



Aaron Mueller
@amuuueller.bsky.social
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
We also made the causal graph formalism more precise. Interpretability and causality are intimately linked; the latter makes the former more trustworthy and rigorous. This formal link should be strengthened in future work.

October 1, 2025 at 2:03 PM
We also made the causal graph formalism more precise. Interpretability and causality are intimately linked; the latter makes the former more trustworthy and rigorous. This formal link should be strengthened in future work.
What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!

October 1, 2025 at 2:03 PM
What's the right unit of analysis for understanding LLM internals? We explore in our mech interp survey (a major update from our 2024 ms).
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
We’ve added more recent work and more immediately actionable directions for future work. Now published in Computational Linguistics!
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!

July 17, 2025 at 5:45 PM
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
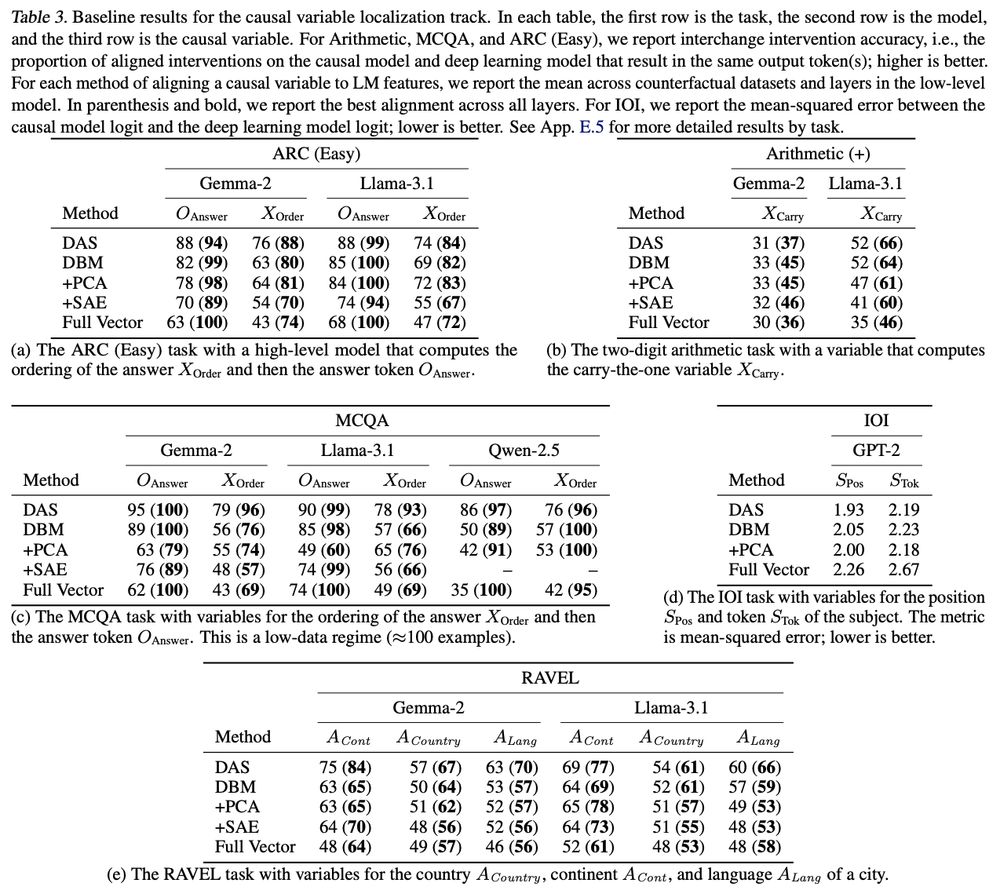
We find that supervised methods like DAS significantly outperform methods like sparse autoencoders or principal component analysis. Mask-learning methods also perform well, but not as well as DAS.
April 23, 2025 at 6:15 PM
We find that supervised methods like DAS significantly outperform methods like sparse autoencoders or principal component analysis. Mask-learning methods also perform well, but not as well as DAS.
