




andrea wang
@andreawwenyi.bsky.social
Reposted by andrea wang

I used to focus on left versus right. Now I’m much more worried about the money at the top. But while it might seem strange to say it, I think this is a hopeful way of looking at the world that opens the door to coalitions that seemed impossible before. My first for the @newrepublic.com:

October 15, 2025 at 2:19 PM
I used to focus on left versus right. Now I’m much more worried about the money at the top. But while it might seem strange to say it, I think this is a hopeful way of looking at the world that opens the door to coalitions that seemed impossible before. My first for the @newrepublic.com:
Reposted by andrea wang

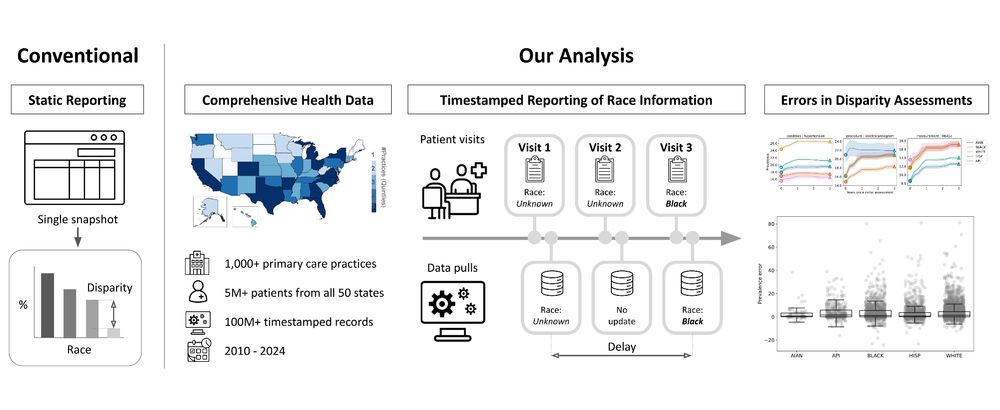
I am presenting a new 📝 “Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments” at @facct.bsky.social on Thursday, with @aparnabee.bsky.social, Derek Ouyang, @allisonkoe.bsky.social, @marzyehghassemi.bsky.social, and Dan Ho. 🔗: arxiv.org/abs/2506.13735
(1/n)
(1/n)

June 24, 2025 at 2:51 PM
I am presenting a new 📝 “Bias Delayed is Bias Denied? Assessing the Effect of Reporting Delays on Disparity Assessments” at @facct.bsky.social on Thursday, with @aparnabee.bsky.social, Derek Ouyang, @allisonkoe.bsky.social, @marzyehghassemi.bsky.social, and Dan Ho. 🔗: arxiv.org/abs/2506.13735
(1/n)
(1/n)
Reposted by andrea wang

I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419

June 23, 2025 at 2:45 PM
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419
Reposted by andrea wang

Worth noting today that the entire budget of the NEH is about $200M.

According to acting DOD Comptroller Bryn McDonnell it'll cost $134M for the deployment of the Guard to Los Angeles.
June 10, 2025 at 3:48 PM
Worth noting today that the entire budget of the NEH is about $200M.
Reposted by andrea wang

New NEH-supported tutorial on running LLMs locally with ollama! Your laptop is more powerful than you think. Save money, privacy, and energy.
aiforhumanists.com/tutorials/
aiforhumanists.com/tutorials/
Code Tutorials
The AI for Humanists project is developing resources to enable DH scholars to explore how large language models and AI technologies can be used in their research and teaching. Find an annotated biblio...
aiforhumanists.com
June 10, 2025 at 5:18 PM
New NEH-supported tutorial on running LLMs locally with ollama! Your laptop is more powerful than you think. Save money, privacy, and energy.
aiforhumanists.com/tutorials/
aiforhumanists.com/tutorials/
Reposted by andrea wang

I'm joining Wisconsin CS as an assistant professor in fall 2026!! There, I'll continue working on language models, computational social science, & responsible AI. 🌲🧀🚣🏻♀️ Apply to be my PhD student!
Before then, I'll postdoc for a year in the NLP group at another UW 🏔️ in the Pacific Northwest
Before then, I'll postdoc for a year in the NLP group at another UW 🏔️ in the Pacific Northwest


May 5, 2025 at 7:54 PM
I'm joining Wisconsin CS as an assistant professor in fall 2026!! There, I'll continue working on language models, computational social science, & responsible AI. 🌲🧀🚣🏻♀️ Apply to be my PhD student!
Before then, I'll postdoc for a year in the NLP group at another UW 🏔️ in the Pacific Northwest
Before then, I'll postdoc for a year in the NLP group at another UW 🏔️ in the Pacific Northwest
Reposted by andrea wang

For the HTR and OCR crew:
New paper by Jonathan Bourne. He's been working to help DLOC handle OCR for a whole bunch of Caribbean historical newspapers. "Scrambled text: fine-tuning language models for OCR error correction using synthetic data" link.springer.com/article/10.1...
New paper by Jonathan Bourne. He's been working to help DLOC handle OCR for a whole bunch of Caribbean historical newspapers. "Scrambled text: fine-tuning language models for OCR error correction using synthetic data" link.springer.com/article/10.1...

