



Anh Ta
@anhta24.bsky.social
Mathematician by training. Geometry and Combinatorics. Machine Learning and Cryptography now.
https://scholar.google.com/citations?user=1y0vv1wAAAAJ&hl=en
https://scholar.google.com/citations?user=1y0vv1wAAAAJ&hl=en
Reposted by Anh Ta

Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, Sushrut Karmalkar
A Fourier Space Perspective on Diffusion Models
https://arxiv.org/abs/2505.11278
A Fourier Space Perspective on Diffusion Models
https://arxiv.org/abs/2505.11278
May 19, 2025 at 5:03 AM
Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, Sushrut Karmalkar
A Fourier Space Perspective on Diffusion Models
https://arxiv.org/abs/2505.11278
A Fourier Space Perspective on Diffusion Models
https://arxiv.org/abs/2505.11278
Reposted by Anh Ta

We now have a whole YouTube video explaining our MINDcraft paper, check it out!
youtu.be/MeEcxh9St24
youtu.be/MeEcxh9St24
May 10, 2025 at 8:08 PM
We now have a whole YouTube video explaining our MINDcraft paper, check it out!
youtu.be/MeEcxh9St24
youtu.be/MeEcxh9St24
Reposted by Anh Ta

Wanna learn about autodiff and sparsity? Check out our #ICLR2025 blog post with @adrhill.bsky.social and Alexis Montoison. It has everything you need: matrices with lots of zeros, weird compiler tricks, graph coloring techniques, and a bunch of pretty pics!
iclr-blogposts.github.io/2025/blog/sp...
iclr-blogposts.github.io/2025/blog/sp...

April 28, 2025 at 5:07 PM
Wanna learn about autodiff and sparsity? Check out our #ICLR2025 blog post with @adrhill.bsky.social and Alexis Montoison. It has everything you need: matrices with lots of zeros, weird compiler tricks, graph coloring techniques, and a bunch of pretty pics!
iclr-blogposts.github.io/2025/blog/sp...
iclr-blogposts.github.io/2025/blog/sp...
Reposted by Anh Ta

Recently, my colleague Shayan Mohanty published a technical overview of the papers describing deepseek. He's now revised that article, adding more explanations to make it more digestible for those of us without a background in this field.
martinfowler.com/articles/dee...
martinfowler.com/articles/dee...

The DeepSeek Series: A Technical Overview
An overview of the papers describing the evolution of DeepSeek
martinfowler.com
April 21, 2025 at 1:20 PM
Recently, my colleague Shayan Mohanty published a technical overview of the papers describing deepseek. He's now revised that article, adding more explanations to make it more digestible for those of us without a background in this field.
martinfowler.com/articles/dee...
martinfowler.com/articles/dee...
Reposted by Anh Ta

Huawei's Dream 7B (Diffusion reasoning model), the most powerful open diffusion large language model to date.
Blog: hkunlp.github.io/blog/2025/dr...
Blog: hkunlp.github.io/blog/2025/dr...
April 2, 2025 at 2:50 PM
Huawei's Dream 7B (Diffusion reasoning model), the most powerful open diffusion large language model to date.
Blog: hkunlp.github.io/blog/2025/dr...
Blog: hkunlp.github.io/blog/2025/dr...
Reposted by Anh Ta

This week's #PaperILike is "A Tour of Reinforcement Learning: The View from Continuous Control" (Recht 2018).
Pairs well with the PaperILiked last week -- another good bridge between RL and control theory.
PDF: arxiv.org/abs/1806.09460
Pairs well with the PaperILiked last week -- another good bridge between RL and control theory.
PDF: arxiv.org/abs/1806.09460

A Tour of Reinforcement Learning: The View from Continuous Control
This manuscript surveys reinforcement learning from the perspective of optimization and control with a focus on continuous control applications. It surveys the general formulation, terminology, and ty...
arxiv.org
March 9, 2025 at 3:32 PM
This week's #PaperILike is "A Tour of Reinforcement Learning: The View from Continuous Control" (Recht 2018).
Pairs well with the PaperILiked last week -- another good bridge between RL and control theory.
PDF: arxiv.org/abs/1806.09460
Pairs well with the PaperILiked last week -- another good bridge between RL and control theory.
PDF: arxiv.org/abs/1806.09460
Reposted by Anh Ta
I taught a grad course on AI Agents at UCSD CSE this past quarter. All lecture slides, homeworks & course projects are now open sourced!
I provide a grounding going from Classical Planning & Simulations -> RL Control -> LLMs and how to put it all together
pearls-lab.github.io/ai-agents-co...
I provide a grounding going from Classical Planning & Simulations -> RL Control -> LLMs and how to put it all together
pearls-lab.github.io/ai-agents-co...

