



Anirudh GJ
@anirudhgj.bsky.social
NeuroAI PhD student @ Mila & Universite de Montreal w/ Prof. Matthew Perich.
Studying continual learning and adaptation in Brain and ANNs.
Studying continual learning and adaptation in Brain and ANNs.
Reposted by Anirudh GJ

Now in PRX: Theory linking connectivity structure to collective activity in nonlinear RNNs!
For neuro fans: conn. structure can be invisible in single neurons but shape pop. activity
For low-rank RNN fans: a theory of rank=O(N)
For physics fans: fluctuations around DMFT saddle⇒dimension of activity
For neuro fans: conn. structure can be invisible in single neurons but shape pop. activity
For low-rank RNN fans: a theory of rank=O(N)
For physics fans: fluctuations around DMFT saddle⇒dimension of activity

Connectivity Structure and Dynamics of Nonlinear Recurrent Neural Networks
The structure of brain connectivity predicts collective neural activity, with a small number of connectivity features determining activity dimensionality, linking circuit architecture to network-level...
journals.aps.org
November 3, 2025 at 9:47 PM
Now in PRX: Theory linking connectivity structure to collective activity in nonlinear RNNs!
For neuro fans: conn. structure can be invisible in single neurons but shape pop. activity
For low-rank RNN fans: a theory of rank=O(N)
For physics fans: fluctuations around DMFT saddle⇒dimension of activity
For neuro fans: conn. structure can be invisible in single neurons but shape pop. activity
For low-rank RNN fans: a theory of rank=O(N)
For physics fans: fluctuations around DMFT saddle⇒dimension of activity
Reposted by Anirudh GJ

What if we did a single run and declared victory

October 23, 2025 at 2:28 AM
What if we did a single run and declared victory
Reposted by Anirudh GJ

Very excited to release a new blog post that formalizes what it means for data to be compositional, and shows how compositionality can exist at multiple scales. Early days, but I think there may be significant implications for AI. Check it out! ericelmoznino.github.io/blog/2025/08...
Defining and quantifying compositional structure
What is compositionality? For those of us working in AI or cognitive neuroscience this question can appear easy at first, but becomes increasingly perplexing the more we think about it. We aren’t shor...
ericelmoznino.github.io
August 18, 2025 at 8:46 PM
Very excited to release a new blog post that formalizes what it means for data to be compositional, and shows how compositionality can exist at multiple scales. Early days, but I think there may be significant implications for AI. Check it out! ericelmoznino.github.io/blog/2025/08...
Reposted by Anirudh GJ

📰 I really enjoyed writing this article with @thetransmitter.bsky.social! In it, I summarize parts of our recent perspective article on neural manifolds (www.nature.com/articles/s41...), with a focus on highlighting just a few cool insights into the brain we've already seen at the population level.

Neural manifold properties can help us understand how animal brains deal with competing and multifaceted information, execute flexible behaviors and reuse common computations, writes @mattperich.bsky.social.
#neuroskyence
www.thetransmitter.org/neural-dynam...
#neuroskyence
www.thetransmitter.org/neural-dynam...
Neural population-based approaches have opened new windows into neural computations and behavior
Neural manifold properties can help us understand how animal brains deal with complex information, execute flexible behaviors and reuse common computations.
www.thetransmitter.org
August 4, 2025 at 6:45 PM
📰 I really enjoyed writing this article with @thetransmitter.bsky.social! In it, I summarize parts of our recent perspective article on neural manifolds (www.nature.com/articles/s41...), with a focus on highlighting just a few cool insights into the brain we've already seen at the population level.
Reposted by Anirudh GJ

Is it possible to go from spikes to rates without averaging?
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.

From Spikes To Rates
YouTube video by Gerstner Lab
youtu.be
August 8, 2025 at 3:25 PM
Is it possible to go from spikes to rates without averaging?
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
We show how to exactly map recurrent spiking networks into recurrent rate networks, with the same number of neurons. No temporal or spatial averaging needed!
Presented at Gatsby Neural Dynamics Workshop, London.
Reposted by Anirudh GJ

I wonder, where would be a good place to do modeling and chat with many people that study different species or do comparative studies? (asking for a friend)
To identify fundamental neuroscientific principles that generalize across species, systems and circuits, neuroscientists must embrace an evolutionary perspective, argue Karl Farrow and @katjareinhard.bsky.social.
#neuroskyence
www.thetransmitter.org/systems-neur...
#neuroskyence
www.thetransmitter.org/systems-neur...

