




Lj Miranda
@ljvmiranda.bsky.social
🇵🇭 One of my research interests is improving the state of Filipino NLP
Happy to share that we're taking a major step towards this by introducing FilBench, an LLM benchmark for Filipino!
Also accepted at EMNLP Main! 🎉
Learn more:
huggingface.co/blog/filbench
Happy to share that we're taking a major step towards this by introducing FilBench, an LLM benchmark for Filipino!
Also accepted at EMNLP Main! 🎉
Learn more:
huggingface.co/blog/filbench

🇵🇭 FilBench - Can LLMs Understand and Generate Filipino?
huggingface.co
August 20, 2025 at 8:40 PM
🇵🇭 One of my research interests is improving the state of Filipino NLP
Happy to share that we're taking a major step towards this by introducing FilBench, an LLM benchmark for Filipino!
Also accepted at EMNLP Main! 🎉
Learn more:
huggingface.co/blog/filbench
Happy to share that we're taking a major step towards this by introducing FilBench, an LLM benchmark for Filipino!
Also accepted at EMNLP Main! 🎉
Learn more:
huggingface.co/blog/filbench

Reposted by Lj Miranda

Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚
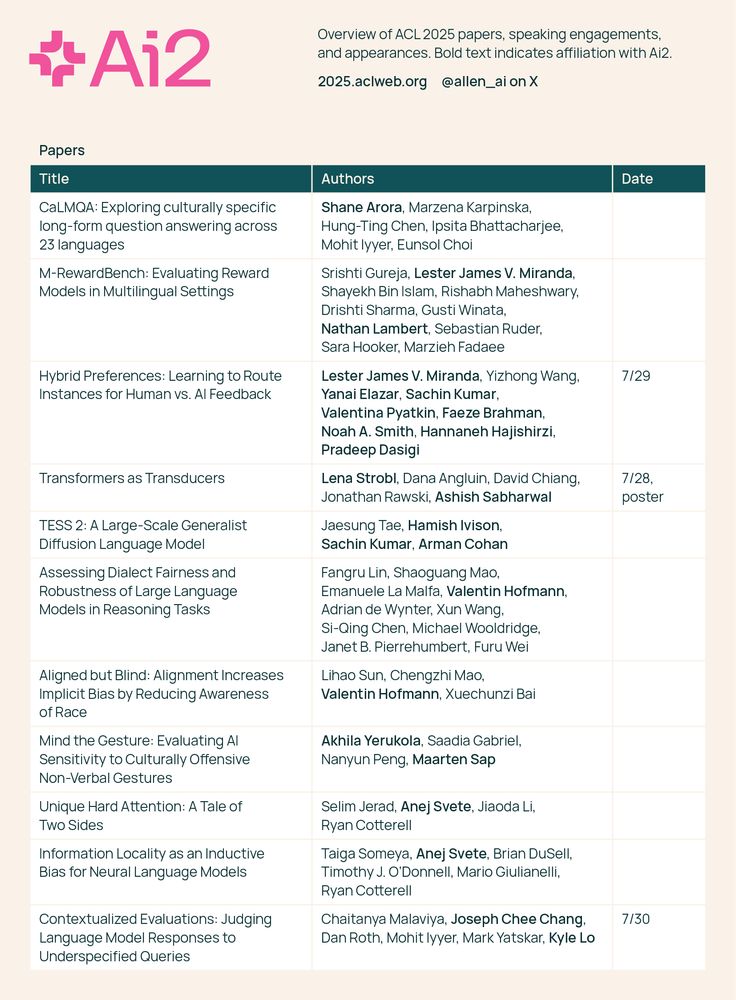

July 28, 2025 at 5:00 PM
Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚
I'll be at @aclmeeting.bsky.social in Vienna! I'm going to present the ff first/co-first author works:

July 24, 2025 at 12:56 PM
I'll be at @aclmeeting.bsky.social in Vienna! I'm going to present the ff first/co-first author works:
fun learning stuff (+ phew i haven't blogged in a long time!): ljvmiranda921.github.io/notebook/202...