March 4, 2025 at 4:37 PM
I taught a grad course on AI Agents at UCSD CSE this past quarter. All lecture slides, homeworks & course projects are now open sourced!
I provide a grounding going from Classical Planning & Simulations -> RL Control -> LLMs and how to put it all together
pearls-lab.github.io/ai-agents-co...
I provide a grounding going from Classical Planning & Simulations -> RL Control -> LLMs and how to put it all together
pearls-lab.github.io/ai-agents-co...
Reposted by Anh Ta
This week's #PaperILike is "Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming" (Bertsekas 2024).
If you know 1 of {RL, controls} and want to understand the other, this is a good starting point.
PDF: arxiv.org/abs/2406.00592
If you know 1 of {RL, controls} and want to understand the other, this is a good starting point.
PDF: arxiv.org/abs/2406.00592
Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming
In this paper we describe a new conceptual framework that connects approximate Dynamic Programming (DP), Model Predictive Control (MPC), and Reinforcement Learning (RL). This framework centers around ...
arxiv.org
March 2, 2025 at 4:19 PM
This week's #PaperILike is "Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming" (Bertsekas 2024).
If you know 1 of {RL, controls} and want to understand the other, this is a good starting point.
PDF: arxiv.org/abs/2406.00592
If you know 1 of {RL, controls} and want to understand the other, this is a good starting point.
PDF: arxiv.org/abs/2406.00592
Reposted by Anh Ta

I updated my ML lecture material: davidpicard.github.io/teaching/
I show many (boomer) ML algorithms with working implementation to prevent the black box effect.
Everything is done in notebooks so that students can play with the algorithms.
Book-ish pdf export: davidpicard.github.io/pdf/poly.pdf
I show many (boomer) ML algorithms with working implementation to prevent the black box effect.
Everything is done in notebooks so that students can play with the algorithms.
Book-ish pdf export: davidpicard.github.io/pdf/poly.pdf
David Picard
davidpicard.github.io
February 27, 2025 at 7:09 PM
I updated my ML lecture material: davidpicard.github.io/teaching/
I show many (boomer) ML algorithms with working implementation to prevent the black box effect.
Everything is done in notebooks so that students can play with the algorithms.
Book-ish pdf export: davidpicard.github.io/pdf/poly.pdf
I show many (boomer) ML algorithms with working implementation to prevent the black box effect.
Everything is done in notebooks so that students can play with the algorithms.
Book-ish pdf export: davidpicard.github.io/pdf/poly.pdf
Reposted by Anh Ta

Our beginner's oriented accessible introduction to modern deep RL is now published in Foundations and Trends in Optimization. It is a great entry to the field if you want to jumpstart into RL!
@bernhard-jaeger.bsky.social
www.nowpublishers.com/article/Deta...
arxiv.org/abs/2312.08365
@bernhard-jaeger.bsky.social
www.nowpublishers.com/article/Deta...
arxiv.org/abs/2312.08365

February 22, 2025 at 7:32 PM
Our beginner's oriented accessible introduction to modern deep RL is now published in Foundations and Trends in Optimization. It is a great entry to the field if you want to jumpstart into RL!
@bernhard-jaeger.bsky.social
www.nowpublishers.com/article/Deta...
arxiv.org/abs/2312.08365
@bernhard-jaeger.bsky.social
www.nowpublishers.com/article/Deta...
arxiv.org/abs/2312.08365
Reposted by Anh Ta

