



Aaron Mueller
@amuuueller.bsky.social
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
Reposted by Aaron Mueller

✨ The schedule for our INTERPLAY workshop at COLM is live! ✨
🗓️ October 10th, Room 518C
🔹 Invited talks from @sarah-nlp.bsky.social John Hewitt @amuuueller.bsky.social @kmahowald.bsky.social
🔹 Paper presentations and posters
🔹 Closing roundtable discussion.
Join us in Montréal! @colmweb.org
🗓️ October 10th, Room 518C
🔹 Invited talks from @sarah-nlp.bsky.social John Hewitt @amuuueller.bsky.social @kmahowald.bsky.social
🔹 Paper presentations and posters
🔹 Closing roundtable discussion.
Join us in Montréal! @colmweb.org

October 9, 2025 at 5:30 PM
✨ The schedule for our INTERPLAY workshop at COLM is live! ✨
🗓️ October 10th, Room 518C
🔹 Invited talks from @sarah-nlp.bsky.social John Hewitt @amuuueller.bsky.social @kmahowald.bsky.social
🔹 Paper presentations and posters
🔹 Closing roundtable discussion.
Join us in Montréal! @colmweb.org
🗓️ October 10th, Room 518C
🔹 Invited talks from @sarah-nlp.bsky.social John Hewitt @amuuueller.bsky.social @kmahowald.bsky.social
🔹 Paper presentations and posters
🔹 Closing roundtable discussion.
Join us in Montréal! @colmweb.org
What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!

October 1, 2025 at 2:03 PM
What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
Reposted by Aaron Mueller

In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)
August 5, 2025 at 2:36 PM
In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!

July 17, 2025 at 5:45 PM
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
Reposted by Aaron Mueller
The new "Lookback" paper from @nikhil07prakash.bsky.social contains a surprising insight...
70b/405b LLMs use double pointers, akin to C programmers' double (**) pointers. They show up when the LLM is "knowing what Sally knows Ann knows", i.e., Theory of Mind.
bsky.app/profile/nik...
70b/405b LLMs use double pointers, akin to C programmers' double (**) pointers. They show up when the LLM is "knowing what Sally knows Ann knows", i.e., Theory of Mind.
bsky.app/profile/nik...

@nikhil07prakash.bsky.social
How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
bsky.app
June 25, 2025 at 3:00 PM
The new "Lookback" paper from @nikhil07prakash.bsky.social contains a surprising insight...
70b/405b LLMs use double pointers, akin to C programmers' double (**) pointers. They show up when the LLM is "knowing what Sally knows Ann knows", i.e., Theory of Mind.
bsky.app/profile/nik...
70b/405b LLMs use double pointers, akin to C programmers' double (**) pointers. They show up when the LLM is "knowing what Sally knows Ann knows", i.e., Theory of Mind.
bsky.app/profile/nik...
SAEs have been found to massively underperform supervised methods for steering neural networks.
In new work led by @danaarad.bsky.social, we find that this problem largely disappears if you select the right features!
In new work led by @danaarad.bsky.social, we find that this problem largely disappears if you select the right features!
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵

May 27, 2025 at 5:07 PM
SAEs have been found to massively underperform supervised methods for steering neural networks.
In new work led by @danaarad.bsky.social, we find that this problem largely disappears if you select the right features!
In new work led by @danaarad.bsky.social, we find that this problem largely disappears if you select the right features!
Reposted by Aaron Mueller

Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
May 27, 2025 at 4:06 PM
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Reposted by Aaron Mueller

Couldn’t be happier to have co-authored this will a stellar team, including: Michael Hu, @amuuueller.bsky.social, @alexwarstadt.bsky.social, @lchoshen.bsky.social, Chengxu Zhuang, @adinawilliams.bsky.social, Ryan Cotterell, @tallinzen.bsky.social
May 12, 2025 at 3:48 PM
Couldn’t be happier to have co-authored this will a stellar team, including: Michael Hu, @amuuueller.bsky.social, @alexwarstadt.bsky.social, @lchoshen.bsky.social, Chengxu Zhuang, @adinawilliams.bsky.social, Ryan Cotterell, @tallinzen.bsky.social
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!

April 23, 2025 at 6:15 PM
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
Lots of work coming soon to @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April/May! Come chat with us about new methods for interpreting and editing LLMs, multilingual concept representations, sentence processing mechanisms, and arithmetic reasoning. 🧵
March 11, 2025 at 2:30 PM
Lots of work coming soon to @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April/May! Come chat with us about new methods for interpreting and editing LLMs, multilingual concept representations, sentence processing mechanisms, and arithmetic reasoning. 🧵
It’s common to assume one task = one static circuit. But this ignores that the important computations depend on position!
We propose a way to find 𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻-𝗮𝘄𝗮𝗿𝗲 circuits. (Highlight: using LLMs to help us create multi-token causal abstractions!)
We propose a way to find 𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻-𝗮𝘄𝗮𝗿𝗲 circuits. (Highlight: using LLMs to help us create multi-token causal abstractions!)

