



Aaron Mueller
@amuuueller.bsky.social
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
Aruna Sankaranarayanan, @arnabsensharma.bsky.social absensharma.bsky.social @ericwtodd.bsky.social ky.social @davidbau.bsky.social u.bsky.social @boknilev.bsky.social (2/2)
October 1, 2025 at 2:03 PM
Aruna Sankaranarayanan, @arnabsensharma.bsky.social absensharma.bsky.social @ericwtodd.bsky.social ky.social @davidbau.bsky.social u.bsky.social @boknilev.bsky.social (2/2)
Thanks again to the co-authors! Such a wide survey required a lot of perspectives. @jannikbrinkmann.bsky.social Millicent Li, Samuel Marks, @koyena.bsky.social @nikhil07prakash.bsky.social @canrager.bsky.social (1/2)
October 1, 2025 at 2:03 PM
Thanks again to the co-authors! Such a wide survey required a lot of perspectives. @jannikbrinkmann.bsky.social Millicent Li, Samuel Marks, @koyena.bsky.social @nikhil07prakash.bsky.social @canrager.bsky.social (1/2)
See the paper for more details! arxiv.org/abs/2408.01416

The Quest for the Right Mediator: Surveying Mechanistic Interpretability Through the Lens of Causal Mediation Analysis
Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not...
arxiv.org
October 1, 2025 at 2:03 PM
See the paper for more details! arxiv.org/abs/2408.01416
We also made the causal graph formalism more precise. Interpretability and causality are intimately linked; the latter makes the former more trustworthy and rigorous. This formal link should be strengthened in future work.

October 1, 2025 at 2:03 PM
We also made the causal graph formalism more precise. Interpretability and causality are intimately linked; the latter makes the former more trustworthy and rigorous. This formal link should be strengthened in future work.
One of the bigger changes was establishing criteria for success in interpretability. What units of analysis should you use if you know what you’re looking for? If you *don’t* know what you’re looking for?
October 1, 2025 at 2:03 PM
One of the bigger changes was establishing criteria for success in interpretability. What units of analysis should you use if you know what you’re looking for? If you *don’t* know what you’re looking for?
We still have a lot to learn in editing NN representations.
To edit or steer, we cannot simply choose semantically relevant representations; we must choose the ones that will have the intended impact. As @peterbhase.bsky.social found, these are often distinct.
To edit or steer, we cannot simply choose semantically relevant representations; we must choose the ones that will have the intended impact. As @peterbhase.bsky.social found, these are often distinct.
May 27, 2025 at 5:07 PM
We still have a lot to learn in editing NN representations.
To edit or steer, we cannot simply choose semantically relevant representations; we must choose the ones that will have the intended impact. As @peterbhase.bsky.social found, these are often distinct.
To edit or steer, we cannot simply choose semantically relevant representations; we must choose the ones that will have the intended impact. As @peterbhase.bsky.social found, these are often distinct.
By limiting steering to output features, we recover >90% of the performance of the best supervised representation-based steering methods—and at some locations, we outperform them!
May 27, 2025 at 5:07 PM
By limiting steering to output features, we recover >90% of the performance of the best supervised representation-based steering methods—and at some locations, we outperform them!
We define the notion of an “output feature”, whose role is to increase p(some token(s)). Steering these gives better results than steering “input features”, whose role is to attend to concepts in the input. We propose fast methods to sort features into these categories.
May 27, 2025 at 5:07 PM
We define the notion of an “output feature”, whose role is to increase p(some token(s)). Steering these gives better results than steering “input features”, whose role is to attend to concepts in the input. We propose fast methods to sort features into these categories.
