



Tom Aarsen
@tomaarsen.com
Sentence Transformers, SetFit & NLTK maintainer
Machine Learning Engineer at 🤗 Hugging Face
Machine Learning Engineer at 🤗 Hugging Face
Reposted by Tom Aarsen

More embedding models and an even more reliable inference engine is what you get with @hf.co Text Embeddings Inference v1.9.0 💥
More in the thread 🧵
More in the thread 🧵

February 17, 2026 at 4:05 PM
More embedding models and an even more reliable inference engine is what you get with @hf.co Text Embeddings Inference v1.9.0 💥
More in the thread 🧵
More in the thread 🧵
I've just pushed a v5.2.3 update for Sentence Transformers that introduces support training with Transformers v5.2 (apologies for the confusion around the project versions, they just happen to be close now 😆).
Updating is only useful if you're training.
Details in 🧵
Updating is only useful if you're training.
Details in 🧵

February 17, 2026 at 2:13 PM
I've just pushed a v5.2.3 update for Sentence Transformers that introduces support training with Transformers v5.2 (apologies for the confusion around the project versions, they just happen to be close now 😆).
Updating is only useful if you're training.
Details in 🧵
Updating is only useful if you're training.
Details in 🧵
The folks from @lightonai.bsky.social have released extremely strong & efficient Late Interaction models for code search: LateOn-Code(-edge)
Alongside a new tool: ColGrep, to use it with your coding agents straight away, locally & cheap
Models, dataset, and training code released 🧵
Alongside a new tool: ColGrep, to use it with your coding agents straight away, locally & cheap
Models, dataset, and training code released 🧵

February 12, 2026 at 7:30 PM
The folks from @lightonai.bsky.social have released extremely strong & efficient Late Interaction models for code search: LateOn-Code(-edge)
Alongside a new tool: ColGrep, to use it with your coding agents straight away, locally & cheap
Models, dataset, and training code released 🧵
Alongside a new tool: ColGrep, to use it with your coding agents straight away, locally & cheap
Models, dataset, and training code released 🧵
A few days back, following a long line of excellent proprietary models, VoyageAI by @mongodb.bsky.social released their 🚨 first ever open-weights embedding model for retrieval 🚨!
It's called voyage-4-nano, it's multilingual, and very efficient.
Details in 🧵
It's called voyage-4-nano, it's multilingual, and very efficient.
Details in 🧵

January 28, 2026 at 3:21 PM
A few days back, following a long line of excellent proprietary models, VoyageAI by @mongodb.bsky.social released their 🚨 first ever open-weights embedding model for retrieval 🚨!
It's called voyage-4-nano, it's multilingual, and very efficient.
Details in 🧵
It's called voyage-4-nano, it's multilingual, and very efficient.
Details in 🧵
🤝 I just released Sentence Transformers v5.2.1, introducing official support for the brand-new Transformers v5.x alongside v4.x.
Both versions will be supported for the foreseeable future!
Details in 🧵
Both versions will be supported for the foreseeable future!
Details in 🧵

January 26, 2026 at 3:00 PM
🤝 I just released Sentence Transformers v5.2.1, introducing official support for the brand-new Transformers v5.x alongside v4.x.
Both versions will be supported for the foreseeable future!
Details in 🧵
Both versions will be supported for the foreseeable future!
Details in 🧵
There were very few search rerankers specifically for e-commerce queries.
Until now, that is.
RexRerankers by Walmart Tech MLEs is a suite of 5 SOTA rerankers ranging from 17M to 0.6B parameters.
Details in 🧵:
Until now, that is.
RexRerankers by Walmart Tech MLEs is a suite of 5 SOTA rerankers ranging from 17M to 0.6B parameters.
Details in 🧵:

January 26, 2026 at 9:20 AM
There were very few search rerankers specifically for e-commerce queries.
Until now, that is.
RexRerankers by Walmart Tech MLEs is a suite of 5 SOTA rerankers ranging from 17M to 0.6B parameters.
Details in 🧵:
Until now, that is.
RexRerankers by Walmart Tech MLEs is a suite of 5 SOTA rerankers ranging from 17M to 0.6B parameters.
Details in 🧵:
Sentence Transformers 🤝 @unsloth.ai
We've collaborated with the fine folks at Unsloth to make your embedding model finetuning ~2x faster and require ~20% less VRAM!
The Unsloth team prepared 6 notebooks showing how you can take advantage of it!
🧵
We've collaborated with the fine folks at Unsloth to make your embedding model finetuning ~2x faster and require ~20% less VRAM!
The Unsloth team prepared 6 notebooks showing how you can take advantage of it!
🧵

