



Mickael Chen
@mickaelchen.bsky.social
Research Multimodal Generative AI, and now robotics.
Generating MNIST digits for a decade.
Generating MNIST digits for a decade.
Reposted by Mickael Chen

I'm speaking at #aiPULSE2025 today on Open & re-purposable foundation models for the automotive industry.
The morning keynotes talked a lot about open source so my slide here might be timely.
The morning keynotes talked a lot about open source so my slide here might be timely.

December 4, 2025 at 10:34 AM
I'm speaking at #aiPULSE2025 today on Open & re-purposable foundation models for the automotive industry.
The morning keynotes talked a lot about open source so my slide here might be timely.
The morning keynotes talked a lot about open source so my slide here might be timely.
Reposted by Mickael Chen

🛠️ Already have a complex, pre-trained pipeline?
If you are using bilinear interpolation anywhere, NAF acts as a strict drop-in replacement.
Just swap it in. No retraining required. It’s literally free points for your metrics.📈
If you are using bilinear interpolation anywhere, NAF acts as a strict drop-in replacement.
Just swap it in. No retraining required. It’s literally free points for your metrics.📈

November 25, 2025 at 10:44 AM
🛠️ Already have a complex, pre-trained pipeline?
If you are using bilinear interpolation anywhere, NAF acts as a strict drop-in replacement.
Just swap it in. No retraining required. It’s literally free points for your metrics.📈
If you are using bilinear interpolation anywhere, NAF acts as a strict drop-in replacement.
Just swap it in. No retraining required. It’s literally free points for your metrics.📈
That was a cool project brillantly led by Ellington Kirby during his internship.
We were curious if we could train diffusion models on sets of point coordinates.
For images, this is a step towards spatial diffusion, with pixels reorganizing themselves, instead of diffusing in rgb values space only.
We were curious if we could train diffusion models on sets of point coordinates.
For images, this is a step towards spatial diffusion, with pixels reorganizing themselves, instead of diffusing in rgb values space only.
LOGen: Toward Lidar Object Generation by Point Diffusion
by: E. Kirby, @mickaelchen.bsky.social, R. Marlet, N. Samet
tl;dr: a diffusion-based method producing lidar point clouds of dataset objects, with an extensive control of the generation
📄 arxiv.org/abs/2412.07385
Code: ✅
by: E. Kirby, @mickaelchen.bsky.social, R. Marlet, N. Samet
tl;dr: a diffusion-based method producing lidar point clouds of dataset objects, with an extensive control of the generation
📄 arxiv.org/abs/2412.07385
Code: ✅

November 26, 2025 at 1:19 PM
That was a cool project brillantly led by Ellington Kirby during his internship.
We were curious if we could train diffusion models on sets of point coordinates.
For images, this is a step towards spatial diffusion, with pixels reorganizing themselves, instead of diffusing in rgb values space only.
We were curious if we could train diffusion models on sets of point coordinates.
For images, this is a step towards spatial diffusion, with pixels reorganizing themselves, instead of diffusing in rgb values space only.
Is it just me or is fucking linkedin taking over some of the functions that twitter used to fill?
May 8, 2025 at 8:30 AM
Is it just me or is fucking linkedin taking over some of the functions that twitter used to fill?
Reposted by Mickael Chen

🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!


March 21, 2025 at 6:43 AM
🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
Wow, neet! Reannotation is key here.
Conjecture:
As we are get more and more well-aligned text-image data, it will become easier and easier to train models.
This will allow us to explore both more streamlined and more exotic training recipes.
More signals that exciting times are coming!
Conjecture:
As we are get more and more well-aligned text-image data, it will become easier and easier to train models.
This will allow us to explore both more streamlined and more exotic training recipes.
More signals that exciting times are coming!
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 11:50 AM
Wow, neet! Reannotation is key here.
Conjecture:
As we are get more and more well-aligned text-image data, it will become easier and easier to train models.
This will allow us to explore both more streamlined and more exotic training recipes.
More signals that exciting times are coming!
Conjecture:
As we are get more and more well-aligned text-image data, it will become easier and easier to train models.
This will allow us to explore both more streamlined and more exotic training recipes.
More signals that exciting times are coming!
A game changer. A lot of people suspected it *should* work, but actually seeing it in action is something.