Reposted by Aaron Mueller

Couldn’t be happier to have co-authored this will a stellar team, including: Michael Hu, @amuuueller.bsky.social, @alexwarstadt.bsky.social, @lchoshen.bsky.social, Chengxu Zhuang, @adinawilliams.bsky.social, Ryan Cotterell, @tallinzen.bsky.social
May 12, 2025 at 3:48 PM
Couldn’t be happier to have co-authored this will a stellar team, including: Michael Hu, @amuuueller.bsky.social, @alexwarstadt.bsky.social, @lchoshen.bsky.social, Chengxu Zhuang, @adinawilliams.bsky.social, Ryan Cotterell, @tallinzen.bsky.social
... Jing Huang, Rohan Gupta, Yaniv Nikankin, @hadasorgad.bsky.social, Nikhil Prakash, @anja.re, Aruna Sankaranarayanan, Shun Shao, @alestolfo.bsky.social, @mtutek.bsky.social, @amirzur, @davidbau.bsky.social, and @boknilev.bsky.social!
April 23, 2025 at 6:15 PM
... Jing Huang, Rohan Gupta, Yaniv Nikankin, @hadasorgad.bsky.social, Nikhil Prakash, @anja.re, Aruna Sankaranarayanan, Shun Shao, @alestolfo.bsky.social, @mtutek.bsky.social, @amirzur, @davidbau.bsky.social, and @boknilev.bsky.social!
This was a huge collaboration with many great folks! If you get a chance, be sure to talk to Atticus Geiger, @sarah-nlp.bsky.social, @danaarad.bsky.social, Iván Arcuschin, @adambelfki.bsky.social, @yiksiu.bsky.social, Jaden Fiotto-Kaufmann, @talhaklay.bsky.social, @michaelwhanna.bsky.social, ...
April 23, 2025 at 6:15 PM
This was a huge collaboration with many great folks! If you get a chance, be sure to talk to Atticus Geiger, @sarah-nlp.bsky.social, @danaarad.bsky.social, Iván Arcuschin, @adambelfki.bsky.social, @yiksiu.bsky.social, Jaden Fiotto-Kaufmann, @talhaklay.bsky.social, @michaelwhanna.bsky.social, ...
We’re eager to establish MIB as a meaningful and lasting standard for comparing the quality of MI methods. If you’ll be at #ICLR2025 or #NAACL2025, please reach out to chat!
📜 arxiv.org/abs/2504.13151
📜 arxiv.org/abs/2504.13151

MIB: A Mechanistic Interpretability Benchmark
How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spann...
arxiv.org
April 23, 2025 at 6:15 PM
We’re eager to establish MIB as a meaningful and lasting standard for comparing the quality of MI methods. If you’ll be at #ICLR2025 or #NAACL2025, please reach out to chat!
📜 arxiv.org/abs/2504.13151
📜 arxiv.org/abs/2504.13151
We release many public resources, including:
🌐 Website: mib-bench.github.io
📄 Data: huggingface.co/collections/...
💻 Code: github.com/aaronmueller...
📊 Leaderboard: Coming very soon!
🌐 Website: mib-bench.github.io
📄 Data: huggingface.co/collections/...
💻 Code: github.com/aaronmueller...
📊 Leaderboard: Coming very soon!
MIB – Project Page
mib-bench.github.io
April 23, 2025 at 6:15 PM
We release many public resources, including:
🌐 Website: mib-bench.github.io
📄 Data: huggingface.co/collections/...
💻 Code: github.com/aaronmueller...
📊 Leaderboard: Coming very soon!
🌐 Website: mib-bench.github.io
📄 Data: huggingface.co/collections/...
💻 Code: github.com/aaronmueller...
📊 Leaderboard: Coming very soon!
These results highlight that there has been real progress in the field! We also recovered known findings, like that integrated gradients improves attribution quality. This is a sanity check verifying that our benchmark is capturing something real.
April 23, 2025 at 6:15 PM
These results highlight that there has been real progress in the field! We also recovered known findings, like that integrated gradients improves attribution quality. This is a sanity check verifying that our benchmark is capturing something real.
We find that supervised methods like DAS significantly outperform methods like sparse autoencoders or principal component analysis. Mask-learning methods also perform well, but not as well as DAS.