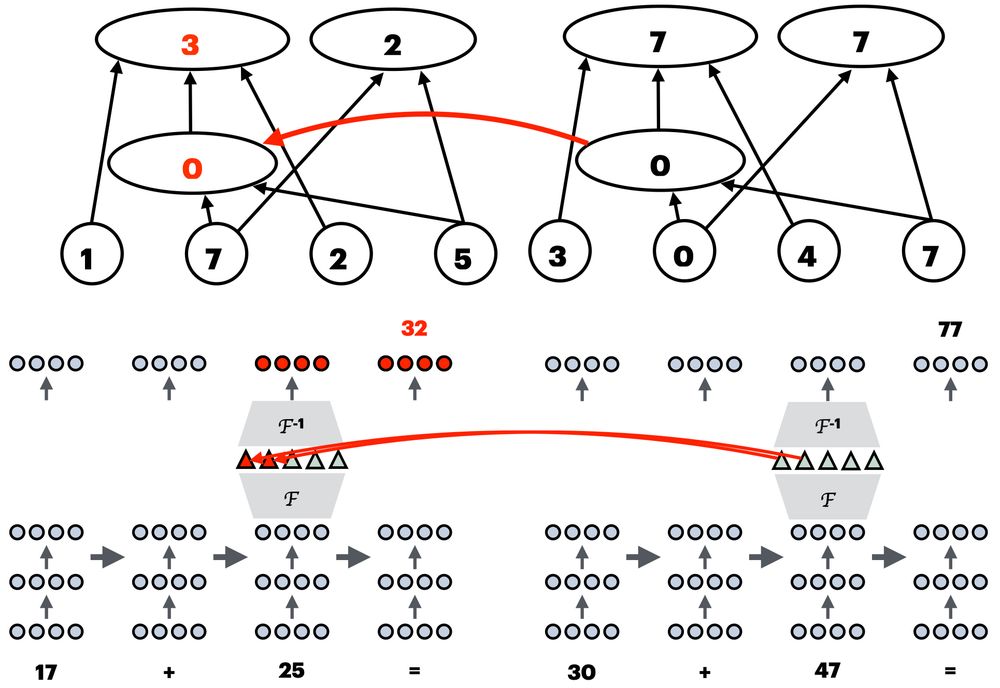
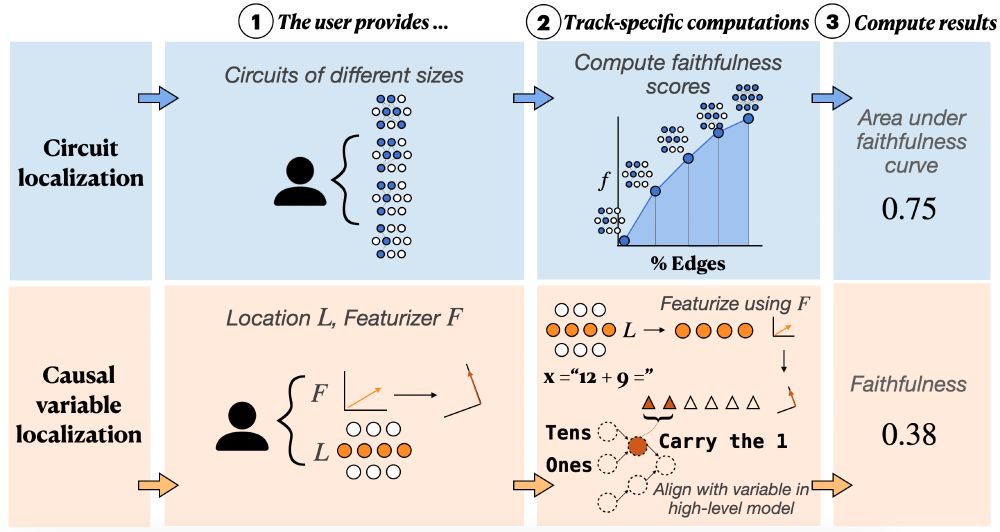
This is evaluated using the interchange intervention accuracy (IIA): we featurize the activations, intervene on the specific causal variable, and see whether the intervention has the expected effect on model behavior.
April 23, 2025 at 6:15 PM
This is evaluated using the interchange intervention accuracy (IIA): we featurize the activations, intervene on the specific causal variable, and see whether the intervention has the expected effect on model behavior.