‘Draw me a swordsman’: Can tool-calling LLMs draw pixel art?
Just a fun weekend experiment on model-context protocol (MCP): I asked several tool-calling LLMs to draw a 4-frame spritesheet of a swordsman performing a sl...
ljvmiranda921.github.io
July 20, 2025 at 4:36 AM
fun learning stuff (+ phew i haven't blogged in a long time!): ljvmiranda921.github.io/notebook/202...
Reposted by Lj Miranda

We’re thrilled that SEA-VL has been accepted to the ACL 2025 (Main)!
Thank you to everyone who contributed to this project 🥳
Paper: arxiv.org/abs/2503.07920
Project: seacrowd.github.io/seavl-launch/
#ACL2025NLP #SEACrowd #ForSEABySEA
Thank you to everyone who contributed to this project 🥳
Paper: arxiv.org/abs/2503.07920
Project: seacrowd.github.io/seavl-launch/
#ACL2025NLP #SEACrowd #ForSEABySEA


May 16, 2025 at 10:18 PM
We’re thrilled that SEA-VL has been accepted to the ACL 2025 (Main)!
Thank you to everyone who contributed to this project 🥳
Paper: arxiv.org/abs/2503.07920
Project: seacrowd.github.io/seavl-launch/
#ACL2025NLP #SEACrowd #ForSEABySEA
Thank you to everyone who contributed to this project 🥳
Paper: arxiv.org/abs/2503.07920
Project: seacrowd.github.io/seavl-launch/
#ACL2025NLP #SEACrowd #ForSEABySEA
Reposted by Lj Miranda

We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
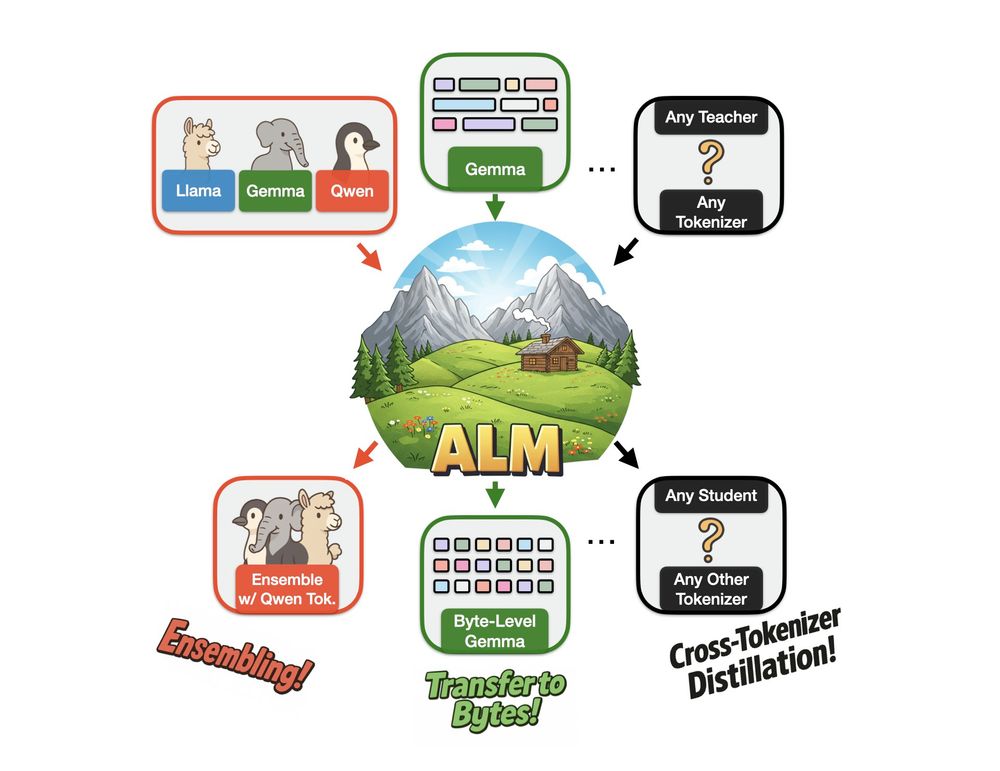
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Reposted by Lj Miranda