January 22, 2026 at 5:40 PM
Sentence Transformers 🤝 @unsloth.ai
We've collaborated with the fine folks at Unsloth to make your embedding model finetuning ~2x faster and require ~20% less VRAM!
The Unsloth team prepared 6 notebooks showing how you can take advantage of it!
🧵
We've collaborated with the fine folks at Unsloth to make your embedding model finetuning ~2x faster and require ~20% less VRAM!
The Unsloth team prepared 6 notebooks showing how you can take advantage of it!
🧵
🏎️ You can perform 200ms search over 40 million texts using just a CPU server, 8GB of RAM, and 45GB of disk space.
The trick: Binary search with int8 rescoring.
I'll show you a demo & how it works in the 🧵:
The trick: Binary search with int8 rescoring.
I'll show you a demo & how it works in the 🧵:

January 6, 2026 at 7:56 PM
🏎️ You can perform 200ms search over 40 million texts using just a CPU server, 8GB of RAM, and 45GB of disk space.
The trick: Binary search with int8 rescoring.
I'll show you a demo & how it works in the 🧵:
The trick: Binary search with int8 rescoring.
I'll show you a demo & how it works in the 🧵:
🔥I've just published Sentence Transformers v5.2.0!
It introduces multi-processing for CrossEncoder (rerankers), multilingual NanoBEIR evaluators, similarity score outputs in mine_hard_negatives, Transformers v5 support and more.
Details in 🧵
It introduces multi-processing for CrossEncoder (rerankers), multilingual NanoBEIR evaluators, similarity score outputs in mine_hard_negatives, Transformers v5 support and more.
Details in 🧵
December 11, 2025 at 2:46 PM
🔥I've just published Sentence Transformers v5.2.0!
It introduces multi-processing for CrossEncoder (rerankers), multilingual NanoBEIR evaluators, similarity score outputs in mine_hard_negatives, Transformers v5 support and more.
Details in 🧵
It introduces multi-processing for CrossEncoder (rerankers), multilingual NanoBEIR evaluators, similarity score outputs in mine_hard_negatives, Transformers v5 support and more.
Details in 🧵
Reposted by Tom Aarsen

🤝 𝗦𝗲𝗻𝘁𝗲𝗻𝗰𝗲 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 𝗷𝗼𝗶𝗻𝘀 𝗛𝘂𝗴𝗴𝗶𝗻𝗴 𝗙𝗮𝗰𝗲
Originally developed at the UKP Lab at @tuda.bsky.social, Sentence Transformers has become one of the world’s most widely used open-source libraries for semantic embeddings in natural language processing.
(1/🧵)
Originally developed at the UKP Lab at @tuda.bsky.social, Sentence Transformers has become one of the world’s most widely used open-source libraries for semantic embeddings in natural language processing.
(1/🧵)

October 22, 2025 at 2:08 PM
🤝 𝗦𝗲𝗻𝘁𝗲𝗻𝗰𝗲 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 𝗷𝗼𝗶𝗻𝘀 𝗛𝘂𝗴𝗴𝗶𝗻𝗴 𝗙𝗮𝗰𝗲
Originally developed at the UKP Lab at @tuda.bsky.social, Sentence Transformers has become one of the world’s most widely used open-source libraries for semantic embeddings in natural language processing.
(1/🧵)
Originally developed at the UKP Lab at @tuda.bsky.social, Sentence Transformers has become one of the world’s most widely used open-source libraries for semantic embeddings in natural language processing.
(1/🧵)
🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵

October 22, 2025 at 1:04 PM
🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵

October 20, 2025 at 2:36 PM
The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
We're announcing a new update to MTEB: RTEB
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵

October 1, 2025 at 3:52 PM
We're announcing a new update to MTEB: RTEB
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
🐛 I've just released Sentence Transformers v5.1.1!
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵

September 22, 2025 at 11:42 AM
🐛 I've just released Sentence Transformers v5.1.1!
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
ModernBERT goes MULTILINGUAL!
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵

