



Pradeep Dasigi
@pdasigi.bsky.social
#NLP research @ai2.bsky.social; OLMo post-training
https://pdasigi.github.io/
https://pdasigi.github.io/
Pinned
Pradeep Dasigi
@pdasigi.bsky.social
· Nov 23
Super excited to release Tülu 3, a suite of open SoTA post-trained models, data, code, evaluation framework, and most importantly post-training recipes.
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
Reposted by Pradeep Dasigi

We’re updating olmOCR, our model for turning PDFs & scans into clean text with support for tables, equations, handwriting, & more. olmOCR 2 uses synthetic data + unit tests as verifiable rewards to reach state-of-the-art performance on challenging documents. 🧵

October 22, 2025 at 4:09 PM
We’re updating olmOCR, our model for turning PDFs & scans into clean text with support for tables, equations, handwriting, & more. olmOCR 2 uses synthetic data + unit tests as verifiable rewards to reach state-of-the-art performance on challenging documents. 🧵
Reposted by Pradeep Dasigi

Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!

March 13, 2025 at 7:19 PM
Introducing OLMo-2-0325-32B-Instruct! It's the spring RL curve time. This time, we used GRPO for RLVR and trained a pretty nice fully open source model!
Reposted by Pradeep Dasigi
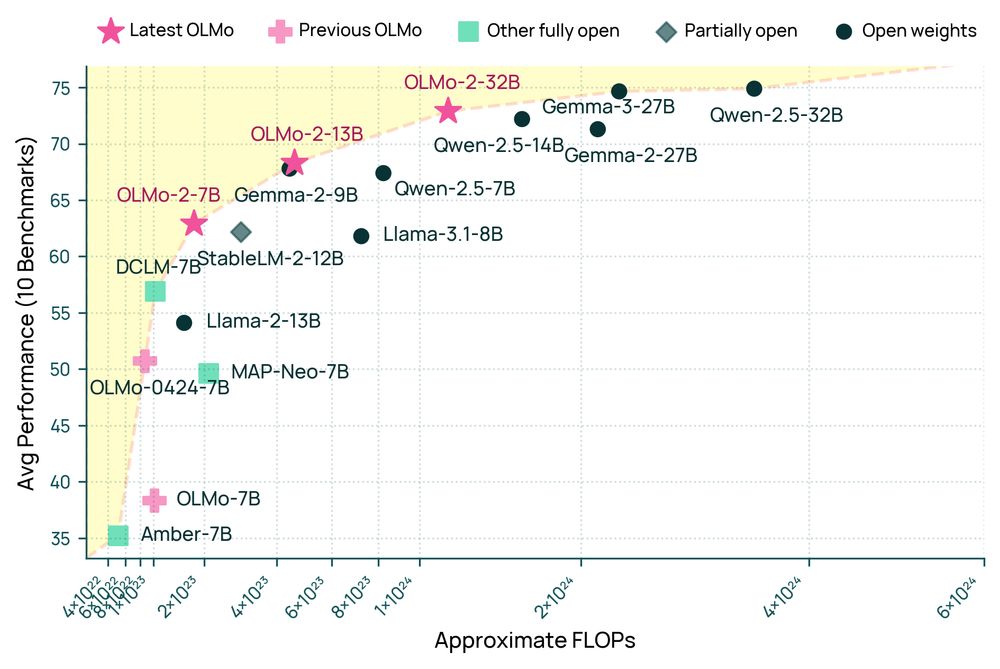
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
March 13, 2025 at 6:36 PM
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
How to curate instruction tuning datasets while targeting specific skills? This is a common question developers face while post-training LMs.
In this work led by @hamishivi.bsky.social we found that simple embedding based methods scale much better than fancier computationally intensive ones.
In this work led by @hamishivi.bsky.social we found that simple embedding based methods scale much better than fancier computationally intensive ones.
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)