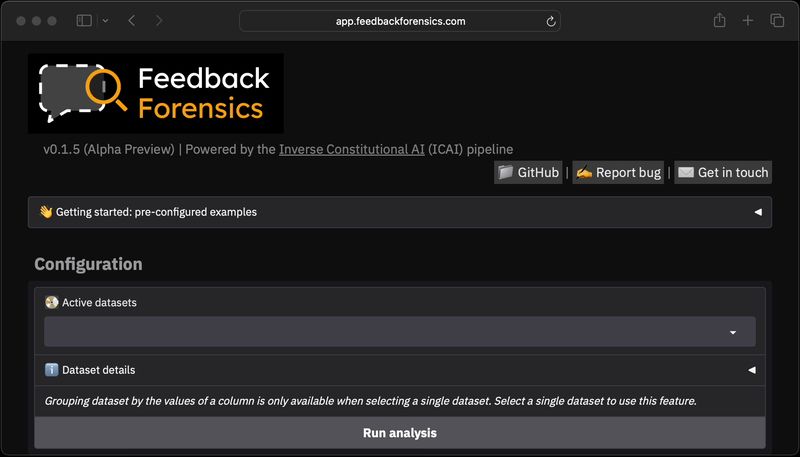
🕵🏻💬 Introducing Feedback Forensics: a new tool to investigate pairwise preference data.
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
March 17, 2025 at 6:12 PM
🕵🏻💬 Introducing Feedback Forensics: a new tool to investigate pairwise preference data.
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
Reposted by Lj Miranda

OLMo 2 0325 32B Preference Mixture: Solves AI alignment challenges through diverse preferences
- Combines 7 datasets
- Filters for instruction-following capability
- Balances on-policy and off-policy prompts
- Enabled successful DPO of OLMo-2-0325-32B model
huggingface.co/datasets/all...
- Combines 7 datasets
- Filters for instruction-following capability
- Balances on-policy and off-policy prompts
- Enabled successful DPO of OLMo-2-0325-32B model
huggingface.co/datasets/all...

allenai/olmo-2-0325-32b-preference-mix · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
March 13, 2025 at 7:45 PM
OLMo 2 0325 32B Preference Mixture: Solves AI alignment challenges through diverse preferences
- Combines 7 datasets
- Filters for instruction-following capability
- Balances on-policy and off-policy prompts
- Enabled successful DPO of OLMo-2-0325-32B model
huggingface.co/datasets/all...
- Combines 7 datasets
- Filters for instruction-following capability
- Balances on-policy and off-policy prompts
- Enabled successful DPO of OLMo-2-0325-32B model
huggingface.co/datasets/all...
Reposted by Lj Miranda
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.

January 30, 2025 at 2:28 PM
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.
Reposted by Lj Miranda

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 3, 2025 at 4:02 PM
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
Reposted by Lj Miranda

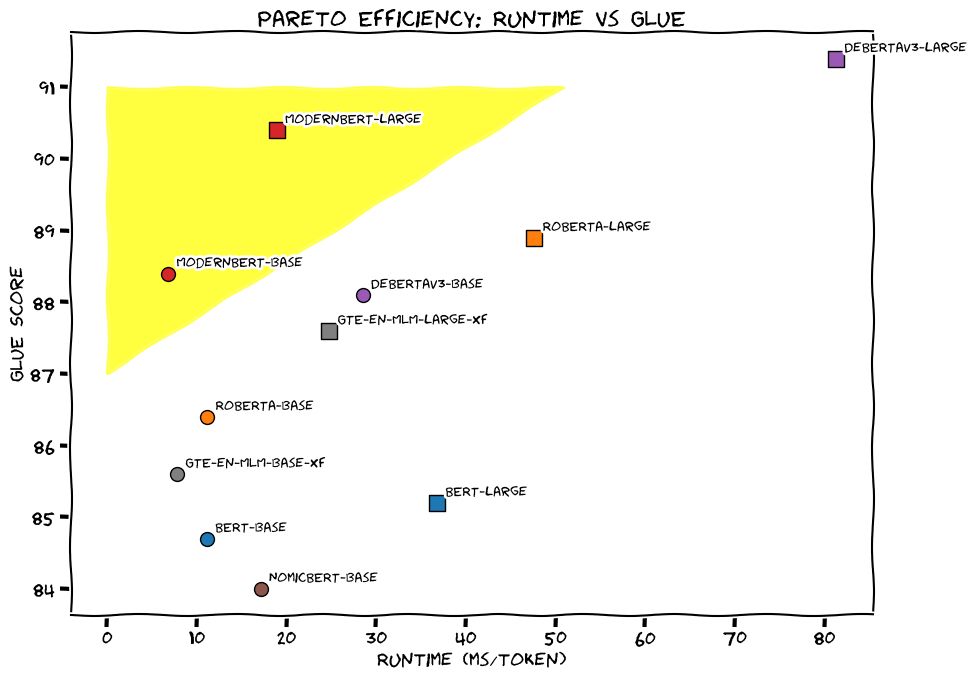
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
December 19, 2024 at 4:41 PM
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
Reposted by Lj Miranda

