



Vaishnavh Nagarajan
@vaishnavh.bsky.social
Foundations of AI. I like simple and minimal examples and creative ideas. I also like thinking about the next token 🧮🧸
Google Research | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
Google Research | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
Reposted by Vaishnavh Nagarajan

Congratulations to CSD faculty Aditi Raghunathan and her research collaborators on receiving an ICML Outstanding Paper award for Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction (icml.cc/virtual/2025...).
Paper: arxiv.org/abs/2504.15266
Paper: arxiv.org/abs/2504.15266
ICML 2025 AwardsICML 2025
icml.cc
July 17, 2025 at 2:43 PM
Congratulations to CSD faculty Aditi Raghunathan and her research collaborators on receiving an ICML Outstanding Paper award for Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction (icml.cc/virtual/2025...).
Paper: arxiv.org/abs/2504.15266
Paper: arxiv.org/abs/2504.15266
Reposted by Vaishnavh Nagarajan

Reading the dedications of a PhD thesis is often a cure for a bad day. There’s so much affection in them
July 3, 2025 at 11:05 PM
Reading the dedications of a PhD thesis is often a cure for a bad day. There’s so much affection in them
Reposted by Vaishnavh Nagarajan

As NeurIPS review deadline is around the corner, please remember that you cannot use any non-local LLM like chatgpt/gemini for understanding the paper and drafting/revising your review as that breaks the confidentiality agreement.
NeurIPS 2025 Official LLM Policy:
neurips.cc/Conferences/...
NeurIPS 2025 Official LLM Policy:
neurips.cc/Conferences/...
LLM Policy
neurips.cc
July 2, 2025 at 12:44 PM
As NeurIPS review deadline is around the corner, please remember that you cannot use any non-local LLM like chatgpt/gemini for understanding the paper and drafting/revising your review as that breaks the confidentiality agreement.
NeurIPS 2025 Official LLM Policy:
neurips.cc/Conferences/...
NeurIPS 2025 Official LLM Policy:
neurips.cc/Conferences/...
Reposted by Vaishnavh Nagarajan

I really enjoyed "When We Cease to Understand the World", although it's more fiction than history of science
June 22, 2025 at 2:30 PM
I really enjoyed "When We Cease to Understand the World", although it's more fiction than history of science
Reposted by Vaishnavh Nagarajan

“Science in history” by Bernal is my first recommendation. The work of Ian Hacking is a good recommendation for
Probability
Probability
June 23, 2025 at 2:12 AM
“Science in history” by Bernal is my first recommendation. The work of Ian Hacking is a good recommendation for
Probability
Probability
Reposted by Vaishnavh Nagarajan

How do task dynamics impact learning in networks with internal dynamics?
Excited to share our ICML Oral paper on learning dynamics in linear RNNs!
with @clementinedomine.bsky.social @mpshanahan.bsky.social and Pedro Mediano
openreview.net/forum?id=KGO...
Excited to share our ICML Oral paper on learning dynamics in linear RNNs!
with @clementinedomine.bsky.social @mpshanahan.bsky.social and Pedro Mediano
openreview.net/forum?id=KGO...
Learning dynamics in linear recurrent neural networks
Recurrent neural networks (RNNs) are powerful models used widely in both machine learning and neuroscience to learn tasks with temporal dependencies and to model neural dynamics. However, despite...
openreview.net
June 20, 2025 at 5:29 PM
How do task dynamics impact learning in networks with internal dynamics?
Excited to share our ICML Oral paper on learning dynamics in linear RNNs!
with @clementinedomine.bsky.social @mpshanahan.bsky.social and Pedro Mediano
openreview.net/forum?id=KGO...
Excited to share our ICML Oral paper on learning dynamics in linear RNNs!
with @clementinedomine.bsky.social @mpshanahan.bsky.social and Pedro Mediano
openreview.net/forum?id=KGO...
Reposted by Vaishnavh Nagarajan
When we are doing science, we are unknowingly executing our mythology, taken from movies and friends and textbooks, of what science is. History of science helps us ground that myth in reality
I finally wrote a full-fledged blog about this: reading the history of science is an **amazing** yet under-recognized way to develop (emotional) maturity as a researcher.
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
June 21, 2025 at 11:04 PM
When we are doing science, we are unknowingly executing our mythology, taken from movies and friends and textbooks, of what science is. History of science helps us ground that myth in reality
I finally wrote a full-fledged blog about this: reading the history of science is an **amazing** yet under-recognized way to develop (emotional) maturity as a researcher.
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
June 12, 2025 at 11:45 PM
I finally wrote a full-fledged blog about this: reading the history of science is an **amazing** yet under-recognized way to develop (emotional) maturity as a researcher.
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
If you have thoughts/recommendations, please share!
vaishnavh.github.io/2025/04/29/h...
Reposted by Vaishnavh Nagarajan