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.

February 28, 2025 at 12:25 AM
A game changer. A lot of people suspected it *should* work, but actually seeing it in action is something.
Reposted by Mickael Chen
🚗 Ever wondered if an AI model could learn to drive just by watching YouTube? 🎥👀
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]

February 24, 2025 at 12:53 PM
🚗 Ever wondered if an AI model could learn to drive just by watching YouTube? 🎥👀
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]
Bluesky is less engaging because the algorithm is less predatory.
February 8, 2025 at 1:14 PM
Bluesky is less engaging because the algorithm is less predatory.
I'm curious who at Microsoft or OpenAI thought it was a good idea to publicize this narrative.
If you are an organisation concered about ethics of training data, now is probably your best chance to act and be heard.
www.reuters.com/technology/m...
If you are an organisation concered about ethics of training data, now is probably your best chance to act and be heard.
www.reuters.com/technology/m...

Microsoft probing if DeepSeek-linked group improperly obtained OpenAI data, Bloomberg News reports
Microsoft and OpenAI are investigating whether data output from OpenAI's technology was obtained in an unauthorized manner by a group linked to Chinese artificial intelligence (AI) startup DeepSeek, Bloomberg News reported on Tuesday.
www.reuters.com
January 29, 2025 at 7:51 PM
I'm curious who at Microsoft or OpenAI thought it was a good idea to publicize this narrative.
If you are an organisation concered about ethics of training data, now is probably your best chance to act and be heard.
www.reuters.com/technology/m...
If you are an organisation concered about ethics of training data, now is probably your best chance to act and be heard.
www.reuters.com/technology/m...
The plateau on training scaling and the shift to test-time scaling created favorable conditions for a competitor like DeepSeek to raise and catch up with OpenAI.
Nah, I just made that up. Need to put more thoughts into this. 🤔
Nah, I just made that up. Need to put more thoughts into this. 🤔
January 29, 2025 at 12:23 AM
The plateau on training scaling and the shift to test-time scaling created favorable conditions for a competitor like DeepSeek to raise and catch up with OpenAI.
Nah, I just made that up. Need to put more thoughts into this. 🤔
Nah, I just made that up. Need to put more thoughts into this. 🤔
We've reached a point where synthetic data is just better and more convenient than messy noisy web-crawled data.
It's been true for multimodal data for a while, and semi-automated data as in the Florence-2 paper has been very succesful. arxiv.org/abs/2311.06242
It's been true for multimodal data for a while, and semi-automated data as in the Florence-2 paper has been very succesful. arxiv.org/abs/2311.06242

Ilya Sutskever's Test of Time talk:
1. Pretraining is dead. The internet has run out of data.
2. What's next? Agents, synthetic data, inference-time compute
3. What's next long term? Superintelligence, reasoning, understanding, self-awareness, and we can't predict what's gonna happen.
1. Pretraining is dead. The internet has run out of data.
2. What's next? Agents, synthetic data, inference-time compute
3. What's next long term? Superintelligence, reasoning, understanding, self-awareness, and we can't predict what's gonna happen.



December 14, 2024 at 11:23 AM
We've reached a point where synthetic data is just better and more convenient than messy noisy web-crawled data.
It's been true for multimodal data for a while, and semi-automated data as in the Florence-2 paper has been very succesful. arxiv.org/abs/2311.06242
It's been true for multimodal data for a while, and semi-automated data as in the Florence-2 paper has been very succesful. arxiv.org/abs/2311.06242
Reposted by Mickael Chen

Better VQ-VAEs with this one weird rotation trick!
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.

December 2, 2024 at 7:52 PM
Better VQ-VAEs with this one weird rotation trick!
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
Reposted by Mickael Chen

