



Michael Tschannen
@mtschannen.bsky.social
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation.
mitscha.github.io
mitscha.github.io
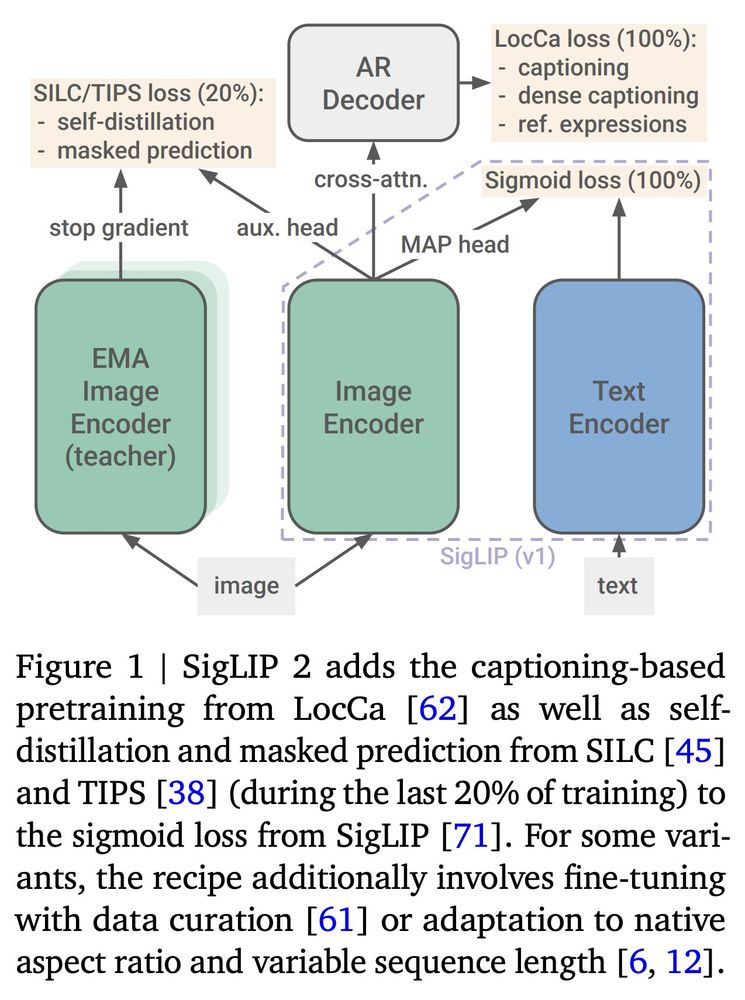
📢2⃣ Yesterday we released SigLIP 2!
TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1.
Bonus: Variants supporting native aspect and variable sequence length.
A thread with interesting resources👇
TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1.
Bonus: Variants supporting native aspect and variable sequence length.
A thread with interesting resources👇
February 22, 2025 at 3:34 PM
📢2⃣ Yesterday we released SigLIP 2!
TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1.
Bonus: Variants supporting native aspect and variable sequence length.
A thread with interesting resources👇
TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1.
Bonus: Variants supporting native aspect and variable sequence length.
A thread with interesting resources👇
Reposted by Michael Tschannen

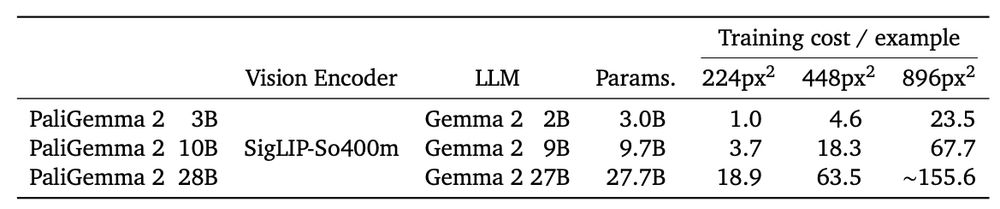
Looking for a small or medium sized VLM? PaliGemma 2 spans more than 150x of compute!
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
February 19, 2025 at 5:47 PM
Looking for a small or medium sized VLM? PaliGemma 2 spans more than 150x of compute!
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
Check out our detailed report about *Jet* 🌊 - a simple, transformer-based normalizing flow architecture without bells and whistles.
Jet is an important part of JetFormer's engine ⚙️ As a standalone model it is very tame and behaves predictably (e.g. when scaling it up).
Jet is an important part of JetFormer's engine ⚙️ As a standalone model it is very tame and behaves predictably (e.g. when scaling it up).
With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️

December 20, 2024 at 3:17 PM
Check out our detailed report about *Jet* 🌊 - a simple, transformer-based normalizing flow architecture without bells and whistles.
Jet is an important part of JetFormer's engine ⚙️ As a standalone model it is very tame and behaves predictably (e.g. when scaling it up).
Jet is an important part of JetFormer's engine ⚙️ As a standalone model it is very tame and behaves predictably (e.g. when scaling it up).
Reposted by Michael Tschannen