Scrambled text: fine-tuning language models for OCR error correction using synthetic data - International Journal on Document Analysis and Recognition (IJDAR)
OCR errors are common in digitised historical archives significantly affecting their usability and value. Generative Language Models (LMs) have shown potential for correcting these errors using the co...
link.springer.com
April 27, 2025 at 3:57 PM
For the HTR and OCR crew:
New paper by Jonathan Bourne. He's been working to help DLOC handle OCR for a whole bunch of Caribbean historical newspapers. "Scrambled text: fine-tuning language models for OCR error correction using synthetic data" link.springer.com/article/10.1...
New paper by Jonathan Bourne. He's been working to help DLOC handle OCR for a whole bunch of Caribbean historical newspapers. "Scrambled text: fine-tuning language models for OCR error correction using synthetic data" link.springer.com/article/10.1...
Reposted by andrea wang

Slightly paraphrasing @oms279.bsky.social during his talk at #COMPTEXT2025:
"The single most important use case for LLMs in sociology is turning unstructured data into structured data."
Discussing his recent work on codebooks, prompts, and information extraction: osf.io/preprints/so...
"The single most important use case for LLMs in sociology is turning unstructured data into structured data."
Discussing his recent work on codebooks, prompts, and information extraction: osf.io/preprints/so...
April 25, 2025 at 2:16 PM
Slightly paraphrasing @oms279.bsky.social during his talk at #COMPTEXT2025:
"The single most important use case for LLMs in sociology is turning unstructured data into structured data."
Discussing his recent work on codebooks, prompts, and information extraction: osf.io/preprints/so...
"The single most important use case for LLMs in sociology is turning unstructured data into structured data."
Discussing his recent work on codebooks, prompts, and information extraction: osf.io/preprints/so...
Reposted by andrea wang

Hi everyone, I am excited to share our large-scale survey study with 800+ researchers, which reveals researchers’ usage and perceptions of LLMs as research tools, and how the usage and perceptions differ based on demographics.
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025

LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipe...
arxiv.org
December 2, 2024 at 7:45 PM
Hi everyone, I am excited to share our large-scale survey study with 800+ researchers, which reveals researchers’ usage and perceptions of LLMs as research tools, and how the usage and perceptions differ based on demographics.
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
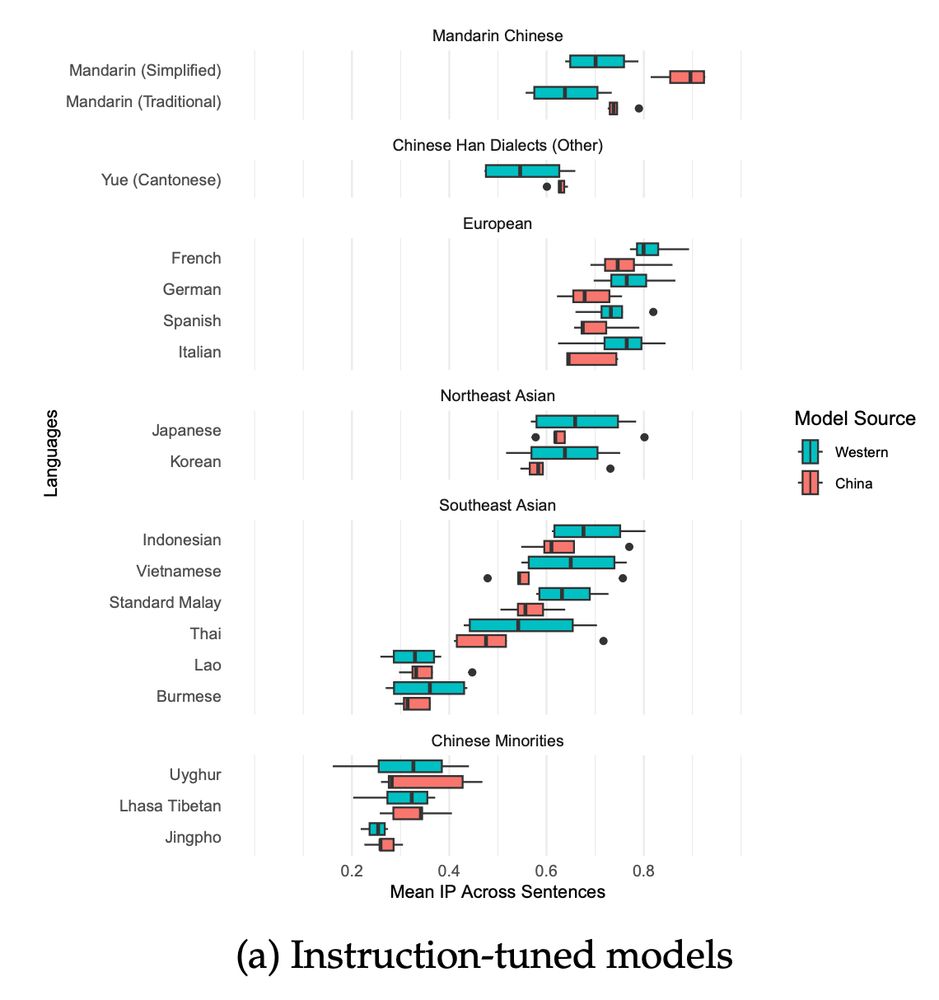
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
April 9, 2025 at 8:28 PM
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Reposted by andrea wang