Systems and circuit neuroscience need an evolutionary perspective
To identify fundamental neuroscientific principles that generalize across species, neuroscientists must frame their research through an evolutionary lens.
www.thetransmitter.org
July 16, 2025 at 10:13 PM
I wonder, where would be a good place to do modeling and chat with many people that study different species or do comparative studies? (asking for a friend)
Reposted by Anirudh GJ

Mice learn these tasks and are robust to perturbations like fog. Now, we invite you all to make AI agents to beat mice.
We present our #NeurIPS competition. You can learn about it here: robustforaging.github.io (7/n)
We present our #NeurIPS competition. You can learn about it here: robustforaging.github.io (7/n)
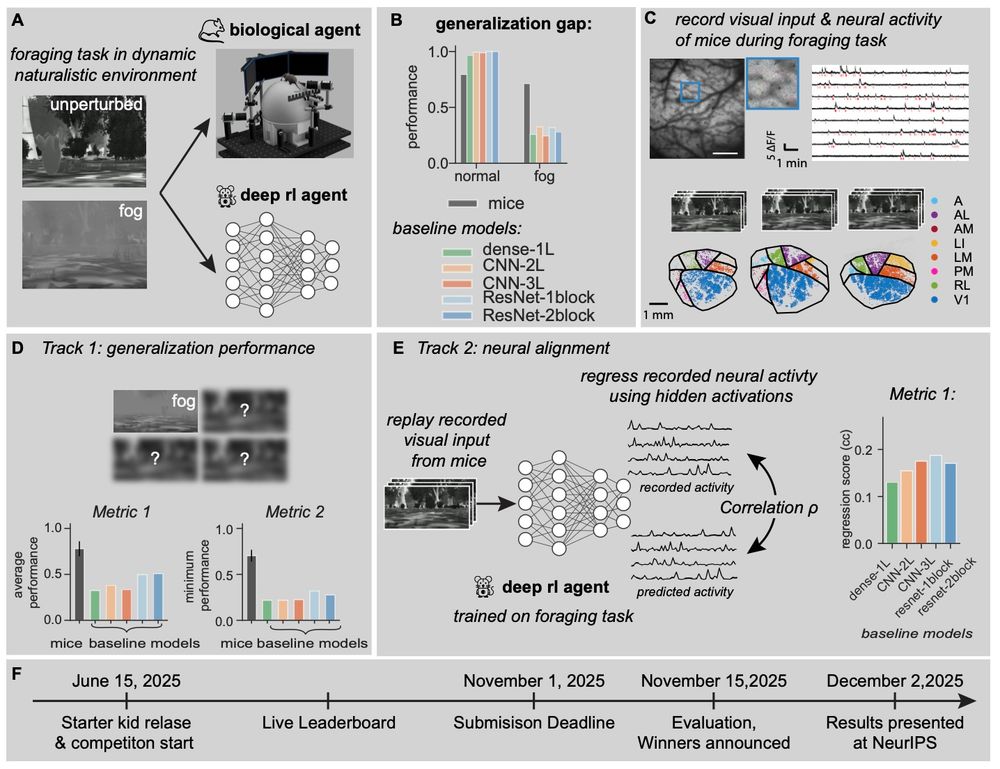
July 10, 2025 at 12:22 PM
Mice learn these tasks and are robust to perturbations like fog. Now, we invite you all to make AI agents to beat mice.
We present our #NeurIPS competition. You can learn about it here: robustforaging.github.io (7/n)
We present our #NeurIPS competition. You can learn about it here: robustforaging.github.io (7/n)
Reposted by Anirudh GJ

This paper carefully examines how well simple units capture neural data.
To quote someone from my lab (they can take credit if they want):
Def not news to those of us who use [ANN] models, but a good counter argument to the "but neurons are more complicated" crowd.
arxiv.org/abs/2504.08637
🧠📈 🧪
To quote someone from my lab (they can take credit if they want):
Def not news to those of us who use [ANN] models, but a good counter argument to the "but neurons are more complicated" crowd.
arxiv.org/abs/2504.08637
🧠📈 🧪

