claude Code + Claude Opus 4.5.
- People appreciate that AI does not judge. Unlike coworkers, who may silently label you as incompetent if you ask one too many “stupid” questions, AI will answer every question - including the ones you are hesitate to ask.
- Developers like Claude Code + Claude Opus 4.5.
- People appreciate that AI does not judge. Unlike coworkers, who may silently label you as incompetent if you ask one too many “stupid” questions, AI will answer every question - including the ones you are hesitate to ask.
December 15, 2025 at 3:18 PM
I’ve been hearing two things:
- People are happy they can ask questions quickly without judgment or looking for the Right Person to ask in the office.
- People are unhappy that nobody asksthem questions, because that is how they get to know colleagues and win their trust.
- People are happy they can ask questions quickly without judgment or looking for the Right Person to ask in the office.
- People are unhappy that nobody asksthem questions, because that is how they get to know colleagues and win their trust.
Reposted by Emma Roscow

This is pretty cool! 👍
google-deepmind.github.io/disco_rl/
google-deepmind.github.io/disco_rl/
Discovering State-of-the-art Reinforcement Learning Algorithms
We show that it is possible to automatically discover a state-of-the-art reinforcement learning (RL) algorithm that outperforms manually-designed ones across a variety of challenging benchmarks.
google-deepmind.github.io
December 15, 2025 at 3:19 PM
This is pretty cool! 👍
google-deepmind.github.io/disco_rl/
google-deepmind.github.io/disco_rl/
Reposted by Emma Roscow

Completely agree. And if I can make a self-promoting plug here, we have a nice table in this paper trying to separate some of these ideas out. The brain is very information-efficient (bits/ATP), while still being very expensive in energy consumption (ATP/sec).
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...

December 8, 2025 at 2:23 PM
Completely agree. And if I can make a self-promoting plug here, we have a nice table in this paper trying to separate some of these ideas out. The brain is very information-efficient (bits/ATP), while still being very expensive in energy consumption (ATP/sec).
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...
Reposted by Emma Roscow

Soapbox time: the problem with metabolic efficiency arguments in neuroscience is that they often confuse energy efficiency with energy expenditure. Biological systems are optimized for energy efficiency, but that does NOT imply they are optimized for low energy expenditure 🧵 1/

December 8, 2025 at 1:31 PM
Soapbox time: the problem with metabolic efficiency arguments in neuroscience is that they often confuse energy efficiency with energy expenditure. Biological systems are optimized for energy efficiency, but that does NOT imply they are optimized for low energy expenditure 🧵 1/
Reposted by Emma Roscow

Joint modelling of brain and behaviour dynamics with artificial intelligence
www.nature.com/articles/s41...
www.nature.com/articles/s41...

Joint modelling of brain and behaviour dynamics with artificial intelligence - Nature Reviews Neuroscience
Artificial intelligence is rapidly advancing our mechanistic understanding of the shared structure between the brain and higher-order behaviours. In this Review, Mathis and Mathis synthesize state-of-...
www.nature.com
December 3, 2025 at 4:59 PM
Joint modelling of brain and behaviour dynamics with artificial intelligence
www.nature.com/articles/s41...
www.nature.com/articles/s41...
Reposted by Emma Roscow

As a Doctor Who fan, I had to read and then re-read this.
I am a comma stan.
I am a comma stan.

December 3, 2025 at 9:04 PM
As a Doctor Who fan, I had to read and then re-read this.
I am a comma stan.
I am a comma stan.
Reposted by Emma Roscow

More press on our recent Behavioral and Brain Sciences article:
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...

Thinking Takes Energy
A new study shows how our brain metabolism sets the limits of thinking. Researchers explain why cognitive models remain incomplete without considering biological resources.
aktuell.uni-bielefeld.de
December 1, 2025 at 11:33 PM
More press on our recent Behavioral and Brain Sciences article:
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
Reposted by Emma Roscow

A neat perspective on what makes RL for LLMs tractable

I'd say that's because it's not sparse reward in a meaningful way, in the same way Go in self-play is not sparse in a meaningful way.
That is, in Go, your reward is 0 for most time steps and only +1/-1 at end. That sound's sparse, but not from an algorithmic perspective.
That is, in Go, your reward is 0 for most time steps and only +1/-1 at end. That sound's sparse, but not from an algorithmic perspective.
December 1, 2025 at 12:52 PM
A neat perspective on what makes RL for LLMs tractable
Reposted by Emma Roscow

1/3 How reward prediction errors shape memory: when people gamble and cues signal unexpectedly high reward probability, those incidental images are remembered better than ones on safe trials, linking RL computations to episodic encoding. #RewardSignals #neuroskyence www.nature.com/articles/s41...

Positive reward prediction errors during decision-making strengthen memory encoding - Nature Human Behaviour
Jang and colleagues show that positive reward prediction errors elicited during incidental encoding enhance the formation of episodic memories.
www.nature.com
November 30, 2025 at 11:12 AM
1/3 How reward prediction errors shape memory: when people gamble and cues signal unexpectedly high reward probability, those incidental images are remembered better than ones on safe trials, linking RL computations to episodic encoding. #RewardSignals #neuroskyence www.nature.com/articles/s41...
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals
Nature Communications - It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the...
rdcu.be
November 29, 2025 at 6:32 PM
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Reposted by Emma Roscow

Terrific work led by @emmaroscow.bsky.social showing that hippocampal replay reflects events with large prediction errors, all the better to bootstrap learning as we slumber
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals - Nature Communications
It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the authors show that reward-prediction sig...
www.nature.com
November 27, 2025 at 10:24 AM
Terrific work led by @emmaroscow.bsky.social showing that hippocampal replay reflects events with large prediction errors, all the better to bootstrap learning as we slumber
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Reposted by Emma Roscow

How does a neuron get its activity? 👀
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
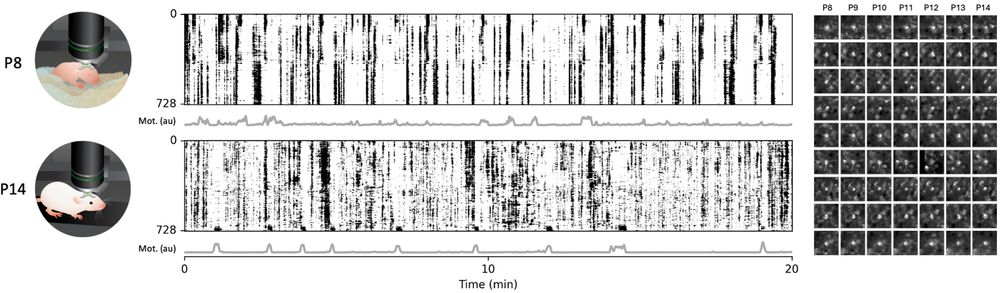
March 3, 2025 at 11:23 AM
How does a neuron get its activity? 👀
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Reposted by Emma Roscow

REM sleep and nightmares as transdiagnostic features of psychiatric disorders:
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...

Systematic review: REM sleep, dysphoric dreams and nightmares as transdiagnostic features of psychiatric disorders with emotion dysregulation - Clinical implications
Fragmented rapid eye movement (REM) sleep disrupts the overnight resolution of emotional distress, a process crucial for emotion regulation. Emotion d…
www.sciencedirect.com
February 16, 2025 at 8:18 AM
REM sleep and nightmares as transdiagnostic features of psychiatric disorders:
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...