



Pradeep Dasigi
@pdasigi.bsky.social
#NLP research @ai2.bsky.social; OLMo post-training
https://pdasigi.github.io/
https://pdasigi.github.io/
Reposted by Pradeep Dasigi

also some other tülu contributors are on the market:
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
January 30, 2025 at 7:25 PM
also some other tülu contributors are on the market:
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
@ljvmiranda.bsky.social (ljvmiranda921.github.io) and Xinxi Lyu (alrope123.github.io) are also applying to phd programs, and @valentinapy.bsky.social (valentinapy.github.io) is on the faculty market, hire them all!!
How does your cat feel about wearing a Garmin device and adding you as a connection?
November 27, 2024 at 6:15 PM
How does your cat feel about wearing a Garmin device and adding you as a connection?
As a reviewer, I did not find it particularly useful. The recommendations I received were already addressed by my initial review. As an author, the mix of reviews we got were roughly the same quality as usual.
This is an interesting idea though, and I hope there's a way to make it work.
This is an interesting idea though, and I hope there's a way to make it work.
November 25, 2024 at 2:52 PM
As a reviewer, I did not find it particularly useful. The recommendations I received were already addressed by my initial review. As an author, the mix of reviews we got were roughly the same quality as usual.
This is an interesting idea though, and I hope there's a way to make it work.
This is an interesting idea though, and I hope there's a way to make it work.
We even developed two *new* instruction following evals for this setup:
1) IFEval-OOD, a variant of IFEval (Zhou et al., 2023) but with a disjoint set of constraints.
2) HREF, a more general IF eval targeting a diverse set of IF tasks.
Detailed analyses on these evals are coming out soon.
1) IFEval-OOD, a variant of IFEval (Zhou et al., 2023) but with a disjoint set of constraints.
2) HREF, a more general IF eval targeting a diverse set of IF tasks.
Detailed analyses on these evals are coming out soon.
November 23, 2024 at 11:53 PM
We even developed two *new* instruction following evals for this setup:
1) IFEval-OOD, a variant of IFEval (Zhou et al., 2023) but with a disjoint set of constraints.
2) HREF, a more general IF eval targeting a diverse set of IF tasks.
Detailed analyses on these evals are coming out soon.
1) IFEval-OOD, a variant of IFEval (Zhou et al., 2023) but with a disjoint set of constraints.
2) HREF, a more general IF eval targeting a diverse set of IF tasks.
Detailed analyses on these evals are coming out soon.
We presented some preliminary findings on generalization and overfitting in the report based on this setup, and will put out more analysis soon.
November 23, 2024 at 11:53 PM
We presented some preliminary findings on generalization and overfitting in the report based on this setup, and will put out more analysis soon.
From a traditional ML perspective, this setup may seem obvious, i.e., a dev-test split of an eval. But none of our modern evals are in-distribution anymore, and we expect our models to generalize across distributions. So we adapted the traditional setup to use newer and harder evals as unseen ones.
November 23, 2024 at 11:53 PM
From a traditional ML perspective, this setup may seem obvious, i.e., a dev-test split of an eval. But none of our modern evals are in-distribution anymore, and we expect our models to generalize across distributions. So we adapted the traditional setup to use newer and harder evals as unseen ones.
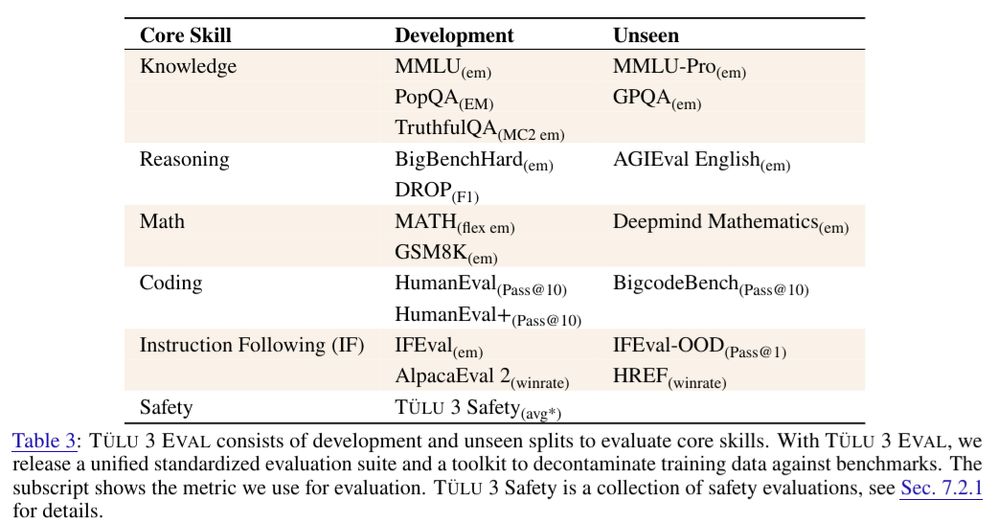
For each "core skill" we care about, we chose a separate set of "development" and "unseen" evaluations. We tracked the performance of models only on the former during development and evaluated only the final checkpoints on the unseen ones.
November 23, 2024 at 11:53 PM
For each "core skill" we care about, we chose a separate set of "development" and "unseen" evaluations. We tracked the performance of models only on the former during development and evaluated only the final checkpoints on the unseen ones.
Want to post-train on your own data? Here's our training code: github.com/allenai/open....
Reproducing LM evaluations can be notoriously difficult. So we released our evaluation framework where you can specify and tweak every last detail and reproduce what we did: github.com/allenai/olmes.
Reproducing LM evaluations can be notoriously difficult. So we released our evaluation framework where you can specify and tweak every last detail and reproduce what we did: github.com/allenai/olmes.
GitHub - allenai/open-instruct
Contribute to allenai/open-instruct development by creating an account on GitHub.
github.com
November 23, 2024 at 4:20 AM
Want to post-train on your own data? Here's our training code: github.com/allenai/open....
Reproducing LM evaluations can be notoriously difficult. So we released our evaluation framework where you can specify and tweak every last detail and reproduce what we did: github.com/allenai/olmes.
Reproducing LM evaluations can be notoriously difficult. So we released our evaluation framework where you can specify and tweak every last detail and reproduce what we did: github.com/allenai/olmes.