KS studies the Matrix Multiplication Verification Problem (MMV), in which you get three n x n matrices A, B, C (say, with poly(n)-bounded integer entries) and want to decide whether AB = C. This is trivial to solve in MM time O(n^omega) deterministically: compute AB and compare it with C. 2/
February 21, 2025 at 4:50 AM
KS studies the Matrix Multiplication Verification Problem (MMV), in which you get three n x n matrices A, B, C (say, with poly(n)-bounded integer entries) and want to decide whether AB = C. This is trivial to solve in MM time O(n^omega) deterministically: compute AB and compare it with C. 2/
Reposted by Anh Ta

Introducing The AI CUDA Engineer: An agentic AI system that automates the production of highly optimized CUDA kernels.
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:

February 20, 2025 at 1:50 AM
Introducing The AI CUDA Engineer: An agentic AI system that automates the production of highly optimized CUDA kernels.
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:
why on earth that somebody thought of doing this in the first place

Complex step approximation is a numerical method to approximate the derivative from a single function evaluation using complex arithmetic. It is some kind of “poor man” automatic differentiation. https://nhigham.com/2020/10/06/what-is-the-complex-step-approximation/

February 17, 2025 at 11:56 AM
why on earth that somebody thought of doing this in the first place
Reposted by Anh Ta

Lorenzo Pastori, Arthur Grundner, Veronika Eyring, Mierk Schwabe
Quantum Neural Networks for Cloud Cover Parameterizations in Climate Models
https://arxiv.org/abs/2502.10131
Quantum Neural Networks for Cloud Cover Parameterizations in Climate Models
https://arxiv.org/abs/2502.10131
February 17, 2025 at 5:35 AM
Lorenzo Pastori, Arthur Grundner, Veronika Eyring, Mierk Schwabe
Quantum Neural Networks for Cloud Cover Parameterizations in Climate Models
https://arxiv.org/abs/2502.10131
Quantum Neural Networks for Cloud Cover Parameterizations in Climate Models
https://arxiv.org/abs/2502.10131
Reposted by Anh Ta
Przemys{\l}aw Pawlitko, Natalia Mo\'cko, Marcin Niemiec, Piotr Cho{\l}da
Implementation and Analysis of Regev's Quantum Factorization Algorithm
https://arxiv.org/abs/2502.09772
Implementation and Analysis of Regev's Quantum Factorization Algorithm
https://arxiv.org/abs/2502.09772
February 17, 2025 at 7:19 AM
Przemys{\l}aw Pawlitko, Natalia Mo\'cko, Marcin Niemiec, Piotr Cho{\l}da
Implementation and Analysis of Regev's Quantum Factorization Algorithm
https://arxiv.org/abs/2502.09772
Implementation and Analysis of Regev's Quantum Factorization Algorithm
https://arxiv.org/abs/2502.09772
Reposted by Anh Ta

Enjoyed sharing our work on electric fish with @dryohanjohn.bsky.social⚡🐟 Their electric "conversations" help us build models to discover neural mechanisms of social cognition. Work led by Sonja Johnson-Yu & @satpreetsingh.bsky.social with Nate Sawtell
kempnerinstitute.harvard.edu/news/what-el...
kempnerinstitute.harvard.edu/news/what-el...
February 14, 2025 at 9:16 PM
Enjoyed sharing our work on electric fish with @dryohanjohn.bsky.social⚡🐟 Their electric "conversations" help us build models to discover neural mechanisms of social cognition. Work led by Sonja Johnson-Yu & @satpreetsingh.bsky.social with Nate Sawtell
kempnerinstitute.harvard.edu/news/what-el...
kempnerinstitute.harvard.edu/news/what-el...
Reposted by Anh Ta

Model-free deep RL algorithms like NFSP, PSRO, ESCHER, & R-NaD are tailor-made for games with hidden information (e.g. poker).
We performed the largest-ever comparison of these algorithms.
We find that they do not outperform generic policy gradient methods, such as PPO.
arxiv.org/abs/2502.08938
1/N
We performed the largest-ever comparison of these algorithms.
We find that they do not outperform generic policy gradient methods, such as PPO.
arxiv.org/abs/2502.08938
1/N