Simple low-dimensional computations explain variability in neuronal activity
Our understanding of neural computation is founded on the assumption that neurons fire in response to a linear summation of inputs. Yet experiments demonstrate that some neurons are capable of complex...
arxiv.org
June 25, 2025 at 3:49 PM
This paper carefully examines how well simple units capture neural data.
To quote someone from my lab (they can take credit if they want):
Def not news to those of us who use [ANN] models, but a good counter argument to the "but neurons are more complicated" crowd.
arxiv.org/abs/2504.08637
🧠📈 🧪
To quote someone from my lab (they can take credit if they want):
Def not news to those of us who use [ANN] models, but a good counter argument to the "but neurons are more complicated" crowd.
arxiv.org/abs/2504.08637
🧠📈 🧪
Reposted by Anirudh GJ

"These findings validate core predictions of Spatial Computing by showing that oscillatory dynamics not only gate information in time but also shape where in the cortex cognitive content is represented."
More on Spatial Computing:
doi.org/10.1038/s414...
More on Spatial Computing:
doi.org/10.1038/s414...

Working memory control dynamics follow principles of spatial computing - Nature Communications
It is unclear how cognitive computations are performed on sensory information. Here, neural evidence from working memory tasks suggests that the physical dimensions of cortical networks are used to up...
doi.org
June 25, 2025 at 5:40 PM
"These findings validate core predictions of Spatial Computing by showing that oscillatory dynamics not only gate information in time but also shape where in the cortex cognitive content is represented."
More on Spatial Computing:
doi.org/10.1038/s414...
More on Spatial Computing:
doi.org/10.1038/s414...
Reposted by Anirudh GJ
(1/23) In addition to the new Lady Gaga album "Mayhem," my paper with Manuel Beiran, "Structure of activity in multiregion recurrent neural networks," has been published today.
PNAS link: www.pnas.org/doi/10.1073/...
(see dclark.io for PDF)
An explainer thread...
PNAS link: www.pnas.org/doi/10.1073/...
(see dclark.io for PDF)
An explainer thread...
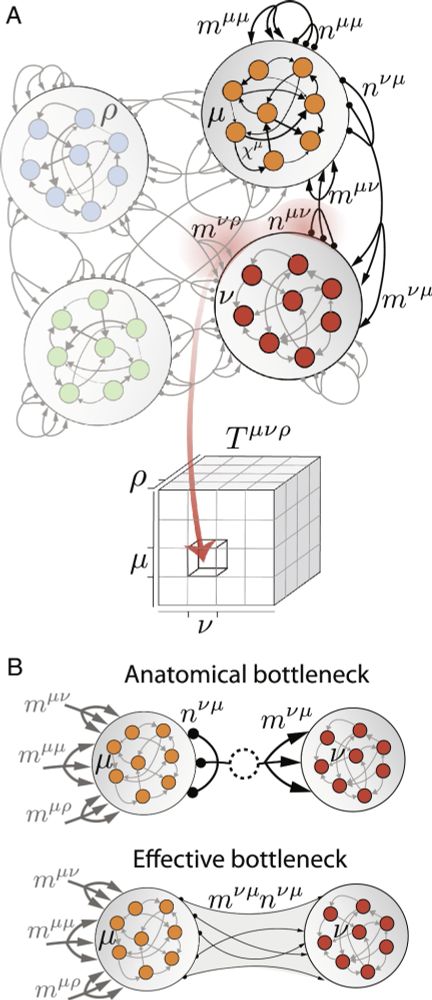
Structure of activity in multiregion recurrent neural networks | PNAS
Neural circuits comprise multiple interconnected regions, each with complex dynamics.
The interplay between local and global activity is thought to...
www.pnas.org
March 7, 2025 at 7:39 PM
(1/23) In addition to the new Lady Gaga album "Mayhem," my paper with Manuel Beiran, "Structure of activity in multiregion recurrent neural networks," has been published today.
PNAS link: www.pnas.org/doi/10.1073/...
(see dclark.io for PDF)
An explainer thread...
PNAS link: www.pnas.org/doi/10.1073/...
(see dclark.io for PDF)
An explainer thread...
Reposted by Anirudh GJ
Music is universal. It varies more within than between societies and can be described by a few key dimensions. That’s because brains operate by using the raw materials of music: oscillations (brainwaves).
www.science.org/doi/10.1126/...
#neuroscience
www.science.org/doi/10.1126/...
#neuroscience
Universality and diversity in human song
Songs exhibit universal patterns across cultures.
www.science.org
June 23, 2025 at 11:38 AM
Music is universal. It varies more within than between societies and can be described by a few key dimensions. That’s because brains operate by using the raw materials of music: oscillations (brainwaves).
www.science.org/doi/10.1126/...
#neuroscience
www.science.org/doi/10.1126/...
#neuroscience
Reposted by Anirudh GJ