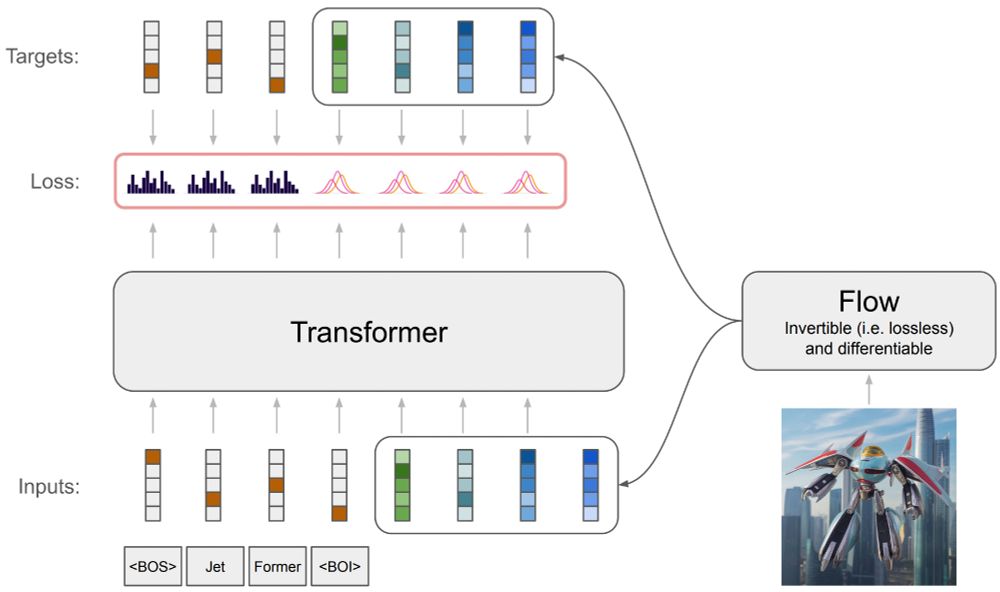
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Reposted by Mickael Chen

For AI to be fair and sustainable, we'd need to figure out attribution, i.e. "How much does training sample X contribute to model output Y?" Then the creator of sample X gets paid an amount proportional to what the user paid for the inference call that produced output Y.
November 21, 2024 at 9:31 AM
For AI to be fair and sustainable, we'd need to figure out attribution, i.e. "How much does training sample X contribute to model output Y?" Then the creator of sample X gets paid an amount proportional to what the user paid for the inference call that produced output Y.
A great place for students interested in AI/CV research internship. It's a very strong team, invested with all of their students. Check it out.
🚨Hear! Hear!
We have a few MSc research internship openings at valeo.ai in Paris for 2025 on computer vision & machine learning (yeah AI).
You can find the openings in the link below along with the achievements of our amazing previous interns: valeoai.github.io/interns/
Join us!
We have a few MSc research internship openings at valeo.ai in Paris for 2025 on computer vision & machine learning (yeah AI).
You can find the openings in the link below along with the achievements of our amazing previous interns: valeoai.github.io/interns/
Join us!
Internships | valeo.ai - valeo.ai research page
valeo.ai research page
valeoai.github.io
November 23, 2024 at 1:50 PM
A great place for students interested in AI/CV research internship. It's a very strong team, invested with all of their students. Check it out.
Reposted by Mickael Chen
ICYMI our PointBeV #CVPR2024 poster here's a quick talk by lead author Loïck Chambon.
It brings a change of paradigm in multi-camera bird's-eye-view (BeV) segmentation via a flexible mechanism to produce sparse BeV points that can adapt to situation, task, compute
www.linkedin.com/posts/andrei...
It brings a change of paradigm in multi-camera bird's-eye-view (BeV) segmentation via a flexible mechanism to produce sparse BeV points that can adapt to situation, task, compute
www.linkedin.com/posts/andrei...