February 14, 2025 at 6:41 PM
Model-free deep RL algorithms like NFSP, PSRO, ESCHER, & R-NaD are tailor-made for games with hidden information (e.g. poker).
We performed the largest-ever comparison of these algorithms.
We find that they do not outperform generic policy gradient methods, such as PPO.
arxiv.org/abs/2502.08938
1/N
We performed the largest-ever comparison of these algorithms.
We find that they do not outperform generic policy gradient methods, such as PPO.
arxiv.org/abs/2502.08938
1/N
Reposted by Anh Ta

🔥 Want to train large neural networks WITHOUT Adam while using less memory and getting better results? ⚡
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇

February 13, 2025 at 4:51 PM
🔥 Want to train large neural networks WITHOUT Adam while using less memory and getting better results? ⚡
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇
Reposted by Anh Ta

this paper is a pretty impressive tour de force in neural network training: arxiv.org/abs/2410.11081
pretty inspiring to me -- network isn't converging? rigorously monitor every term in your loss to identify where in the architecture something is going wrong!
pretty inspiring to me -- network isn't converging? rigorously monitor every term in your loss to identify where in the architecture something is going wrong!

Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Consistency models (CMs) are a powerful class of diffusion-based generative models optimized for fast sampling. Most existing CMs are trained using discretized timesteps, which introduce additional hy...
arxiv.org
February 13, 2025 at 12:52 PM
this paper is a pretty impressive tour de force in neural network training: arxiv.org/abs/2410.11081
pretty inspiring to me -- network isn't converging? rigorously monitor every term in your loss to identify where in the architecture something is going wrong!
pretty inspiring to me -- network isn't converging? rigorously monitor every term in your loss to identify where in the architecture something is going wrong!
Reposted by Anh Ta
Obsessed with the work coming out of Finale Doshi-Velez's group; they don't just take the limits of the real world for ML deployment seriously but instead turn it into new algorithmic ideas
arxiv.org/abs/2406.08636
arxiv.org/abs/2406.08636

Towards Integrating Personal Knowledge into Test-Time Predictions
Machine learning (ML) models can make decisions based on large amounts of data, but they can be missing personal knowledge available to human users about whom predictions are made. For example, a mode...
arxiv.org
February 13, 2025 at 4:13 AM
Obsessed with the work coming out of Finale Doshi-Velez's group; they don't just take the limits of the real world for ML deployment seriously but instead turn it into new algorithmic ideas
arxiv.org/abs/2406.08636
arxiv.org/abs/2406.08636
Reposted by Anh Ta

Our new paper with @chrismlangdon is just out in @natureneuro.bsky.social! We show that high-dimensional RNNs use low-dimensional circuit mechanisms for cognitive tasks and identify a latent inhibitory mechanism for context-dependent decisions in PFC data.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
February 12, 2025 at 6:19 PM
Our new paper with @chrismlangdon is just out in @natureneuro.bsky.social! We show that high-dimensional RNNs use low-dimensional circuit mechanisms for cognitive tasks and identify a latent inhibitory mechanism for context-dependent decisions in PFC data.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
I just checked the data of accepted papers at ICLR '25. The authors with most submission had 21 accepted out of 42 submitted. Oh well!
February 10, 2025 at 8:50 PM
I just checked the data of accepted papers at ICLR '25. The authors with most submission had 21 accepted out of 42 submitted. Oh well!
Reposted by Anh Ta

@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/

February 10, 2025 at 4:32 AM
@xtimv.bsky.social and I were just discussing this interesting comment in the DeepSeek paper introducing GRPO: a different way of setting up the KL loss.
It's a little hard to reason about what this does to the objective. 1/
It's a little hard to reason about what this does to the objective. 1/
Reposted by Anh Ta

Restarting an old routine "Daily Dose of Good Papers" together w @vaibhavadlakha.bsky.social
Sharing my notes and thoughts here 🧵
Sharing my notes and thoughts here 🧵
November 23, 2024 at 12:04 AM
Restarting an old routine "Daily Dose of Good Papers" together w @vaibhavadlakha.bsky.social
Sharing my notes and thoughts here 🧵
Sharing my notes and thoughts here 🧵
Reposted by Anh Ta

