



Vaishnavh Nagarajan
@vaishnavh.bsky.social
Foundations of AI. I like simple and minimal examples and creative ideas. I also like thinking about the next token 🧮🧸
Google Research | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
Google Research | PhD, CMU |
https://arxiv.org/abs/2504.15266 | https://arxiv.org/abs/2403.06963
vaishnavh.github.io
Our vision is that seed-conditioning can help models sample a latent thought and articulate that one thought into words,
but temp sampling has to articulate multiple latent thoughts in parallel to produce a marginal next-word distribution -- this is more burdensome! 8/👇🏽
but temp sampling has to articulate multiple latent thoughts in parallel to produce a marginal next-word distribution -- this is more burdensome! 8/👇🏽

June 2, 2025 at 5:26 PM
Our vision is that seed-conditioning can help models sample a latent thought and articulate that one thought into words,
but temp sampling has to articulate multiple latent thoughts in parallel to produce a marginal next-word distribution -- this is more burdensome! 8/👇🏽
but temp sampling has to articulate multiple latent thoughts in parallel to produce a marginal next-word distribution -- this is more burdensome! 8/👇🏽
Next, we revisit how to produce randomness: the go-to temp sampling 🌡️ vs. injecting a random prefix (seed-conditioning). 🌱
Remarkably, seed-conditioning produces meaningful diversity even w *greedy* decoding 🤑; it is competitive with temp & in some conditions, superior. 7/👇🏽
Remarkably, seed-conditioning produces meaningful diversity even w *greedy* decoding 🤑; it is competitive with temp & in some conditions, superior. 7/👇🏽


June 2, 2025 at 5:26 PM
Next, we revisit how to produce randomness: the go-to temp sampling 🌡️ vs. injecting a random prefix (seed-conditioning). 🌱
Remarkably, seed-conditioning produces meaningful diversity even w *greedy* decoding 🤑; it is competitive with temp & in some conditions, superior. 7/👇🏽
Remarkably, seed-conditioning produces meaningful diversity even w *greedy* decoding 🤑; it is competitive with temp & in some conditions, superior. 7/👇🏽

On these tasks, we can objectively evaluate how “creative” (correct, diverse & original) a model is. 🧑🏽🔬
First: Next-token-trained models are largely less creative & memorize much more than multi-token ones (we tried diffusion and teacherless training). 4/👇🏽
First: Next-token-trained models are largely less creative & memorize much more than multi-token ones (we tried diffusion and teacherless training). 4/👇🏽


June 2, 2025 at 5:26 PM
On these tasks, we can objectively evaluate how “creative” (correct, diverse & original) a model is. 🧑🏽🔬
First: Next-token-trained models are largely less creative & memorize much more than multi-token ones (we tried diffusion and teacherless training). 4/👇🏽
First: Next-token-trained models are largely less creative & memorize much more than multi-token ones (we tried diffusion and teacherless training). 4/👇🏽
Our idea was to design minimal, open-ended, graph algorithmic tasks 🧮 abstracting 2 key modes of creativity:
1. Combinational: making surprising connections from memory, like in wordplay.🧠
2. Exploratory: devising fresh patterns obeying some rules, like in problem-design🧩 3/👇🏽
1. Combinational: making surprising connections from memory, like in wordplay.🧠
2. Exploratory: devising fresh patterns obeying some rules, like in problem-design🧩 3/👇🏽



June 2, 2025 at 5:26 PM
Our idea was to design minimal, open-ended, graph algorithmic tasks 🧮 abstracting 2 key modes of creativity:
1. Combinational: making surprising connections from memory, like in wordplay.🧠
2. Exploratory: devising fresh patterns obeying some rules, like in problem-design🧩 3/👇🏽
1. Combinational: making surprising connections from memory, like in wordplay.🧠
2. Exploratory: devising fresh patterns obeying some rules, like in problem-design🧩 3/👇🏽
As open-ended tasks like science/generating synthetic data become mainstream, we not only want correctness but also "creativity" (diversity & novelty)!
But how do we ✨cleanly✨ understand/improve LLMs on such subjective, unscalable, noisy metrics? 2/👇🏽
But how do we ✨cleanly✨ understand/improve LLMs on such subjective, unscalable, noisy metrics? 2/👇🏽

