




andrea wang
@andreawwenyi.bsky.social
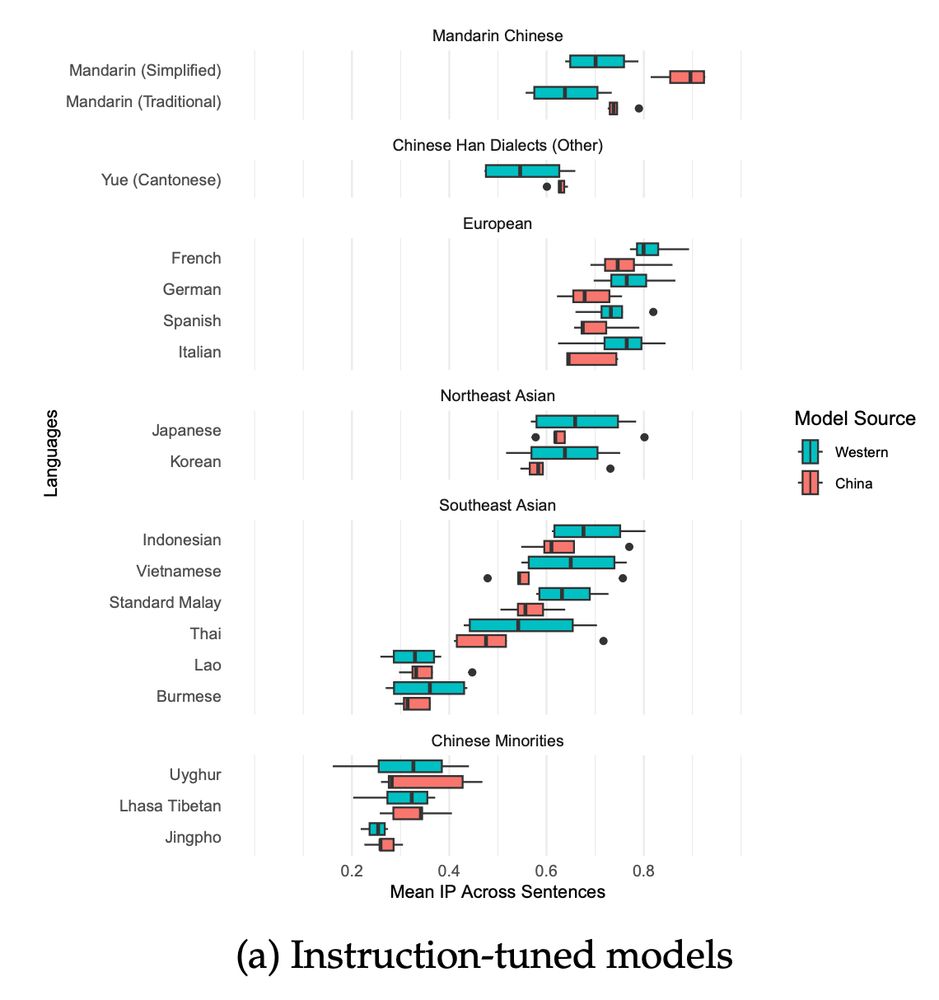
In fact, many LLMs from China fail to even recognize some lower resource Chinese languages such as Uyghur.

April 9, 2025 at 8:28 PM
In fact, many LLMs from China fail to even recognize some lower resource Chinese languages such as Uyghur.
LLMs from China are highly correlated with Western LLMs in multilingual performance (0.93 - 9.99) on tasks such as reading comprehension.

April 9, 2025 at 8:28 PM
LLMs from China are highly correlated with Western LLMs in multilingual performance (0.93 - 9.99) on tasks such as reading comprehension.
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
April 9, 2025 at 8:28 PM
[New preprint!] Do Chinese AI Models Speak Chinese Languages? Not really. Chinese LLMs like DeepSeek are better at French than Cantonese. Joint work with
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Unso Jo and @dmimno.bsky.social . Link to paper: arxiv.org/pdf/2504.00289
🧵
Embedding geometries are similar across model families and scales, as measured by canonical angles. XLM-R models are extremely similar to each other, as well as mT5-small and base. All models are far from random (0.14–0.27).

February 21, 2024 at 3:59 PM
Embedding geometries are similar across model families and scales, as measured by canonical angles. XLM-R models are extremely similar to each other, as well as mT5-small and base. All models are far from random (0.14–0.27).
The diversity of neighborhoods in mT5 varies by category. For tokens in two Japanese writing systems: KATAKANA, for words of foreign origin, has more diverse neighbors than HIRAGANA, used for native Japanese words.

February 21, 2024 at 3:59 PM
The diversity of neighborhoods in mT5 varies by category. For tokens in two Japanese writing systems: KATAKANA, for words of foreign origin, has more diverse neighbors than HIRAGANA, used for native Japanese words.
The nearest neighbors of mT5 tokens are often translations. NLP spent 10 years trying to make word embeddings align across languages. mT5 embeddings find cross-lingual semantic alignment without even being asked!

February 21, 2024 at 3:58 PM
The nearest neighbors of mT5 tokens are often translations. NLP spent 10 years trying to make word embeddings align across languages. mT5 embeddings find cross-lingual semantic alignment without even being asked!
mT5 embeddings neighborhoods are more linguistically diverse: the 50 nearest neighbors for any token represent an average of 7.61 writing systems, compared to 1.64 with XLM-R embedding.

February 21, 2024 at 3:58 PM
mT5 embeddings neighborhoods are more linguistically diverse: the 50 nearest neighbors for any token represent an average of 7.61 writing systems, compared to 1.64 with XLM-R embedding.
Tokens in different writing systems can be linearly separated with an average of 99.2 % accuracy for XLM. Even in high-dimensional space, mT5 embeddings are less separable.

February 21, 2024 at 3:57 PM
Tokens in different writing systems can be linearly separated with an average of 99.2 % accuracy for XLM. Even in high-dimensional space, mT5 embeddings are less separable.
XLM-R embeddings partition by language, while mT5 has more overlap. Since it's hard to identify the language of BPE tokens, we use Unicode writing systems instead. Both plots contain points for the intersection of the two models' vocabularies.

February 21, 2024 at 3:57 PM
XLM-R embeddings partition by language, while mT5 has more overlap. Since it's hard to identify the language of BPE tokens, we use Unicode writing systems instead. Both plots contain points for the intersection of the two models' vocabularies.
How do LLMs represent relationships between languages? By studying the embedding layers of XLM-R and mT5, we find they are highly interpretable. LLMs can find semantic alignment as an emergent property! Joint work with @dmimno.bsky.social. 🧵

February 21, 2024 at 3:57 PM
How do LLMs represent relationships between languages? By studying the embedding layers of XLM-R and mT5, we find they are highly interpretable. LLMs can find semantic alignment as an emergent property! Joint work with @dmimno.bsky.social. 🧵