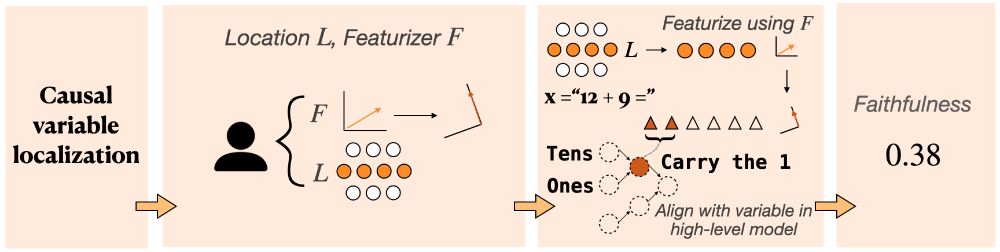
The causal variable localization track measures the quality of featurization methods (like DAS, SAEs, etc.). How well can we decompose activations into more meaningful units, and intervene selectively on just the target variable?
April 23, 2025 at 6:15 PM
The causal variable localization track measures the quality of featurization methods (like DAS, SAEs, etc.). How well can we decompose activations into more meaningful units, and intervene selectively on just the target variable?
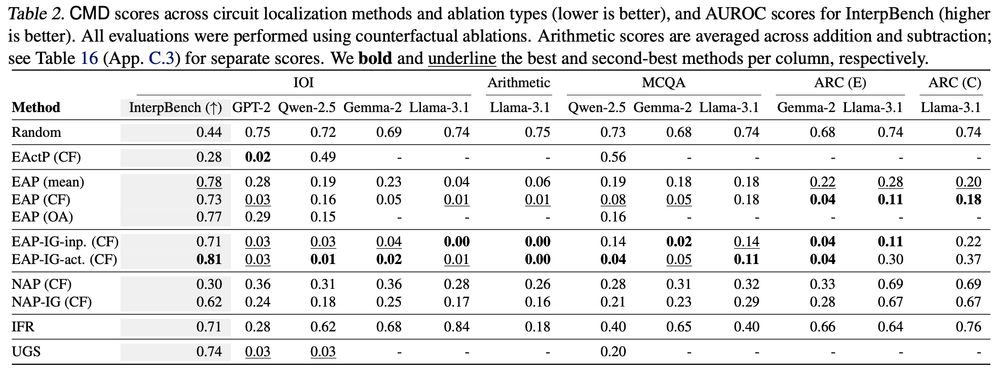
We find that edge-level methods generally outperform node-level methods, that attribution patching with integrated gradients generally outperforms other methods (including more exact methods!), and that mask-learning methods perform well.
April 23, 2025 at 6:15 PM
We find that edge-level methods generally outperform node-level methods, that attribution patching with integrated gradients generally outperforms other methods (including more exact methods!), and that mask-learning methods perform well.
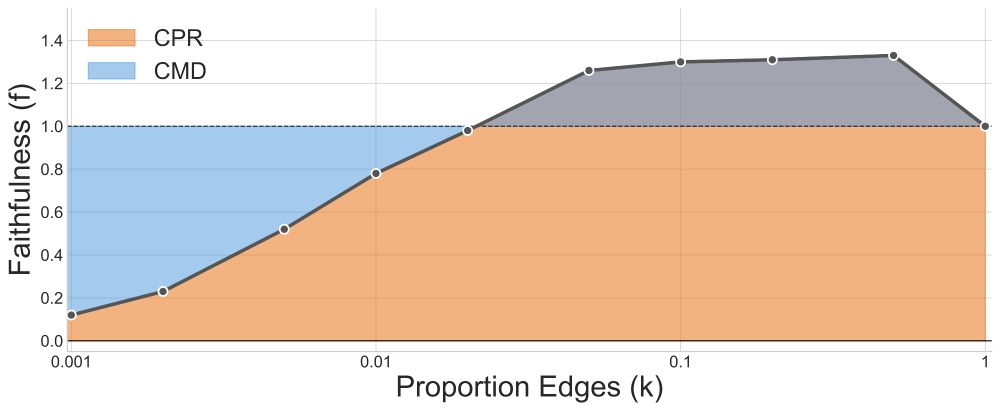
Thus, we split 𝘧 into two metrics: the integrated 𝗰𝗶𝗿𝗰𝘂𝗶𝘁 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗿𝗮𝘁𝗶𝗼 (CPR), and the integrated 𝗰𝗶𝗿𝗰𝘂𝗶𝘁–𝗺𝗼𝗱𝗲𝗹 𝗱𝗶𝘀𝘁𝗮𝗻𝗰𝗲 (CMD). Both involve integrating 𝘧 across many circuit sizes. This implicitly captures 𝗳𝗮𝗶𝘁𝗵𝗳𝘂𝗹𝗻𝗲𝘀𝘀 and 𝗺𝗶𝗻𝗶𝗺𝗮𝗹𝗶𝘁𝘆 at the same time!