Andrei Bursuc on LinkedIn: #cvpr2024 #cvpr
In case you missed our PointBeV poster at #CVPR2024 here's a quick presentation by the lead author Loïck C..
PointBEV brings a change of paradigm in…
www.linkedin.com
November 22, 2024 at 11:18 AM
ICYMI our PointBeV #CVPR2024 poster here's a quick talk by lead author Loïck Chambon.
It brings a change of paradigm in multi-camera bird's-eye-view (BeV) segmentation via a flexible mechanism to produce sparse BeV points that can adapt to situation, task, compute
www.linkedin.com/posts/andrei...
It brings a change of paradigm in multi-camera bird's-eye-view (BeV) segmentation via a flexible mechanism to produce sparse BeV points that can adapt to situation, task, compute
www.linkedin.com/posts/andrei...
Reposted by Mickael Chen
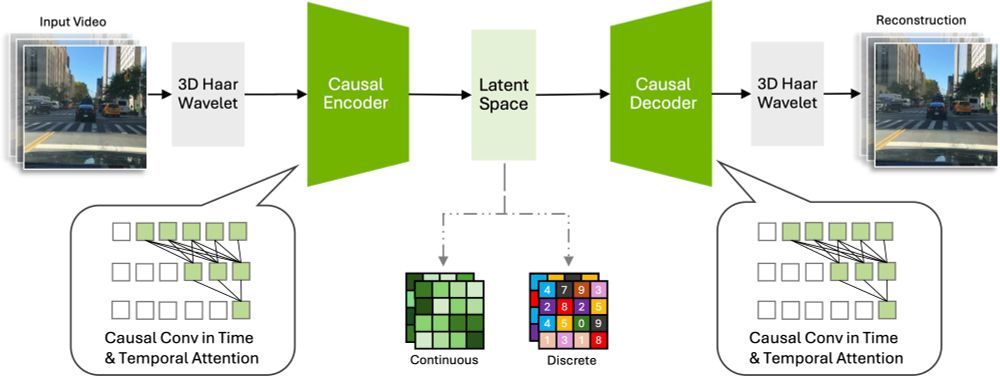
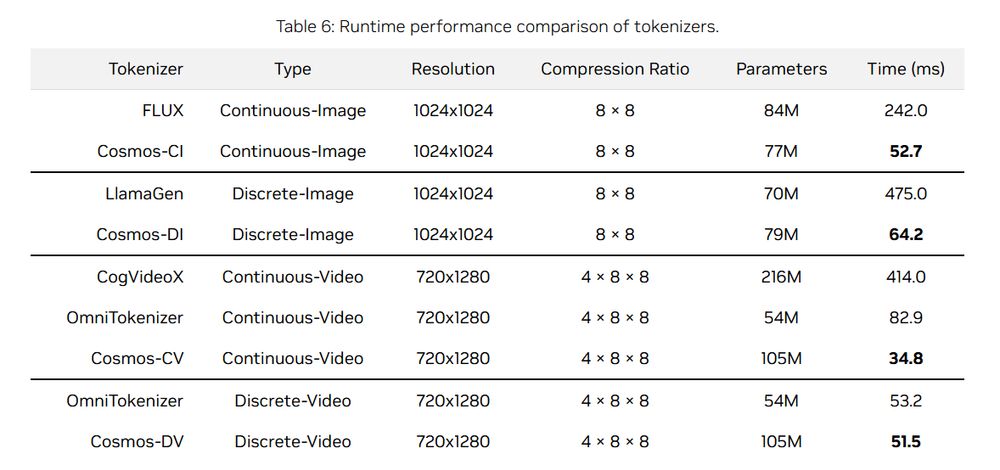
The Cosmos suite of neural tokenizers for images & videos is impressive.
Cosmos is trained on diverse high-res imgs & long-vids, scales well for both discrete & continuous tokens, generalizes to multiple domains (robotics, driving, egocentric ...) & has excellent runtime
github.com/NVIDIA/Cosmo...
Cosmos is trained on diverse high-res imgs & long-vids, scales well for both discrete & continuous tokens, generalizes to multiple domains (robotics, driving, egocentric ...) & has excellent runtime
github.com/NVIDIA/Cosmo...


November 20, 2024 at 10:58 PM
The Cosmos suite of neural tokenizers for images & videos is impressive.
Cosmos is trained on diverse high-res imgs & long-vids, scales well for both discrete & continuous tokens, generalizes to multiple domains (robotics, driving, egocentric ...) & has excellent runtime
github.com/NVIDIA/Cosmo...
Cosmos is trained on diverse high-res imgs & long-vids, scales well for both discrete & continuous tokens, generalizes to multiple domains (robotics, driving, egocentric ...) & has excellent runtime
github.com/NVIDIA/Cosmo...
Reposted by Mickael Chen
This is ridiculous. And then people will talk about inclusivity and mental health. Sorry to speak my mind so openly, but this has to be the most toxic idea in a very long time.
November 18, 2024 at 7:23 PM
This is ridiculous. And then people will talk about inclusivity and mental health. Sorry to speak my mind so openly, but this has to be the most toxic idea in a very long time.