September 9, 2025 at 2:54 PM
ModernBERT goes MULTILINGUAL!
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
Google just launched EmbeddingGemma: an efficient, multilingual 308M embedding model that's ready for semantic search & more on just about any hardware, CPU included.
Details in 🧵:
Details in 🧵:

September 4, 2025 at 4:29 PM
Google just launched EmbeddingGemma: an efficient, multilingual 308M embedding model that's ready for semantic search & more on just about any hardware, CPU included.
Details in 🧵:
Details in 🧵:
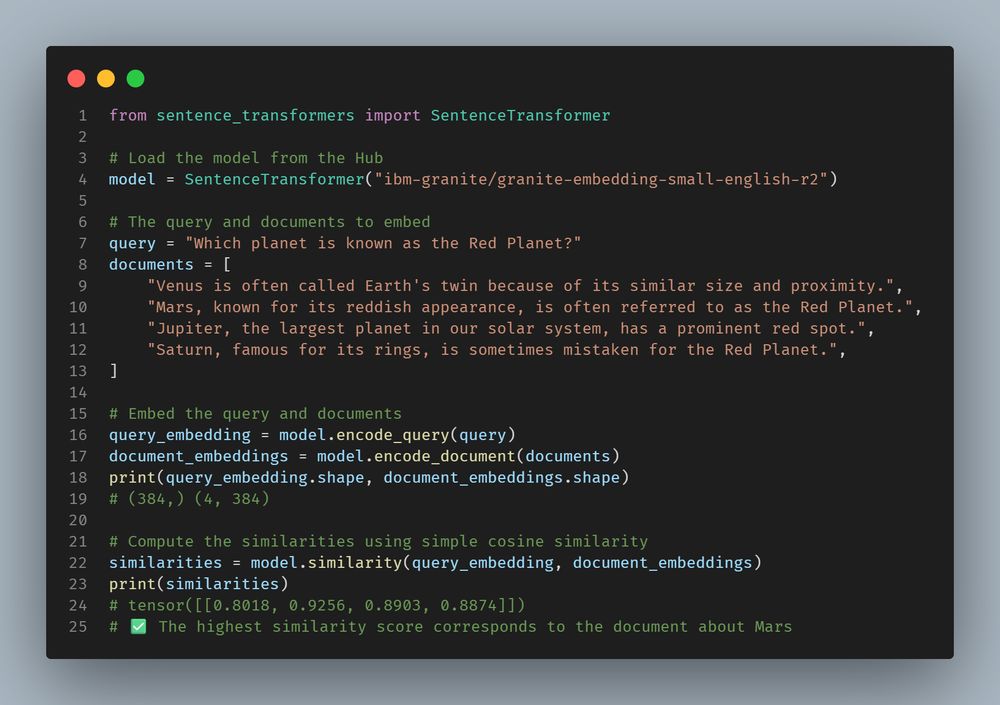
One of the most underrated players in AI models, IBM, released 2 new extremely efficient embedding models: granite-embedding-english-r2 & granite-embedding-small-english-r2, commercially viable.
Details in 🧵:
Details in 🧵:
August 18, 2025 at 10:33 AM
One of the most underrated players in AI models, IBM, released 2 new extremely efficient embedding models: granite-embedding-english-r2 & granite-embedding-small-english-r2, commercially viable.
Details in 🧵:
Details in 🧵:
😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more!
See 🧵for the deets:
See 🧵for the deets:

August 6, 2025 at 1:54 PM
😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more!
See 🧵for the deets:
See 🧵for the deets:
OpenAI is back with open source releases on @hf.co. This is the biggest release I've seen in a long time!
See more in huggingface.co/openai
See more in huggingface.co/openai

openai (OpenAI)
Org profile for OpenAI on Hugging Face, the AI community building the future.
huggingface.co
August 5, 2025 at 5:19 PM
OpenAI is back with open source releases on @hf.co. This is the biggest release I've seen in a long time!
See more in huggingface.co/openai
See more in huggingface.co/openai
I've just updated SetFit to v1.1.3, bringing compatibility with the recent datasets v4.0+ and Sentence Transformers v5.0+. You'll again be able to train tiny classifiers using very little training data!
🧵
🧵