June 2, 2025 at 5:26 PM
As open-ended tasks like science/generating synthetic data become mainstream, we not only want correctness but also "creativity" (diversity & novelty)!
But how do we ✨cleanly✨ understand/improve LLMs on such subjective, unscalable, noisy metrics? 2/👇🏽
But how do we ✨cleanly✨ understand/improve LLMs on such subjective, unscalable, noisy metrics? 2/👇🏽
📢 New #paper on creativity & multi-token prediction! We design minimal open-ended tasks to argue:
→ LLMs are limited in creativity as they learn to predict the next token
→ creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ #MLSky #AI #arxiv 🧵👇🏽
→ LLMs are limited in creativity as they learn to predict the next token
→ creativity can be improved via multi-token learning & injecting noise ("seed-conditioning" 🌱) 1/ #MLSky #AI #arxiv 🧵👇🏽

June 2, 2025 at 5:26 PM
can someone reconcile these two contradictory findings?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!



May 27, 2025 at 3:53 PM
can someone reconcile these two contradictory findings?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
two papers find entropy *minimization*/confidence maximization helps performance,
and the RL-on-one-sample finds entropy maximization/increasing exploration alone helps performance?!
it got better but it's still very bad for me

May 19, 2025 at 2:35 PM
it got better but it's still very bad for me
fwiw, we did begin by crediting Shannon in our pitfalls of NTP paper! and it seems like we both know that Ben Recht discusses Shannon's NTP too www.argmin.net/p/patterns-p...

May 7, 2025 at 4:24 PM
fwiw, we did begin by crediting Shannon in our pitfalls of NTP paper! and it seems like we both know that Ben Recht discusses Shannon's NTP too www.argmin.net/p/patterns-p...
h/t @suhasia.bsky.social this paper suggests that the gap between offline and online cannot be explained by data coverage alone
arxiv.org/abs/2405.08448
arxiv.org/abs/2405.08448

December 13, 2024 at 8:41 PM
h/t @suhasia.bsky.social this paper suggests that the gap between offline and online cannot be explained by data coverage alone
arxiv.org/abs/2405.08448
arxiv.org/abs/2405.08448
to be clear, both shortcuts are a problem but I like to treat them separately bc they demand different solutions. more formally written essay in the screenshot below:

December 13, 2024 at 7:53 PM
to be clear, both shortcuts are a problem but I like to treat them separately bc they demand different solutions. more formally written essay in the screenshot below:
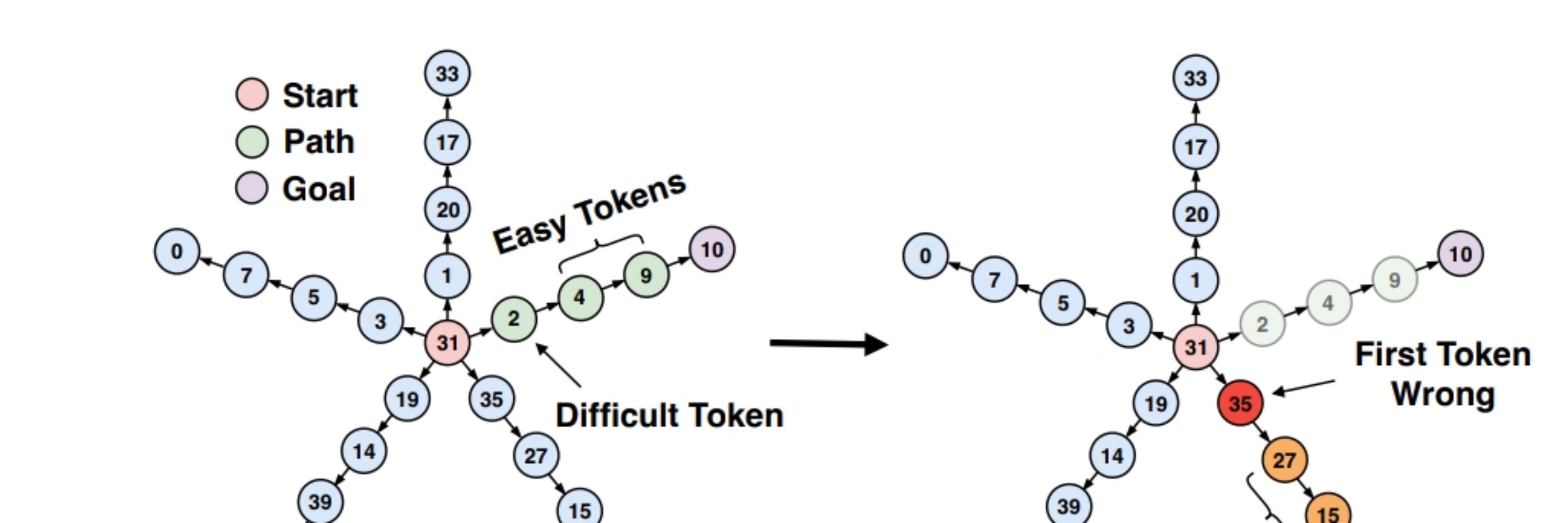
next-token shortcuts OTOH arise from the choice of next-token training; they've nothing to do with the x-y correlations in the distribution itself!
like in this path-star task or when you write a story, shortcuts arise simply from the way you order the tokens. arxiv.org/pdf/2403.06963
like in this path-star task or when you write a story, shortcuts arise simply from the way you order the tokens. arxiv.org/pdf/2403.06963