New research reveals a worrying trend: AI's data practices risk concentrating power overwhelmingly in the hands of dominant technology companies. With analysis from
@shaynelongpre.bsky.social @sarahooker.bsky.social @smw.bsky.social @giadapistilli.com www.technologyreview.com/2024/12/18/1...
@shaynelongpre.bsky.social @sarahooker.bsky.social @smw.bsky.social @giadapistilli.com www.technologyreview.com/2024/12/18/1...

This is where the data to build AI comes from
New findings show how the sources of data are concentrating power in the hands of the most powerful tech companies.
www.technologyreview.com
December 18, 2024 at 5:34 PM
New research reveals a worrying trend: AI's data practices risk concentrating power overwhelmingly in the hands of dominant technology companies. With analysis from
@shaynelongpre.bsky.social @sarahooker.bsky.social @smw.bsky.social @giadapistilli.com www.technologyreview.com/2024/12/18/1...
@shaynelongpre.bsky.social @sarahooker.bsky.social @smw.bsky.social @giadapistilli.com www.technologyreview.com/2024/12/18/1...
Reposted by Lj Miranda

Stop by our #NeurIPS tutorial on Experimental Design & Analysis for AI Researchers! 📊
neurips.cc/virtual/2024/tutorial/99528
Are you an AI researcher interested in comparing models/methods? Then your conclusions rely on well-designed experiments. We'll cover best practices + case studies. 👇
neurips.cc/virtual/2024/tutorial/99528
Are you an AI researcher interested in comparing models/methods? Then your conclusions rely on well-designed experiments. We'll cover best practices + case studies. 👇
NeurIPS Tutorial Experimental Design and Analysis for AI ResearchersNeurIPS 2024
neurips.cc
December 7, 2024 at 6:15 PM
Stop by our #NeurIPS tutorial on Experimental Design & Analysis for AI Researchers! 📊
neurips.cc/virtual/2024/tutorial/99528
Are you an AI researcher interested in comparing models/methods? Then your conclusions rely on well-designed experiments. We'll cover best practices + case studies. 👇
neurips.cc/virtual/2024/tutorial/99528
Are you an AI researcher interested in comparing models/methods? Then your conclusions rely on well-designed experiments. We'll cover best practices + case studies. 👇
Reposted by Lj Miranda

We just updated the AI for Humanists guide to model selection to include Llama 3.3, and a recommended best cost/capability tradeoff, llama 3.1 8B. What have you tried, and what would you suggest?
aiforhumanists.com/guides/models/
aiforhumanists.com/guides/models/
Models
The AI for Humanists project is developing resources to enable DH scholars to explore how large language models and AI technologies can be used in their research and teaching. Find an annotated biblio...
aiforhumanists.com
December 10, 2024 at 7:04 PM
We just updated the AI for Humanists guide to model selection to include Llama 3.3, and a recommended best cost/capability tradeoff, llama 3.1 8B. What have you tried, and what would you suggest?
aiforhumanists.com/guides/models/
aiforhumanists.com/guides/models/
Reposted by Lj Miranda
the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
NeurIPS Tutorial Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and AdaptationNeurIPS 2024
neurips.cc
December 10, 2024 at 3:31 PM
the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
Reposted by Lj Miranda

Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨

December 10, 2024 at 3:54 AM
Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨
Reposted by Lj Miranda