1/N
How do neural dynamics in motor cortex interact with those in subcortical networks to flexibly control movement? I’m beyond thrilled to share our work on this problem, led by Eric Kirk @eric-kirk.bsky.social with help from Kangjia Cai!
www.biorxiv.org/content/10.1...
How do neural dynamics in motor cortex interact with those in subcortical networks to flexibly control movement? I’m beyond thrilled to share our work on this problem, led by Eric Kirk @eric-kirk.bsky.social with help from Kangjia Cai!
www.biorxiv.org/content/10.1...
June 23, 2025 at 12:28 PM
1/N
How do neural dynamics in motor cortex interact with those in subcortical networks to flexibly control movement? I’m beyond thrilled to share our work on this problem, led by Eric Kirk @eric-kirk.bsky.social with help from Kangjia Cai!
www.biorxiv.org/content/10.1...
How do neural dynamics in motor cortex interact with those in subcortical networks to flexibly control movement? I’m beyond thrilled to share our work on this problem, led by Eric Kirk @eric-kirk.bsky.social with help from Kangjia Cai!
www.biorxiv.org/content/10.1...
Reposted by Anirudh GJ

Thrilled to announce I'll be starting my own neuro-theory lab, as an Assistant Professor at @yaleneuro.bsky.social @wutsaiyale.bsky.social this Fall!
My group will study offline learning in the sleeping brain: how neural activity self-organizes during sleep and the computations it performs. 🧵
My group will study offline learning in the sleeping brain: how neural activity self-organizes during sleep and the computations it performs. 🧵
June 23, 2025 at 3:55 PM
Thrilled to announce I'll be starting my own neuro-theory lab, as an Assistant Professor at @yaleneuro.bsky.social @wutsaiyale.bsky.social this Fall!
My group will study offline learning in the sleeping brain: how neural activity self-organizes during sleep and the computations it performs. 🧵
My group will study offline learning in the sleeping brain: how neural activity self-organizes during sleep and the computations it performs. 🧵
Reposted by Anirudh GJ

aside from this being a v cool paper I also want to congratulate the authors on the incredible SNR achieved in the title via a complete absence of filler words
Neuromorphic hierarchical modular reservoirs
www.biorxiv.org/content/10.1...
Neuromorphic hierarchical modular reservoirs
www.biorxiv.org/content/10.1...

June 22, 2025 at 5:13 PM
aside from this being a v cool paper I also want to congratulate the authors on the incredible SNR achieved in the title via a complete absence of filler words
Neuromorphic hierarchical modular reservoirs
www.biorxiv.org/content/10.1...
Neuromorphic hierarchical modular reservoirs
www.biorxiv.org/content/10.1...
Reposted by Anirudh GJ