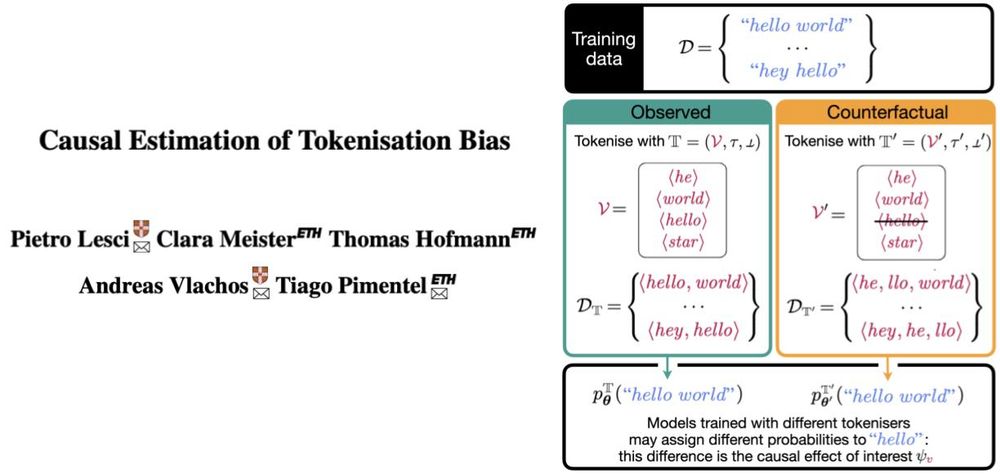
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
June 4, 2025 at 10:51 AM
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
Reposted by Vaishnavh Nagarajan

How does in-context learning emerge in attention models during gradient descent training?
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
June 4, 2025 at 11:22 AM
How does in-context learning emerge in attention models during gradient descent training?
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
Sharing our new Spotlight paper @icmlconf.bsky.social: Training Dynamics of In-Context Learning in Linear Attention
arxiv.org/abs/2501.16265
Led by Yedi Zhang with @aaditya6284.bsky.social and Peter Latham
Reposted by Vaishnavh Nagarajan
This paper is quite nice. It mixes some useful toy models of creativity with insights about how to induce more creativity in LLMs that are better than greedy sampling
June 2, 2025 at 9:31 PM
This paper is quite nice. It mixes some useful toy models of creativity with insights about how to induce more creativity in LLMs that are better than greedy sampling
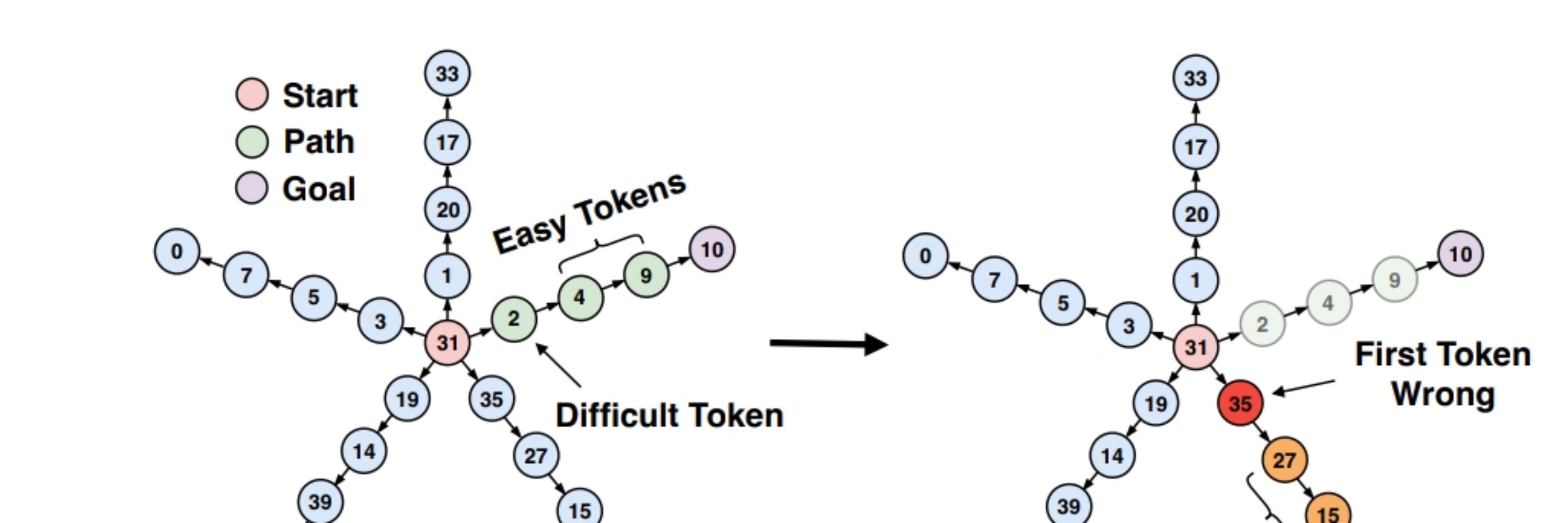
📢 New #paper on creativity & multi-token prediction! We design minimal open-ended tasks to argue:
→ LLMs are limited in creativity as they learn to predict the next token
→ creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ #MLSky #AI #arxiv 🧵👇🏽
→ LLMs are limited in creativity as they learn to predict the next token
→ creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ #MLSky #AI #arxiv 🧵👇🏽