March 4, 2025 at 7:20 PM
How to curate instruction tuning datasets while targeting specific skills? This is a common question developers face while post-training LMs.
In this work led by @hamishivi.bsky.social we found that simple embedding based methods scale much better than fancier computationally intensive ones.
In this work led by @hamishivi.bsky.social we found that simple embedding based methods scale much better than fancier computationally intensive ones.
Reposted by Pradeep Dasigi

also some other tülu contributors are on the market:
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
January 30, 2025 at 7:25 PM
also some other tülu contributors are on the market:
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
Here's a significant update to Tülu 3: we scaled up the post-training recipe to Llama 3.1 405B. Tülu 3 405B beats Llama's 405B instruct model and also Deepseek V3.
Huge shoutout to @hamishivi.bsky.social and @vwxyzjn.bsky.social who led the scale up, and to the rest of the team!
Huge shoutout to @hamishivi.bsky.social and @vwxyzjn.bsky.social who led the scale up, and to the rest of the team!
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.

January 30, 2025 at 7:21 PM
Here's a significant update to Tülu 3: we scaled up the post-training recipe to Llama 3.1 405B. Tülu 3 405B beats Llama's 405B instruct model and also Deepseek V3.
Huge shoutout to @hamishivi.bsky.social and @vwxyzjn.bsky.social who led the scale up, and to the rest of the team!
Huge shoutout to @hamishivi.bsky.social and @vwxyzjn.bsky.social who led the scale up, and to the rest of the team!
Reposted by Pradeep Dasigi

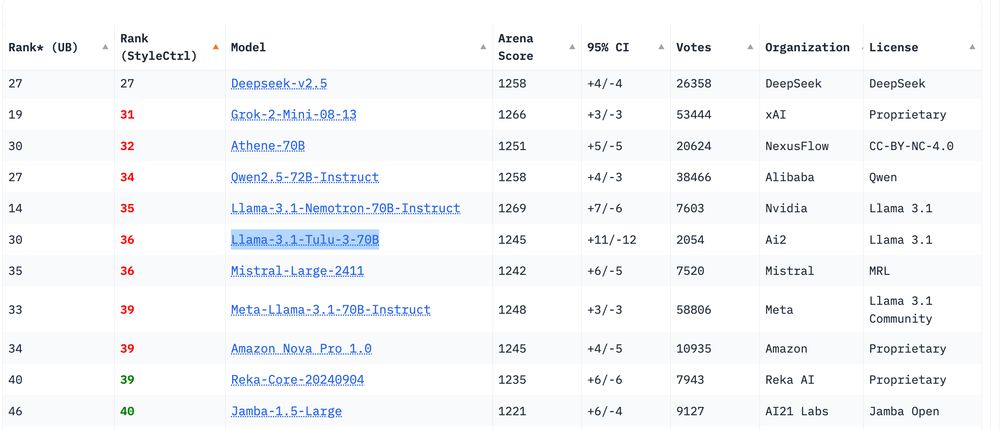
Very pleased to see Tulu 3 70B more or less tied with Llama 3.1 70B Instruct on style controlled ChatBotArena. The only model anywhere close to that with open code and data for post-training! Lots of stuff people can build on.
Next looking for OLMo 2 numbers.
Next looking for OLMo 2 numbers.
January 8, 2025 at 5:13 PM
Very pleased to see Tulu 3 70B more or less tied with Llama 3.1 70B Instruct on style controlled ChatBotArena. The only model anywhere close to that with open code and data for post-training! Lots of stuff people can build on.
Next looking for OLMo 2 numbers.
Next looking for OLMo 2 numbers.
Reposted by Pradeep Dasigi

Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124

January 8, 2025 at 5:47 PM
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Reposted by Pradeep Dasigi
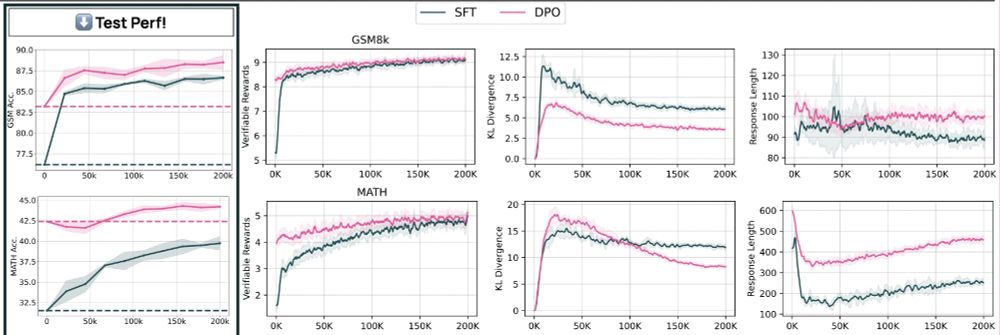
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
December 6, 2024 at 8:24 PM
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Our team at Ai2 (OLMo) is looking for a predoctoral researcher. You get to work on exciting research in building open LMs while preparing for a PhD.
Apply here: job-boards.greenhouse.io/thealleninst...
Apply here: job-boards.greenhouse.io/thealleninst...
Job Application for Predoctoral Young Investigator, OLMo at The Allen Institute for AI
job-boards.greenhouse.io
December 4, 2024 at 5:04 PM
Our team at Ai2 (OLMo) is looking for a predoctoral researcher. You get to work on exciting research in building open LMs while preparing for a PhD.
Apply here: job-boards.greenhouse.io/thealleninst...
Apply here: job-boards.greenhouse.io/thealleninst...
Reposted by Pradeep Dasigi

We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
GitHub - allenai/OLMo: Modeling, training, eval, and inference code for OLMo
Modeling, training, eval, and inference code for OLMo - allenai/OLMo
github.com
December 2, 2024 at 8:13 PM
We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
OLMo 2 is out! We released 7B and 13B models that are *fully open*, and compete with the best open-weight models out there.
Importantly, we use the same post-training recipe as our recently released Tülu 3, and it works remarkably well, more so at the 13B size.
Importantly, we use the same post-training recipe as our recently released Tülu 3, and it works remarkably well, more so at the 13B size.
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
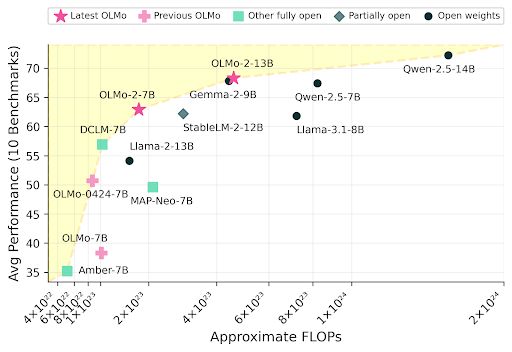
November 26, 2024 at 9:28 PM
OLMo 2 is out! We released 7B and 13B models that are *fully open*, and compete with the best open-weight models out there.
Importantly, we use the same post-training recipe as our recently released Tülu 3, and it works remarkably well, more so at the 13B size.
Importantly, we use the same post-training recipe as our recently released Tülu 3, and it works remarkably well, more so at the 13B size.
Reposted by Pradeep Dasigi

open source tulu 3 model recreation! rivals the original sft and other models in its size range
huggingface.co/allura-org/T...
huggingface.co/allura-org/T...