New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7

June 6, 2025 at 5:40 PM
New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
Reposted by Anirudh GJ
Curious about the history of the manifold/trajectory view of neural activity.
My own first exposure was Gilles Laurent's chapter in "21 Problems in Systems Neuroscience", where he cites odor trajectories in locust AL (2005). This was v inspiring as a biophysics student studying dynamical systems...
My own first exposure was Gilles Laurent's chapter in "21 Problems in Systems Neuroscience", where he cites odor trajectories in locust AL (2005). This was v inspiring as a biophysics student studying dynamical systems...
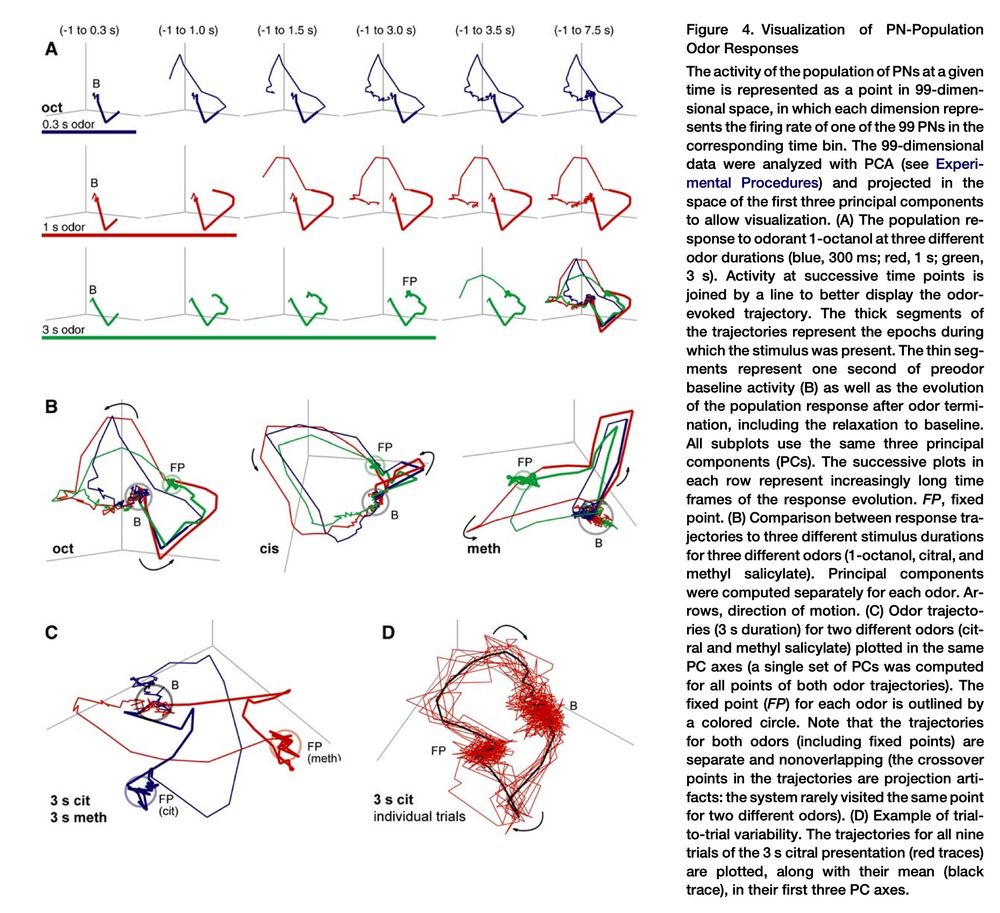

February 21, 2025 at 7:11 PM
Curious about the history of the manifold/trajectory view of neural activity.
My own first exposure was Gilles Laurent's chapter in "21 Problems in Systems Neuroscience", where he cites odor trajectories in locust AL (2005). This was v inspiring as a biophysics student studying dynamical systems...
My own first exposure was Gilles Laurent's chapter in "21 Problems in Systems Neuroscience", where he cites odor trajectories in locust AL (2005). This was v inspiring as a biophysics student studying dynamical systems...
Reposted by Anirudh GJ
I think the biological evidence points to this not being the case. We can see instances where synapses literally undergo a form of reverse plasticity, e.g. see here: www.cell.com/trends/cogni...
I think it cannot be assumed that we never wipe memories from our brains completely!
I think it cannot be assumed that we never wipe memories from our brains completely!
www.cell.com
January 24, 2025 at 11:10 PM
I think the biological evidence points to this not being the case. We can see instances where synapses literally undergo a form of reverse plasticity, e.g. see here: www.cell.com/trends/cogni...
I think it cannot be assumed that we never wipe memories from our brains completely!
I think it cannot be assumed that we never wipe memories from our brains completely!
Reposted by Anirudh GJ

How a neuroscientist solved the mystery of his own
#LongCovid and lead to a new scientific discovery. Inspiring story.
Thank you for sharing your journey @jeffmyau.bsky.social
www.youcanknowthings.com/how-one-neur...
#LongCovid and lead to a new scientific discovery. Inspiring story.
Thank you for sharing your journey @jeffmyau.bsky.social
www.youcanknowthings.com/how-one-neur...