April 23, 2025 at 6:15 PM
Thus, we split 𝘧 into two metrics: the integrated 𝗰𝗶𝗿𝗰𝘂𝗶𝘁 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗿𝗮𝘁𝗶𝗼 (CPR), and the integrated 𝗰𝗶𝗿𝗰𝘂𝗶𝘁–𝗺𝗼𝗱𝗲𝗹 𝗱𝗶𝘀𝘁𝗮𝗻𝗰𝗲 (CMD). Both involve integrating 𝘧 across many circuit sizes. This implicitly captures 𝗳𝗮𝗶𝘁𝗵𝗳𝘂𝗹𝗻𝗲𝘀𝘀 and 𝗺𝗶𝗻𝗶𝗺𝗮𝗹𝗶𝘁𝘆 at the same time!
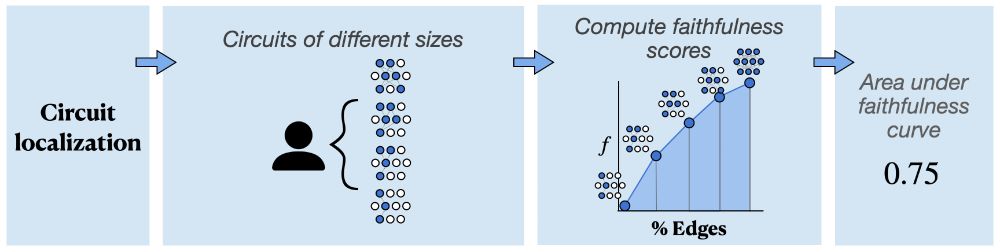
The circuit localization track compares causal graph localization methods. Faithfulness (𝘧) is a common way to evaluate a single circuit, but it’s used for two distinct Qs: (1) Does the circuit perform well? (2) Does the circuit match the model’s behavior?
April 23, 2025 at 6:15 PM
The circuit localization track compares causal graph localization methods. Faithfulness (𝘧) is a common way to evaluate a single circuit, but it’s used for two distinct Qs: (1) Does the circuit perform well? (2) Does the circuit match the model’s behavior?
Our data includes tasks of varying difficulties, including some that have never been mechanistically analyzed. We also include models of varying capabilities. We release our data, including counterfactual input pairs.
April 23, 2025 at 6:15 PM
Our data includes tasks of varying difficulties, including some that have never been mechanistically analyzed. We also include models of varying capabilities. We release our data, including counterfactual input pairs.
What should a mech interp benchmark evaluate? We think there are two fundamental paradigms: 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 and 𝗳𝗲𝗮𝘁𝘂𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻. We propose one track each: 𝗰𝗶𝗿𝗰𝘂𝗶𝘁 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 and 𝗰𝗮𝘂𝘀𝗮𝗹 𝘃𝗮𝗿𝗶𝗮𝗯𝗹𝗲 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
April 23, 2025 at 6:15 PM
What should a mech interp benchmark evaluate? We think there are two fundamental paradigms: 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 and 𝗳𝗲𝗮𝘁𝘂𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻. We propose one track each: 𝗰𝗶𝗿𝗰𝘂𝗶𝘁 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 and 𝗰𝗮𝘂𝘀𝗮𝗹 𝘃𝗮𝗿𝗶𝗮𝗯𝗹𝗲 𝗹𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻.
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!

April 23, 2025 at 6:15 PM
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!