June 2, 2025 at 5:26 PM
Reposted by Vaishnavh Nagarajan

This isn't fake news. One of the craziest AI research papers I've been on in a while. Weird ablations on RLVR shows that the Qwen 2.5 models can learn with literally random rewards, likely due to some funkiness in mid-training and the GRPO setup.

May 27, 2025 at 4:49 PM
This isn't fake news. One of the craziest AI research papers I've been on in a while. Weird ablations on RLVR shows that the Qwen 2.5 models can learn with literally random rewards, likely due to some funkiness in mid-training and the GRPO setup.
can someone reconcile these two contradictory findings?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!



May 27, 2025 at 3:53 PM
can someone reconcile these two contradictory findings?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
Reposted by Vaishnavh Nagarajan

🚨 New Paper!
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n

May 21, 2025 at 12:07 AM
🚨 New Paper!
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
The contextual shadowing effect in this paper is interesting & reminds me of the infamous "cow-in-a-beach" spurious correlation examples. The model needs to learn a core feature (here. the store-in-memory feature) but it instead relies on a simpler "spurious" feature (the in-context feature).
⚠️⚠️ But here comes drama!!!
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
What if the news appears in the context upstream of the *same* FT data?
🚨 Contextual Shadowing happens!
Prefixing the news during FT *catastrophically* reduces learning!
10/n
May 21, 2025 at 12:50 AM
The contextual shadowing effect in this paper is interesting & reminds me of the infamous "cow-in-a-beach" spurious correlation examples. The model needs to learn a core feature (here. the store-in-memory feature) but it instead relies on a simpler "spurious" feature (the in-context feature).
My #neurips bidding pool is REALLY bad and I see that I'm not alone. Was the pool restricted to 100 papers to break collusion? if so, seems like everyone else is going to pay for this
May 18, 2025 at 1:07 PM
My #neurips bidding pool is REALLY bad and I see that I'm not alone. Was the pool restricted to 100 papers to break collusion? if so, seems like everyone else is going to pay for this
looks like a fun workshop!

What if there were a workshop dedicated to *small-scale*, *reproducible* experiments? What if this were at ICML 2025? What if your submission (due May 22nd) could literally be a Jupyter notebook?? Pretty excited this is happening. Spread the word! sites.google.com/view/moss202...