January 8, 2025 at 4:53 PM
How a neuroscientist solved the mystery of his own
#LongCovid and lead to a new scientific discovery. Inspiring story.
Thank you for sharing your journey @jeffmyau.bsky.social
www.youcanknowthings.com/how-one-neur...
#LongCovid and lead to a new scientific discovery. Inspiring story.
Thank you for sharing your journey @jeffmyau.bsky.social
www.youcanknowthings.com/how-one-neur...
Reposted by Anirudh GJ

RL promises "systems that can adapt to their environment". However, no RL system that I know of actually fulfill anything close to this goal, and, furthermore, I'd argue that all the current RL methodologies are actively hostile to this goal. Prove me wrong.
December 30, 2024 at 10:41 PM
RL promises "systems that can adapt to their environment". However, no RL system that I know of actually fulfill anything close to this goal, and, furthermore, I'd argue that all the current RL methodologies are actively hostile to this goal. Prove me wrong.
Reposted by Anirudh GJ

This is also one of the reasons why autonomous vehicles will eventually be much better than humans.
www.pnas.org/doi/10.1073/...
www.pnas.org/doi/10.1073/...

Comparing cooperative geometric puzzle solving in ants versus humans | PNAS
Biological ensembles use collective intelligence to tackle challenges together, but
suboptimal coordination can undermine the effectiveness of grou...
www.pnas.org
December 28, 2024 at 1:30 PM
This is also one of the reasons why autonomous vehicles will eventually be much better than humans.
www.pnas.org/doi/10.1073/...
www.pnas.org/doi/10.1073/...
Reposted by Anirudh GJ
Flexibility of intrinsic neural timescales during distinct behavioral states
www.nature.com/articles/s42...
#neuroscience
www.nature.com/articles/s42...
#neuroscience

Flexibility of intrinsic neural timescales during distinct behavioral states - Communications Biology
Calcium imaging of spontaneously behaving mice show increased intrinsic neural timescales during behavior. The behavioral state of mice can be predicted from the topography of timescales of the cortex...
www.nature.com
December 22, 2024 at 9:28 PM
Flexibility of intrinsic neural timescales during distinct behavioral states
www.nature.com/articles/s42...
#neuroscience
www.nature.com/articles/s42...
#neuroscience
Reposted by Anirudh GJ
This paper looks interesting - it argues that you don’t need adaptive systems like Adam to get good gradient-based training, instead you can just set a learning rate for different groups of units based on initialization:
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
arxiv.org/abs/2412.11768
#MLSky #NeuroAI

No More Adam: Learning Rate Scaling at Initialization is All You Need
In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM...
arxiv.org
December 20, 2024 at 7:00 PM
This paper looks interesting - it argues that you don’t need adaptive systems like Adam to get good gradient-based training, instead you can just set a learning rate for different groups of units based on initialization:
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
Reposted by Anirudh GJ

There is also this one: www.sciencedirect.com/science/arti...

Single cortical neurons as deep artificial neural networks
Utilizing recent advances in machine learning, we introduce a systematic approach to characterize neurons’ input/output (I/O) mapping complexity. Deep…
www.sciencedirect.com
December 16, 2024 at 8:34 PM
There is also this one: www.sciencedirect.com/science/arti...
Reposted by Anirudh GJ
sinthlab EoY social! I'm grateful everyday that I get to work with such a kind and intelligent group of individuals.
@mattperich.bsky.social @oliviercodol.bsky.social @anirudhgj.bsky.social
@mattperich.bsky.social @oliviercodol.bsky.social @anirudhgj.bsky.social

December 12, 2024 at 7:24 PM
sinthlab EoY social! I'm grateful everyday that I get to work with such a kind and intelligent group of individuals.
@mattperich.bsky.social @oliviercodol.bsky.social @anirudhgj.bsky.social
@mattperich.bsky.social @oliviercodol.bsky.social @anirudhgj.bsky.social
Reposted by Anirudh GJ

Neural Attention Memory Models are evolved to optimize the performance of Transformers by actively pruning the KV cache memory. Surprisingly, we find that NAMMs are able to zero-shot transfer its performance gains across architectures, input modalities and even task domains! arxiv.org/abs/2410.13166

An Evolved Universal Transformer Memory
sakana.ai/namm/
Introducing Neural Attention Memory Models (NAMM), a new kind of neural memory system for Transformers that not only boost their performance and efficiency but are also transferable to other foundation models without any additional training!
sakana.ai/namm/
Introducing Neural Attention Memory Models (NAMM), a new kind of neural memory system for Transformers that not only boost their performance and efficiency but are also transferable to other foundation models without any additional training!

December 10, 2024 at 1:41 AM
Neural Attention Memory Models are evolved to optimize the performance of Transformers by actively pruning the KV cache memory. Surprisingly, we find that NAMMs are able to zero-shot transfer its performance gains across architectures, input modalities and even task domains! arxiv.org/abs/2410.13166