⭐️ We're going to launch Grassroots Science, a year-long ambitious, massive-scale, fully open-source initiative aimed at developing multilingual LLMs aligned to diverse and inclusive human preferences in Feb 2025.
🌐 Check our website: grassroots.science.
#NLProc #GrassrootsScience
🌐 Check our website: grassroots.science.
#NLProc #GrassrootsScience
Grassroots Science
A global initiative focused on developing state-of-the-art multilingual language models through grassroots efforts.
grassroots.science
December 9, 2024 at 5:02 AM
⭐️ We're going to launch Grassroots Science, a year-long ambitious, massive-scale, fully open-source initiative aimed at developing multilingual LLMs aligned to diverse and inclusive human preferences in Feb 2025.
🌐 Check our website: grassroots.science.
#NLProc #GrassrootsScience
🌐 Check our website: grassroots.science.
#NLProc #GrassrootsScience
We're releasing the largest Universal Dependencies (UD) treebank for Tagalog, UD-NewsCrawl! This dataset has been a long time coming, but glad to see this through: 15k+ sentences versus the previous ~150 sents from older Tagalog treebanks.
🤗 : huggingface.co/datasets/UD-...
📝 : Paper soon!
🤗 : huggingface.co/datasets/UD-...
📝 : Paper soon!

UD-Filipino/UD_Tagalog-NewsCrawl · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 4, 2024 at 4:29 AM
We're releasing the largest Universal Dependencies (UD) treebank for Tagalog, UD-NewsCrawl! This dataset has been a long time coming, but glad to see this through: 15k+ sentences versus the previous ~150 sents from older Tagalog treebanks.
🤗 : huggingface.co/datasets/UD-...
📝 : Paper soon!
🤗 : huggingface.co/datasets/UD-...
📝 : Paper soon!
Reposted by Lj Miranda

I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U

Jonathan Berant (Tel Aviv University / Google) / Towards Robust Language Model Post-training
YouTube video by Yoav Artzi
youtu.be
December 2, 2024 at 3:45 AM
I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U
My favorite part about this release is that we were able to replicate our findings from the Tülu 3 post-training recipe here (e.g., on-policy preferences, RLVR) and found significant performance gains in our -DPO and -Instruct models!
Find all artifacts here: huggingface.co/collections/...
Find all artifacts here: huggingface.co/collections/...
November 26, 2024 at 9:03 PM
My favorite part about this release is that we were able to replicate our findings from the Tülu 3 post-training recipe here (e.g., on-policy preferences, RLVR) and found significant performance gains in our -DPO and -Instruct models!
Find all artifacts here: huggingface.co/collections/...
Find all artifacts here: huggingface.co/collections/...
Happy to be part of Tülu 3! Great effort to make the post-training stage open-source 😄
I worked on scaling our synthetic preference data (around 300k preference pairs for 70B) that led to performance gains when trained on using DPO.
I worked on scaling our synthetic preference data (around 300k preference pairs for 70B) that led to performance gains when trained on using DPO.
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
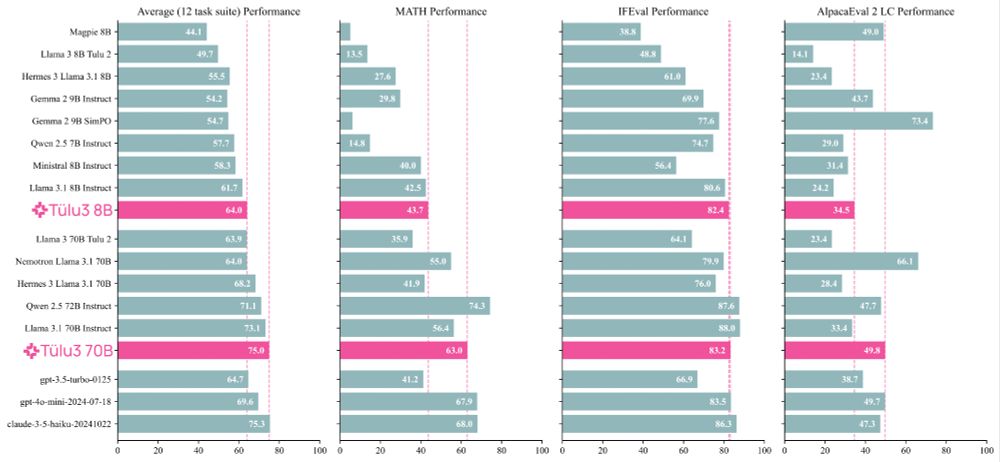
November 21, 2024 at 7:04 PM
Happy to be part of Tülu 3! Great effort to make the post-training stage open-source 😄
I worked on scaling our synthetic preference data (around 300k preference pairs for 70B) that led to performance gains when trained on using DPO.
I worked on scaling our synthetic preference data (around 300k preference pairs for 70B) that led to performance gains when trained on using DPO.
Reposted by Lj Miranda
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
November 21, 2024 at 5:15 PM
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
Reposted by Lj Miranda