Attending #NeurIPS2024? If you're interested in multimodal systems, building inclusive & culturally aware models, and how fractals relate to LLMs, we've 3 posters for you. I look forward to presenting them on behalf of our GDM team @ Zurich & collaborators. Details below (1/4)
December 7, 2024 at 6:50 PM
Attending #NeurIPS2024? If you're interested in multimodal systems, building inclusive & culturally aware models, and how fractals relate to LLMs, we've 3 posters for you. I look forward to presenting them on behalf of our GDM team @ Zurich & collaborators. Details below (1/4)
Reposted by Michael Tschannen
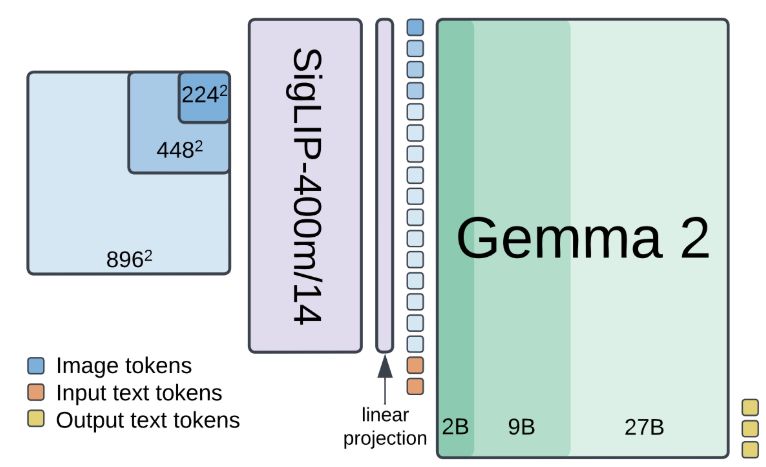
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
1/7
December 5, 2024 at 6:16 PM
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
1/7
Reposted by Michael Tschannen

In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
December 2, 2024 at 6:36 PM
In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
Reposted by Michael Tschannen

I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵

December 2, 2024 at 5:19 PM
I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
Reposted by Michael Tschannen

Did you ever try to get an auto-regressive transformer to operate in a continuous latent space which is not fixed ahead of time but learned end to end from scratch?
Enter JetFormer: arxiv.org/abs/2411.19722 -- joint work in a dream team: @mtschannen.bsky.social and @kolesnikov.ch
Enter JetFormer: arxiv.org/abs/2411.19722 -- joint work in a dream team: @mtschannen.bsky.social and @kolesnikov.ch
December 2, 2024 at 6:17 PM
Did you ever try to get an auto-regressive transformer to operate in a continuous latent space which is not fixed ahead of time but learned end to end from scratch?
Enter JetFormer: arxiv.org/abs/2411.19722 -- joint work in a dream team: @mtschannen.bsky.social and @kolesnikov.ch
Enter JetFormer: arxiv.org/abs/2411.19722 -- joint work in a dream team: @mtschannen.bsky.social and @kolesnikov.ch
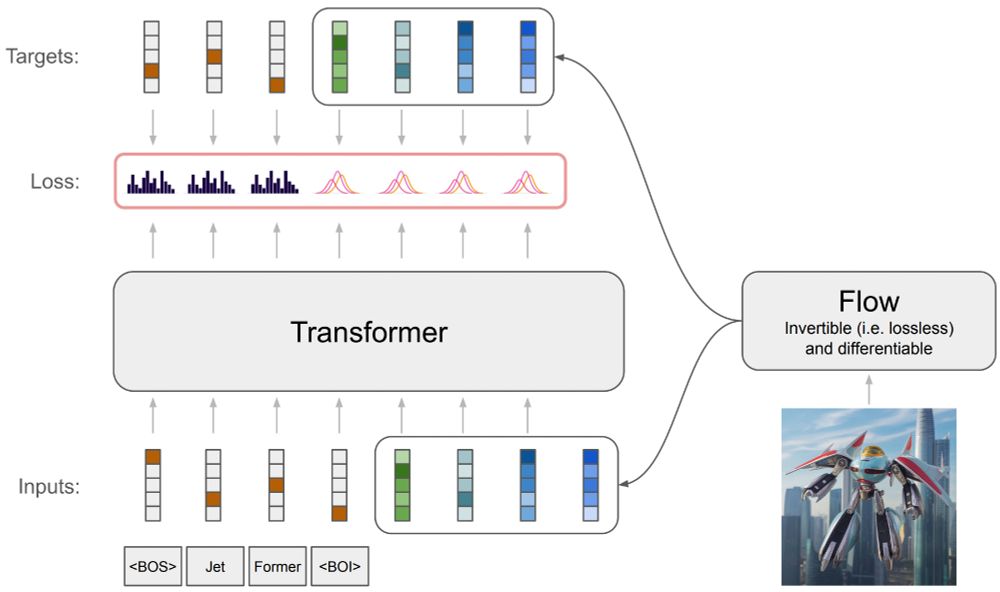
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/