August 5, 2025 at 1:35 PM
I've just updated SetFit to v1.1.3, bringing compatibility with the recent datasets v4.0+ and Sentence Transformers v5.0+. You'll again be able to train tiny classifiers using very little training data!
🧵
🧵
Some of the ModernBERT team is back with new encoder models: Ettin, ranging from tiny to small: 17M, 32M, 68M, 150M, 400M & 1B parameters. They also trained decoder models & checked if decoders could classify & if encoders could generate.
Details in 🧵:
Details in 🧵:
July 17, 2025 at 3:23 PM
Some of the ModernBERT team is back with new encoder models: Ettin, ranging from tiny to small: 17M, 32M, 68M, 150M, 400M & 1B parameters. They also trained decoder models & checked if decoders could classify & if encoders could generate.
Details in 🧵:
Details in 🧵:
‼️Sentence Transformers v5.0 is out! The biggest update yet introduces Sparse Embedding models, encode methods improvements, Router module for asymmetric models & much more. Sparse + Dense = 🔥 hybrid search performance!
Details in 🧵
Details in 🧵

July 1, 2025 at 2:00 PM
‼️Sentence Transformers v5.0 is out! The biggest update yet introduces Sparse Embedding models, encode methods improvements, Router module for asymmetric models & much more. Sparse + Dense = 🔥 hybrid search performance!
Details in 🧵
Details in 🧵
ColBERT (a.k.a. multi-vector, late-interaction) models are extremely strong search models, often outperforming dense embedding models. And @lightonai.bsky.social just released a new state-of-the-art one: GTE-ModernColBERT-v1!
Details in 🧵
Details in 🧵

April 30, 2025 at 3:27 PM
ColBERT (a.k.a. multi-vector, late-interaction) models are extremely strong search models, often outperforming dense embedding models. And @lightonai.bsky.social just released a new state-of-the-art one: GTE-ModernColBERT-v1!
Details in 🧵
Details in 🧵
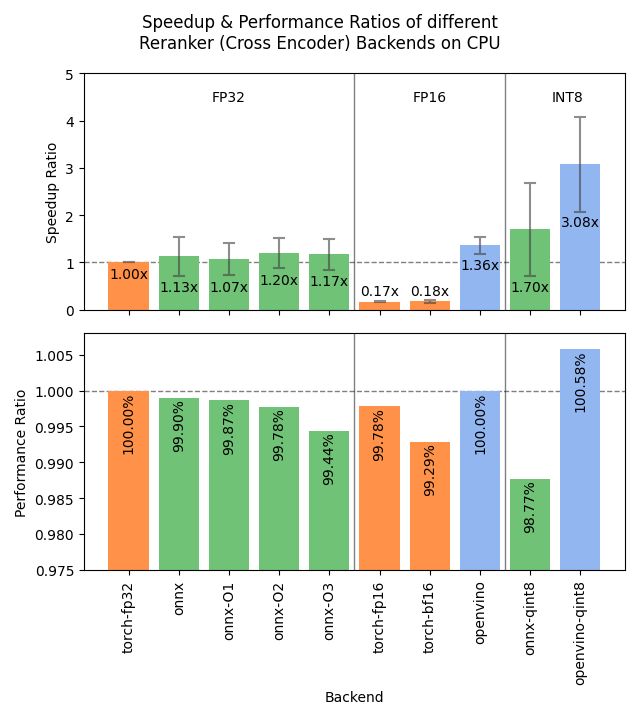
I just released Sentence Transformers v4.1; featuring ONNX and OpenVINO backends for rerankers offering 2-3x speedups and improved hard negatives mining which helps prepare stronger training datasets.
Details in 🧵
Details in 🧵
April 15, 2025 at 1:54 PM
I just released Sentence Transformers v4.1; featuring ONNX and OpenVINO backends for rerankers offering 2-3x speedups and improved hard negatives mining which helps prepare stronger training datasets.
Details in 🧵
Details in 🧵
I just published the SetFit v1.1.2 release, allowing you to finetune efficient classification models with very little training data.
The new patch introduces compatibility with the latest transformers and sentence-transformers versions.
The new patch introduces compatibility with the latest transformers and sentence-transformers versions.

April 4, 2025 at 11:58 AM
I just published the SetFit v1.1.2 release, allowing you to finetune efficient classification models with very little training data.
The new patch introduces compatibility with the latest transformers and sentence-transformers versions.
The new patch introduces compatibility with the latest transformers and sentence-transformers versions.