I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
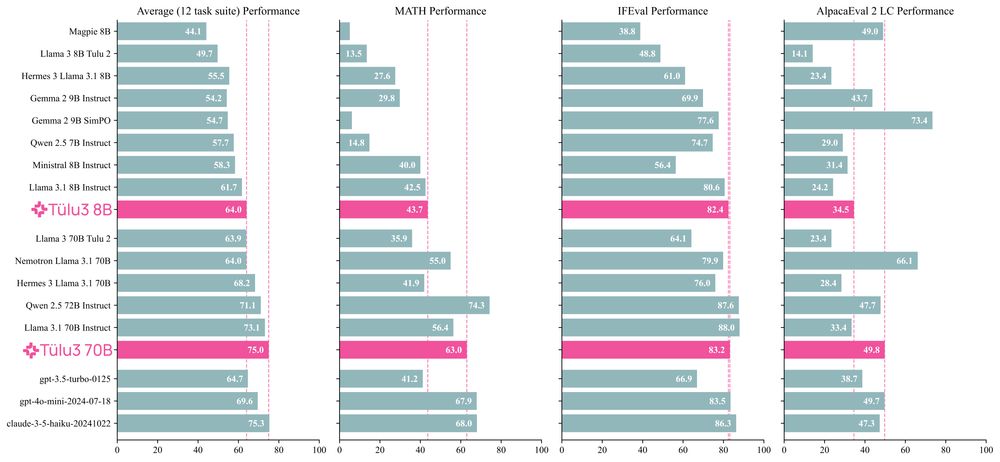
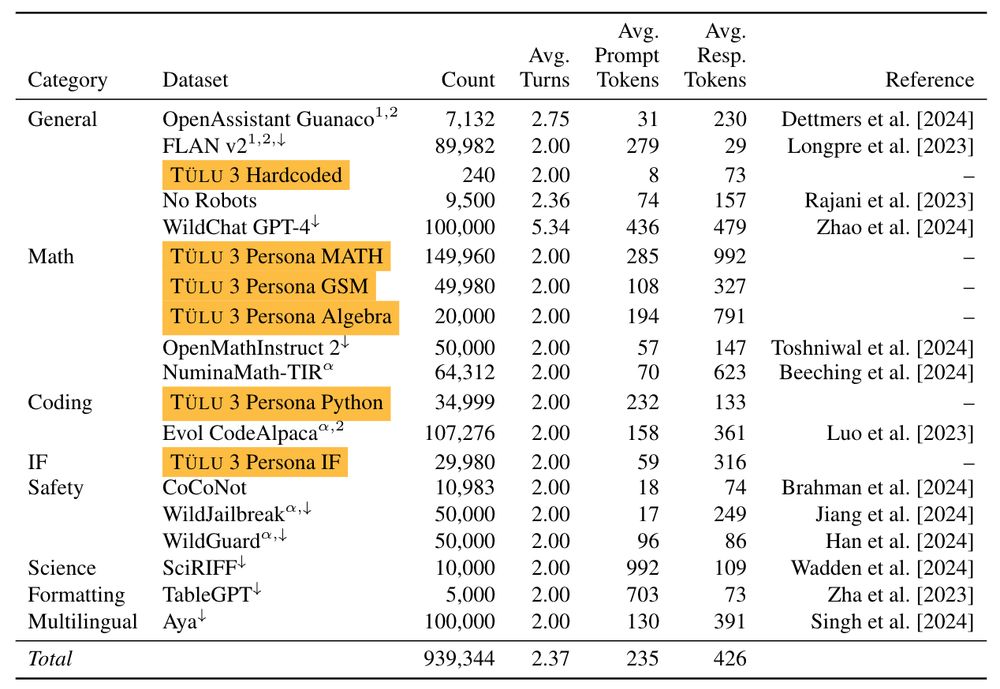
November 21, 2024 at 5:01 PM
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.