allura-org/Teleut-7b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 24, 2024 at 8:09 PM
open source tulu 3 model recreation! rivals the original sft and other models in its size range
huggingface.co/allura-org/T...
huggingface.co/allura-org/T...
A common approach for improving LM performance at specific skills is to *synthesize* training data that is similar to corresponding evals. But how do we ensure that we are not simply overfitting to those benchmarks? It is worth highlighting our approach to evaluation for Tülu 3 in this regard.
Super excited to release Tülu 3, a suite of open SoTA post-trained models, data, code, evaluation framework, and most importantly post-training recipes.
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
November 23, 2024 at 11:53 PM
A common approach for improving LM performance at specific skills is to *synthesize* training data that is similar to corresponding evals. But how do we ensure that we are not simply overfitting to those benchmarks? It is worth highlighting our approach to evaluation for Tülu 3 in this regard.
Super excited to release Tülu 3, a suite of open SoTA post-trained models, data, code, evaluation framework, and most importantly post-training recipes.
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
November 23, 2024 at 4:20 AM
Super excited to release Tülu 3, a suite of open SoTA post-trained models, data, code, evaluation framework, and most importantly post-training recipes.
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
I learned A LOT about LM post-training working on this project. We wrote it all up so now you can too.
Paper: allenai.org/papers/tulu-...
Reposted by Pradeep Dasigi
Excited to release Tulu 3! We worked hard to try and make the best open post-training recipe we could, and the results are good!
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
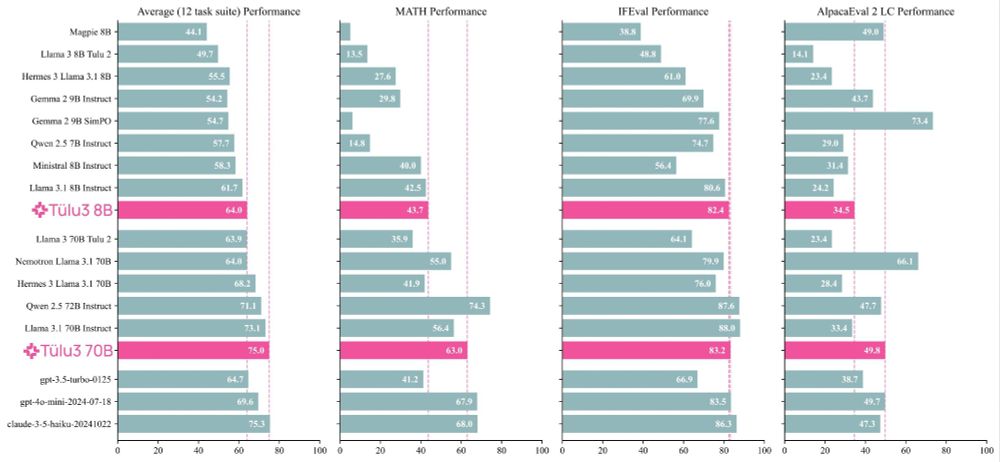
November 21, 2024 at 5:45 PM
Excited to release Tulu 3! We worked hard to try and make the best open post-training recipe we could, and the results are good!
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
I was lucky enough to work on almost every stage of the pipeline in one way or another. Some comments + highlights ⬇️
Reposted by Pradeep Dasigi
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
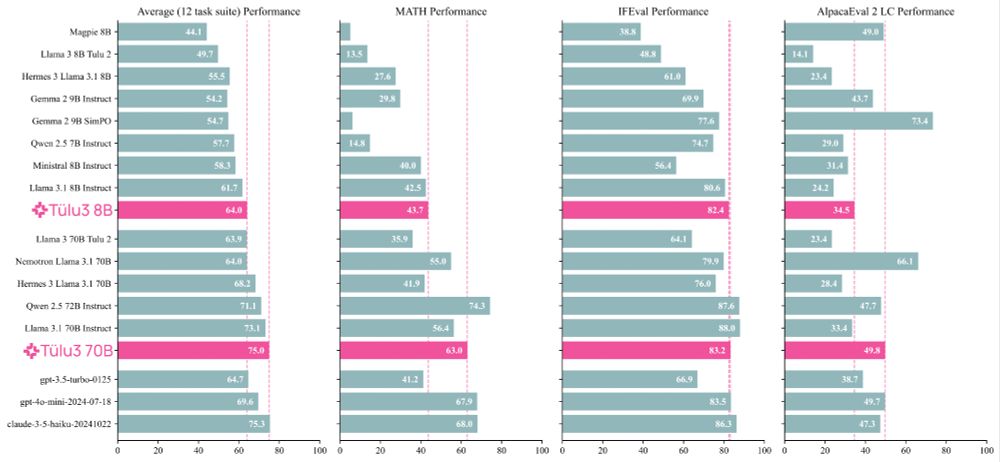
November 21, 2024 at 5:15 PM
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
Reposted by Pradeep Dasigi

Open Post-Training recipes!
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)

November 21, 2024 at 6:40 PM
Open Post-Training recipes!
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)
Some of my personal highlights:
💡 We significantly scaled up our preference data!
💡 RL with Verifiable Rewards to improve targeted skills like math and precise instruction following
💡 evaluation toolkit for post-training (including new unseen evals!)