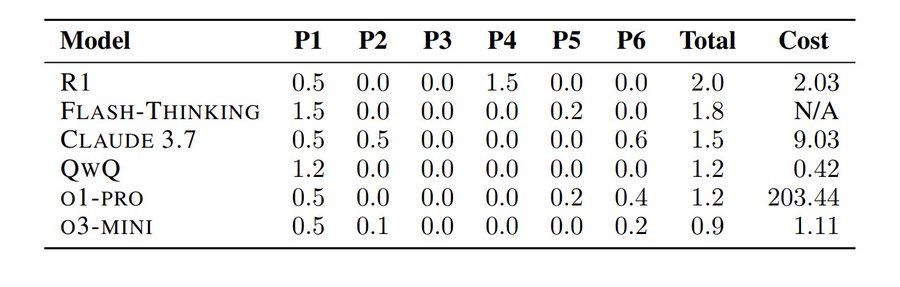
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
March 31, 2025 at 8:33 PM
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
Reposted by andrea wang

*NEW DATASET AND PAPER* (CHI2025): How are online communities responding to AI-generated content (AIGC)? We study this by collecting and analyzing the public rules of 300,000+ subreddits in 2023 and 2024. 1/
March 26, 2025 at 5:17 PM
*NEW DATASET AND PAPER* (CHI2025): How are online communities responding to AI-generated content (AIGC)? We study this by collecting and analyzing the public rules of 300,000+ subreddits in 2023 and 2024. 1/
Reposted by andrea wang

hey it's that time of year again, when people start to wonder whether AIES is actually happening and when this year’s paper deadline might be if so! anyone know anything about the ACM/AAAI conference on AI Ethics & Society for 2025?
(I used to ask about this every year on Twitter haha.)
(I used to ask about this every year on Twitter haha.)
March 19, 2025 at 7:00 PM
hey it's that time of year again, when people start to wonder whether AIES is actually happening and when this year’s paper deadline might be if so! anyone know anything about the ACM/AAAI conference on AI Ethics & Society for 2025?
(I used to ask about this every year on Twitter haha.)
(I used to ask about this every year on Twitter haha.)
Reposted by andrea wang
Best Student Paper at #AIES 2024 went to @andreawwenyi.bsky.social! Annotating gender-biased narratives in the courtroom is a complex, nuanced task with frequent subjective decision-making by legal experts. We asked: What do experts desire from a language model in this annotation process?
November 11, 2024 at 3:49 PM
Best Student Paper at #AIES 2024 went to @andreawwenyi.bsky.social! Annotating gender-biased narratives in the courtroom is a complex, nuanced task with frequent subjective decision-making by legal experts. We asked: What do experts desire from a language model in this annotation process?
How do LLMs represent relationships between languages? By studying the embedding layers of XLM-R and mT5, we find they are highly interpretable. LLMs can find semantic alignment as an emergent property! Joint work with @dmimno.bsky.social. 🧵

February 21, 2024 at 3:57 PM
How do LLMs represent relationships between languages? By studying the embedding layers of XLM-R and mT5, we find they are highly interpretable. LLMs can find semantic alignment as an emergent property! Joint work with @dmimno.bsky.social. 🧵