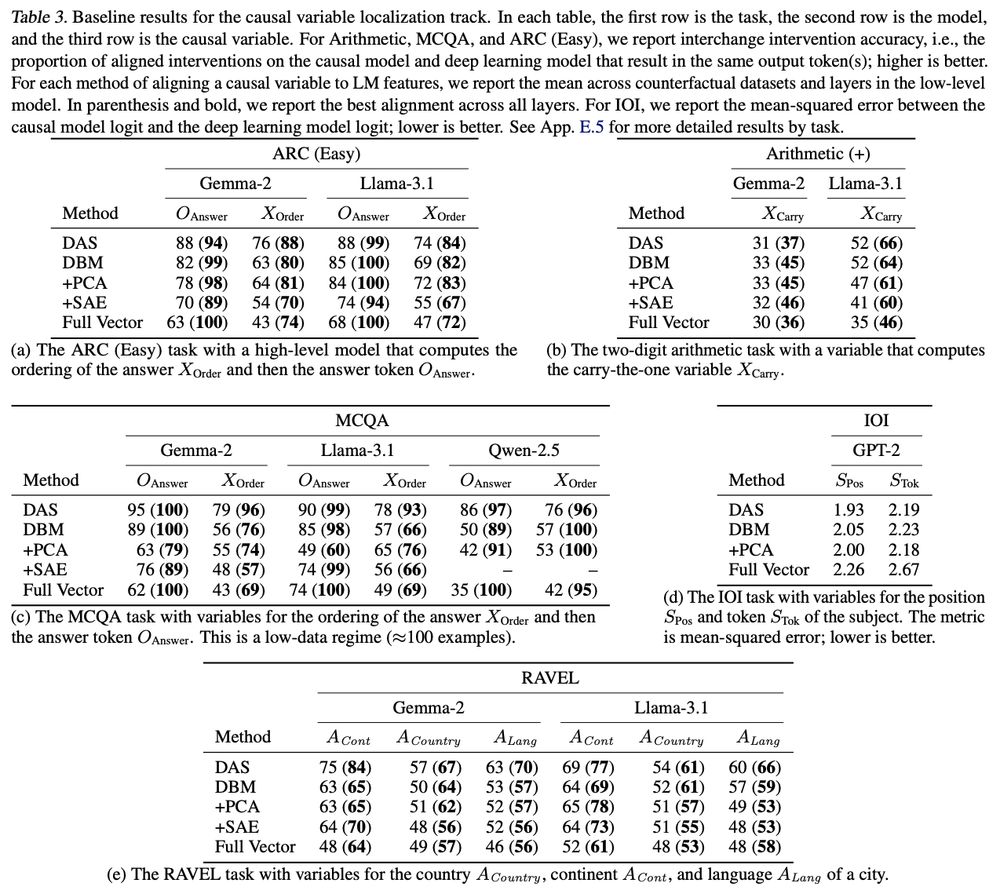
April 23, 2025 at 6:15 PM
We find that supervised methods like DAS significantly outperform methods like sparse autoencoders or principal component analysis. Mask-learning methods also perform well, but not as well as DAS.
This is evaluated using the interchange intervention accuracy (IIA): we featurize the activations, intervene on the specific causal variable, and see whether the intervention has the expected effect on model behavior.