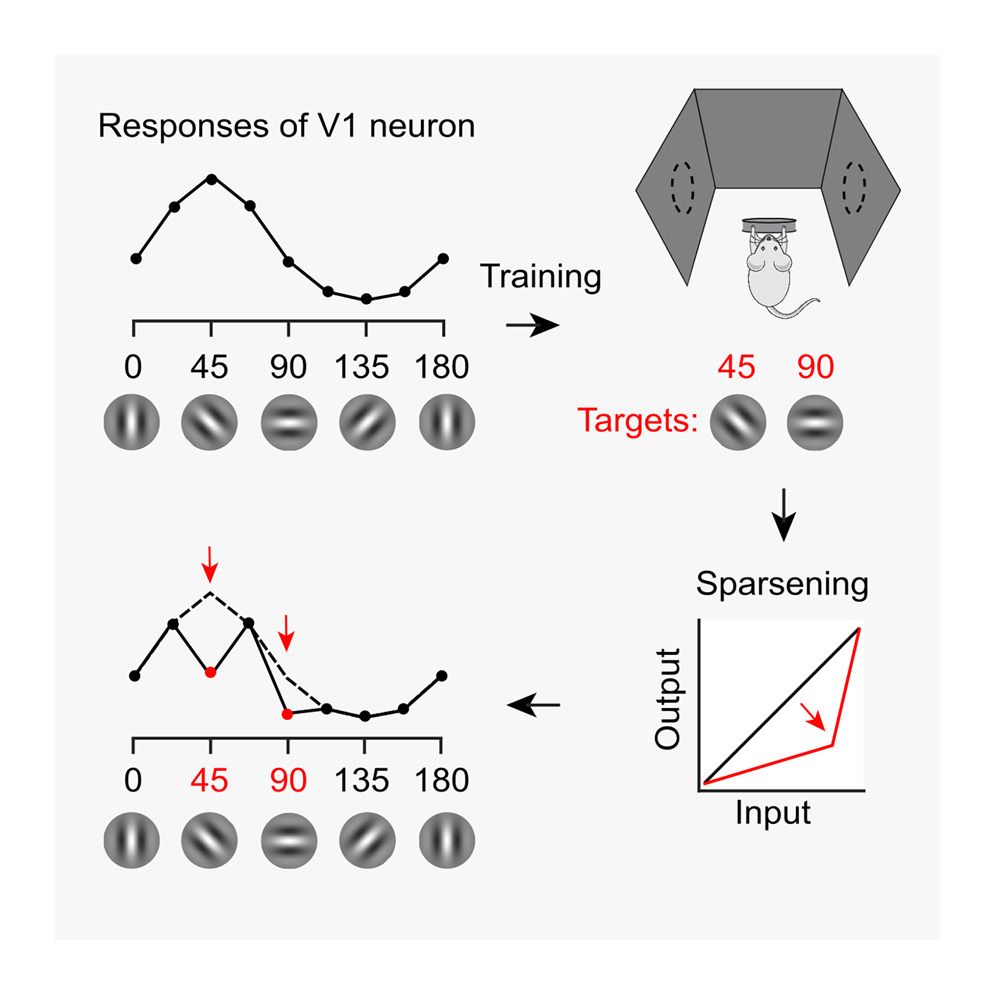
It's finally out!
Visual experience orthogonalizes visual cortical responses
Training in a visual task changes V1 tuning curves in odd ways. This effect is explained by a simple convex transformation. It orthogonalizes the population, making it easier to decode.
10.1016/j.celrep.2025.115235
Visual experience orthogonalizes visual cortical responses
Training in a visual task changes V1 tuning curves in odd ways. This effect is explained by a simple convex transformation. It orthogonalizes the population, making it easier to decode.
10.1016/j.celrep.2025.115235
February 2, 2025 at 9:59 AM
It's finally out!
Visual experience orthogonalizes visual cortical responses
Training in a visual task changes V1 tuning curves in odd ways. This effect is explained by a simple convex transformation. It orthogonalizes the population, making it easier to decode.
10.1016/j.celrep.2025.115235
Visual experience orthogonalizes visual cortical responses
Training in a visual task changes V1 tuning curves in odd ways. This effect is explained by a simple convex transformation. It orthogonalizes the population, making it easier to decode.
10.1016/j.celrep.2025.115235