December 13, 2024 at 7:50 PM
next-token shortcuts OTOH arise from the choice of next-token training; they've nothing to do with the x-y correlations in the distribution itself!
like in this path-star task or when you write a story, shortcuts arise simply from the way you order the tokens. arxiv.org/pdf/2403.06963
like in this path-star task or when you write a story, shortcuts arise simply from the way you order the tokens. arxiv.org/pdf/2403.06963
they were giving out free samples at this shop, so I could learn how to make potions using probably approximately correct ingredients

December 1, 2024 at 1:41 AM
they were giving out free samples at this shop, so I could learn how to make potions using probably approximately correct ingredients
thought inspired in part by this book

November 30, 2024 at 6:50 PM
thought inspired in part by this book
hmm, finding it hard to convince myself that the optimum of this expression will be the at the 0-offensive-word solution esp if D in the expectation doesn't even contain it. (but now I think this is true even of the penalized RLHF, still wrapping my head around it)

November 22, 2024 at 8:24 PM
hmm, finding it hard to convince myself that the optimum of this expression will be the at the 0-offensive-word solution esp if D in the expectation doesn't even contain it. (but now I think this is true even of the penalized RLHF, still wrapping my head around it)
ok so, be it RLHF or DPO, this closed form indicates that for me to discover the zero-offensive-words policy, either (a) the base policy must assign non-trivial prob to those strings, OR (b) the KL penalty "beta" should be... zero. 🤔

November 22, 2024 at 6:24 PM
ok so, be it RLHF or DPO, this closed form indicates that for me to discover the zero-offensive-words policy, either (a) the base policy must assign non-trivial prob to those strings, OR (b) the KL penalty "beta" should be... zero. 🤔
same! I wonder if it's because I had the notif filter activated (see the footnote below)
November 22, 2024 at 3:23 AM
same! I wonder if it's because I had the notif filter activated (see the footnote below)
The slides are here, if you want to follow along or stare at pictures of horses.
vaishnavh.github.io/home/talks/n...
vaishnavh.github.io/home/talks/n...

November 20, 2024 at 6:51 PM
The slides are here, if you want to follow along or stare at pictures of horses.
vaishnavh.github.io/home/talks/n...
vaishnavh.github.io/home/talks/n...
bsky vibes right now:
(Artist: annalaura_art@ on Instagram)
(Artist: annalaura_art@ on Instagram)

November 19, 2024 at 9:13 PM
bsky vibes right now:
(Artist: annalaura_art@ on Instagram)
(Artist: annalaura_art@ on Instagram)
You might enjoy Cafe Grumpy, it's a chain of coffee shops in NYC cafegrumpy.com

November 18, 2024 at 5:10 PM
You might enjoy Cafe Grumpy, it's a chain of coffee shops in NYC cafegrumpy.com
to my disappointment, they argue that this problem plagues even the multi-token "teacherless training" in our pitfalls of NTP paper (arxiv.org/abs/2403.06963) /Monea et al., PaSS (arxiv.org/abs/2311.13581). i.e., even minimizing that loss does not guarantee a belief state in a stochastic setting :-(

November 13, 2024 at 11:15 PM
to my disappointment, they argue that this problem plagues even the multi-token "teacherless training" in our pitfalls of NTP paper (arxiv.org/abs/2403.06963) /Monea et al., PaSS (arxiv.org/abs/2311.13581). i.e., even minimizing that loss does not guarantee a belief state in a stochastic setting :-(
now they have a new algorithm but what I want to focus on is their elegant proof for why minimizing the next-token loss is NOT sufficient to guarantee a belief state.

November 13, 2024 at 11:15 PM
now they have a new algorithm but what I want to focus on is their elegant proof for why minimizing the next-token loss is NOT sufficient to guarantee a belief state.