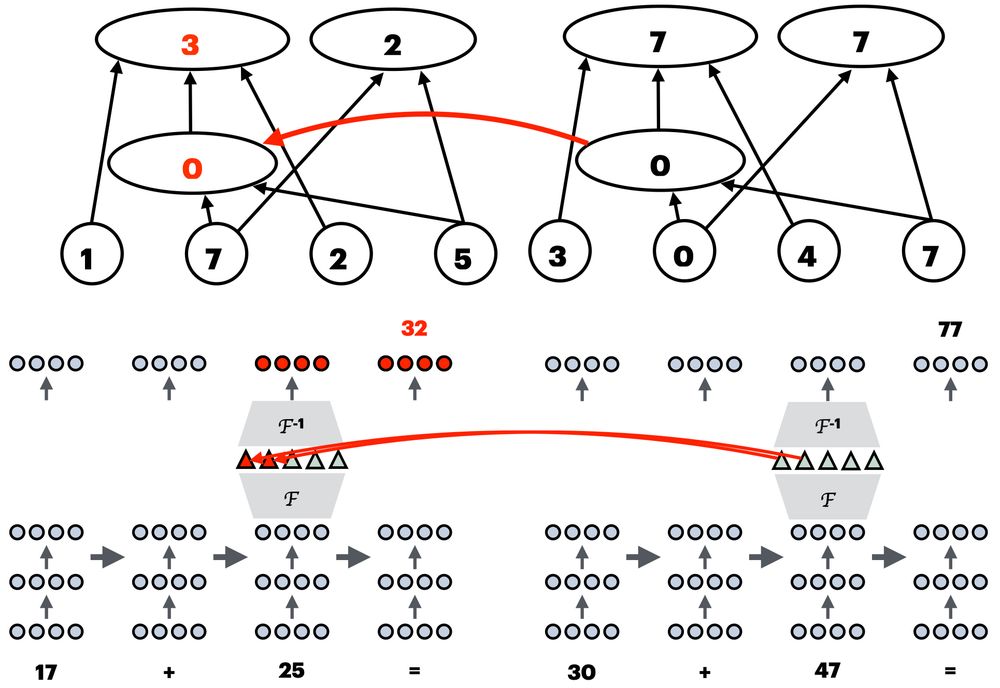
April 23, 2025 at 6:15 PM
This is evaluated using the interchange intervention accuracy (IIA): we featurize the activations, intervene on the specific causal variable, and see whether the intervention has the expected effect on model behavior.
The causal variable localization track measures the quality of featurization methods (like DAS, SAEs, etc.). How well can we decompose activations into more meaningful units, and intervene selectively on just the target variable?
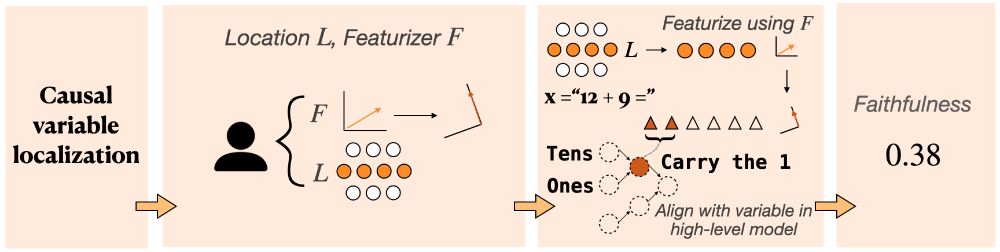
April 23, 2025 at 6:15 PM
The causal variable localization track measures the quality of featurization methods (like DAS, SAEs, etc.). How well can we decompose activations into more meaningful units, and intervene selectively on just the target variable?
We find that edge-level methods generally outperform node-level methods, that attribution patching with integrated gradients generally outperforms other methods (including more exact methods!), and that mask-learning methods perform well.
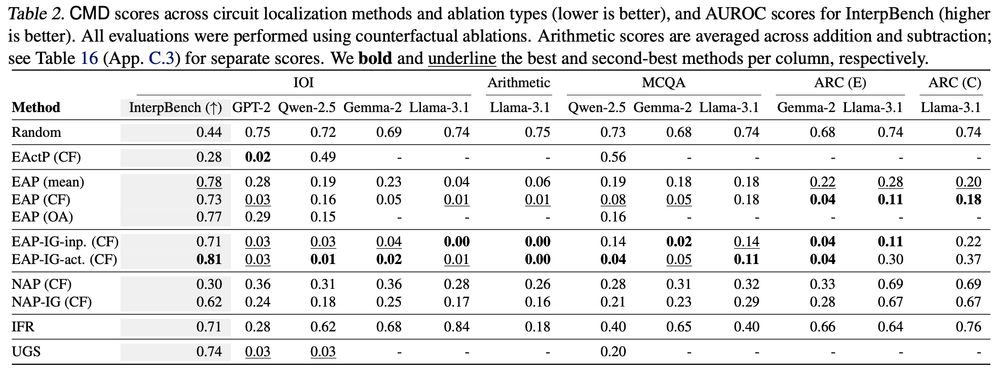
April 23, 2025 at 6:15 PM
We find that edge-level methods generally outperform node-level methods, that attribution patching with integrated gradients generally outperforms other methods (including more exact methods!), and that mask-learning methods perform well.