May 8, 2025 at 2:46 PM
looks like a fun workshop!
Reposted by Vaishnavh Nagarajan
Excited that our paper "safety alignment should be made more than just a few tokens deep" was recognized as an #ICLR2025 Outstanding Paper!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
April 23, 2025 at 10:22 PM
Excited that our paper "safety alignment should be made more than just a few tokens deep" was recognized as an #ICLR2025 Outstanding Paper!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
We identified a common root cause to many safety vulnerabilities and pointed out some paths forward to address it!
Reposted by Vaishnavh Nagarajan

At the moment, we just show you posts by people you follow. Following someone will make their paper posts appear! In the future, we'll expand this (slightly) to show you other paper posts that may be of interest
May 7, 2025 at 3:59 PM
At the moment, we just show you posts by people you follow. Following someone will make their paper posts appear! In the future, we'll expand this (slightly) to show you other paper posts that may be of interest
Reposted by Vaishnavh Nagarajan

Yeah this is actual unironic advice for any 1st years: you seriously need to go get beers or otherwise hangout socially with more senior grad students (no one else will really know) and hopefully get ensconced enough that someone will tell you “hey just fyi Dr. GoodPubs is low-key a total sociopath”
It’s another way nepotism manifests? You really can’t know who would be a good or bad advisor other than rumors. If you have parents in academia, they can help you sift through the rumors
May 5, 2025 at 3:52 AM
Yeah this is actual unironic advice for any 1st years: you seriously need to go get beers or otherwise hangout socially with more senior grad students (no one else will really know) and hopefully get ensconced enough that someone will tell you “hey just fyi Dr. GoodPubs is low-key a total sociopath”
Reposted by Vaishnavh Nagarajan
@vaishnavh.bsky.social and crew do it again:
- a benchmark for open-ended creativity
- a demonstration of challenges of next-token prediction
- a technique to improve transformer randomness through inputs not sampling
arxiv.org/abs/2504.15266
- a benchmark for open-ended creativity
- a demonstration of challenges of next-token prediction
- a technique to improve transformer randomness through inputs not sampling
arxiv.org/abs/2504.15266

Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
We design a suite of minimal algorithmic tasks that are a loose abstraction of open-ended real-world tasks. This allows us to cleanly and controllably quantify the creative limits of the present-day l...
arxiv.org
May 5, 2025 at 11:23 PM
@vaishnavh.bsky.social and crew do it again:
- a benchmark for open-ended creativity
- a demonstration of challenges of next-token prediction
- a technique to improve transformer randomness through inputs not sampling
arxiv.org/abs/2504.15266
- a benchmark for open-ended creativity
- a demonstration of challenges of next-token prediction
- a technique to improve transformer randomness through inputs not sampling
arxiv.org/abs/2504.15266
@icmlconf.bsky.social (assuming this is the legit ICML account), the Canadian visa application requires providing the inviting contact to have a Canadian address. But the one in the visa letter is a US address. Could you look into this?
May 6, 2025 at 1:17 PM
@icmlconf.bsky.social (assuming this is the legit ICML account), the Canadian visa application requires providing the inviting contact to have a Canadian address. But the one in the visa letter is a US address. Could you look into this?
Reposted by Vaishnavh Nagarajan
If you are at #AISTATS2025 and are interested in concept erasure, talk to @somnathbrc.bsky.social at Poster Session 1 on Saturday May 3.

May 3, 2025 at 12:47 AM
If you are at #AISTATS2025 and are interested in concept erasure, talk to @somnathbrc.bsky.social at Poster Session 1 on Saturday May 3.
Reposted by Vaishnavh Nagarajan

Responsible reviewing initiatives for NeurIPS 2025 - read more about changes to reviewing that that will safeguard reviewing quality and timeline in our blog post below:
blog.neurips.cc/2025/05/02/r...
blog.neurips.cc/2025/05/02/r...

Responsible Reviewing Initiative for NeurIPS 2025 – NeurIPS Blog
Communications Chairs 2025 2021 Conference
blog.neurips.cc
May 2, 2025 at 10:45 PM
Responsible reviewing initiatives for NeurIPS 2025 - read more about changes to reviewing that that will safeguard reviewing quality and timeline in our blog post below:
blog.neurips.cc/2025/05/02/r...
blog.neurips.cc/2025/05/02/r...