1/13 LLM circuits tell us where the computation happens inside the model—but the computation varies by token position, a key detail often ignored!
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇
We propose a method to automatically find position-aware circuits, improving faithfulness while keeping circuits compact. 🧵👇

March 6, 2025 at 10:28 PM
It’s common to assume one task = one static circuit. But this ignores that the important computations depend on position!
We propose a way to find 𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻-𝗮𝘄𝗮𝗿𝗲 circuits. (Highlight: using LLMs to help us create multi-token causal abstractions!)
We propose a way to find 𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻-𝗮𝘄𝗮𝗿𝗲 circuits. (Highlight: using LLMs to help us create multi-token causal abstractions!)
What can mechanistic interpretability do for computational psycholinguists? @michaelwhanna.bsky.social and I took a stab at this question! We investigate garden path sentence processing in LMs at the feature (circuit) level.

Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10

December 19, 2024 at 1:56 PM
What can mechanistic interpretability do for computational psycholinguists? @michaelwhanna.bsky.social and I took a stab at this question! We investigate garden path sentence processing in LMs at the feature (circuit) level.
Reposted by Aaron Mueller

Today we had the pleasure to host @michaelwhanna.bsky.social from @amsterdamnlp.bsky.social for a seminar on his work w/ @amuuueller.bsky.social to interpret incremental sentence processing in language models. Thank you for joining us Michael!

November 22, 2024 at 3:52 PM
Today we had the pleasure to host @michaelwhanna.bsky.social from @amsterdamnlp.bsky.social for a seminar on his work w/ @amuuueller.bsky.social to interpret incremental sentence processing in language models. Thank you for joining us Michael!
Reposted by Aaron Mueller

The babies are now in their beds, but what a year it was!
Highlighting some findings of BabyLM
Architectures & Training objective matter a lot (and got the highest scores)
alphaxiv.org/pdf/2410.24159
🤖
Highlighting some findings of BabyLM
Architectures & Training objective matter a lot (and got the highest scores)
alphaxiv.org/pdf/2410.24159
🤖

November 19, 2024 at 3:20 PM
The babies are now in their beds, but what a year it was!
Highlighting some findings of BabyLM
Architectures & Training objective matter a lot (and got the highest scores)
alphaxiv.org/pdf/2410.24159
🤖
Highlighting some findings of BabyLM
Architectures & Training objective matter a lot (and got the highest scores)
alphaxiv.org/pdf/2410.24159
🤖
Reposted by Aaron Mueller

How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
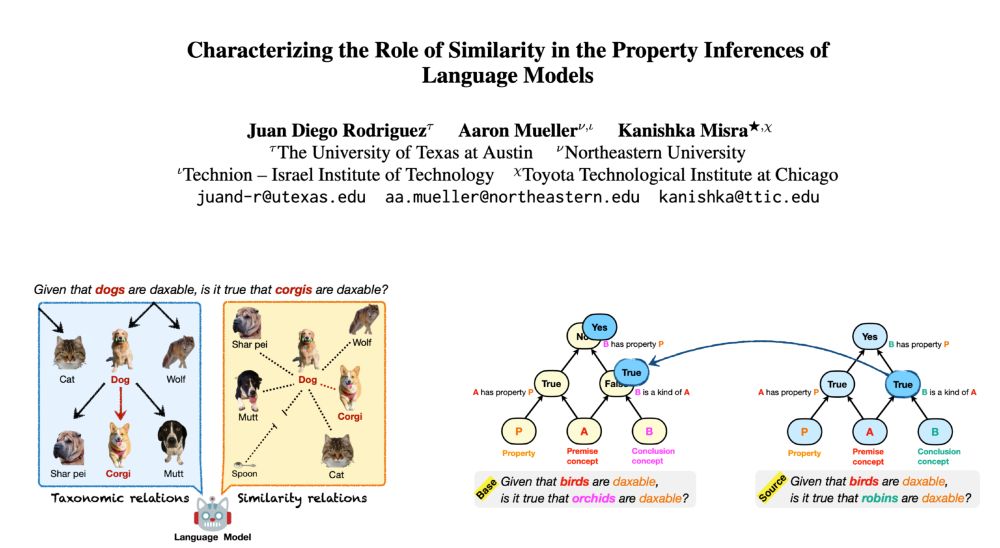
November 8, 2024 at 9:40 PM
How do language models organize concepts and their properties? Do they use taxonomies to infer new properties, or infer based on concept similarities? Apparently, both!
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social
🌟 New paper with my fantastic collaborators @amuuueller.bsky.social and @kanishka.bsky.social