



Tom Aarsen
@tomaarsen.com
Sentence Transformers, SetFit & NLTK maintainer
Machine Learning Engineer at 🤗 Hugging Face
Machine Learning Engineer at 🤗 Hugging Face
We see an increasing desire from companies to move from large LLM APIs to local models for better control and privacy, reflected in the library's growth: in just the last 30 days, Sentence Transformer models have been downloaded >270 million times, second only to transformers.
🧵
🧵

October 22, 2025 at 1:04 PM
We see an increasing desire from companies to move from large LLM APIs to local models for better control and privacy, reflected in the library's growth: in just the last 30 days, Sentence Transformer models have been downloaded >270 million times, second only to transformers.
🧵
🧵
🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵

October 22, 2025 at 1:04 PM
🤗 Sentence Transformers is joining @hf.co! 🤗
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
This formalizes the existing maintenance structure, as I've personally led the project for the past two years on behalf of Hugging Face. I'm super excited about the transfer!
Details in 🧵
The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵

October 20, 2025 at 2:36 PM
The MTEB team has just released MTEB v2, an upgrade to their evaluation suite for embedding models!
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
Their blogpost covers all changes, including easier evaluation, multimodal support, rerankers, new interfaces, documentation, dataset statistics, a migration guide, etc.
🧵
The benchmark is multilingual (20 languages) and covers various domains (general, legal, healthcare, code, etc.), and it's already available on MTEB right now.
There's also an English only version available.
🧵
There's also an English only version available.
🧵

October 1, 2025 at 3:52 PM
The benchmark is multilingual (20 languages) and covers various domains (general, legal, healthcare, code, etc.), and it's already available on MTEB right now.
There's also an English only version available.
🧵
There's also an English only version available.
🧵
With RTEB, we can see the differences between public and private benchmarks, displayed in this figure here.
This would be an indication of whether the model is capable of generalizing nicely.
🧵
This would be an indication of whether the model is capable of generalizing nicely.
🧵

October 1, 2025 at 3:52 PM
With RTEB, we can see the differences between public and private benchmarks, displayed in this figure here.
This would be an indication of whether the model is capable of generalizing nicely.
🧵
This would be an indication of whether the model is capable of generalizing nicely.
🧵
We're announcing a new update to MTEB: RTEB
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵

October 1, 2025 at 3:52 PM
We're announcing a new update to MTEB: RTEB
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
It's a new multilingual text embedding retrieval benchmark with private (!) datasets, to ensure that we measure true generalization and avoid (accidental) overfitting.
Details in our blogpost below 🧵
- Add FLOPS calculation to SparseEncoder evaluators for determining a performance/speed tradeoff
- Add support for Knowledgeable Passage Retriever (KPR) models
- Multi-GPU processing with 'model.encode()' now works with 'convert_to_tensor'
🧵
- Add support for Knowledgeable Passage Retriever (KPR) models
- Multi-GPU processing with 'model.encode()' now works with 'convert_to_tensor'
🧵

September 22, 2025 at 11:42 AM
- Add FLOPS calculation to SparseEncoder evaluators for determining a performance/speed tradeoff
- Add support for Knowledgeable Passage Retriever (KPR) models
- Multi-GPU processing with 'model.encode()' now works with 'convert_to_tensor'
🧵
- Add support for Knowledgeable Passage Retriever (KPR) models
- Multi-GPU processing with 'model.encode()' now works with 'convert_to_tensor'
🧵
- `model.encode()` now throws an error if an unused keyword argument is passed
- a new `model.get_model_kwargs()` method for checking which custom model-specific keyword arguments are supported for this model
🧵
- a new `model.get_model_kwargs()` method for checking which custom model-specific keyword arguments are supported for this model
🧵

September 22, 2025 at 11:42 AM
- `model.encode()` now throws an error if an unused keyword argument is passed
- a new `model.get_model_kwargs()` method for checking which custom model-specific keyword arguments are supported for this model
🧵
- a new `model.get_model_kwargs()` method for checking which custom model-specific keyword arguments are supported for this model
🧵
🐛 I've just released Sentence Transformers v5.1.1!
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵

September 22, 2025 at 11:42 AM
🐛 I've just released Sentence Transformers v5.1.1!
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
It's a small patch release that makes the project more explicit with incorrect arguments and introduces some fixes for multi-GPU processing, evaluators, and hard negatives mining.
Details in 🧵
I'm very much looking forward to seeing embedding models based on mmBERT!
I already trained a basic Sentence Transformer model myself as I was too curious 👀
🧵
I already trained a basic Sentence Transformer model myself as I was too curious 👀
🧵

September 9, 2025 at 2:54 PM
I'm very much looking forward to seeing embedding models based on mmBERT!
I already trained a basic Sentence Transformer model myself as I was too curious 👀
🧵
I already trained a basic Sentence Transformer model myself as I was too curious 👀
🧵
Additionally: the ModernBERT-based mmBERT is much faster than the alternatives due to its architectural benefits. Easily up to 2x throughput in common scenarios.
🧵
🧵

September 9, 2025 at 2:54 PM
Additionally: the ModernBERT-based mmBERT is much faster than the alternatives due to its architectural benefits. Easily up to 2x throughput in common scenarios.
🧵
🧵
- Consistently outperforms equivalently sized models on all Multilingual tasks (XTREME, classification, MTEB v2 Multilingual after finetuning)
E.g. see the picture for MTEB v2 Multilingual performance.
🧵
E.g. see the picture for MTEB v2 Multilingual performance.
🧵

September 9, 2025 at 2:54 PM
- Consistently outperforms equivalently sized models on all Multilingual tasks (XTREME, classification, MTEB v2 Multilingual after finetuning)
E.g. see the picture for MTEB v2 Multilingual performance.
🧵
E.g. see the picture for MTEB v2 Multilingual performance.
🧵
Evaluation details:
- Very competitive with ModernBERT at equivalent sizes on English (GLUE, MTEB v2 English after finetuning)
E.g. see the picture for MTEB v2 English performance.
🧵
- Very competitive with ModernBERT at equivalent sizes on English (GLUE, MTEB v2 English after finetuning)
E.g. see the picture for MTEB v2 English performance.
🧵

September 9, 2025 at 2:54 PM
Evaluation details:
- Very competitive with ModernBERT at equivalent sizes on English (GLUE, MTEB v2 English after finetuning)
E.g. see the picture for MTEB v2 English performance.
🧵
- Very competitive with ModernBERT at equivalent sizes on English (GLUE, MTEB v2 English after finetuning)
E.g. see the picture for MTEB v2 English performance.
🧵
Training Details:
- Trained on 1833 languages incl. DCLM, FineWeb2, etc
- 3 training phases: 2.3T tokens on 60 languages, 600B tokens on 110 languages, and 100B tokens on all 1833 languages.
- Also uses model merging and clever transitions between the three training phases.
🧵
- Trained on 1833 languages incl. DCLM, FineWeb2, etc
- 3 training phases: 2.3T tokens on 60 languages, 600B tokens on 110 languages, and 100B tokens on all 1833 languages.
- Also uses model merging and clever transitions between the three training phases.
🧵

September 9, 2025 at 2:54 PM
Training Details:
- Trained on 1833 languages incl. DCLM, FineWeb2, etc
- 3 training phases: 2.3T tokens on 60 languages, 600B tokens on 110 languages, and 100B tokens on all 1833 languages.
- Also uses model merging and clever transitions between the three training phases.
🧵
- Trained on 1833 languages incl. DCLM, FineWeb2, etc
- 3 training phases: 2.3T tokens on 60 languages, 600B tokens on 110 languages, and 100B tokens on all 1833 languages.
- Also uses model merging and clever transitions between the three training phases.
🧵
Model details:
- 2 model sizes: 42M non-embed (140M total) and 110M non-embed (307M total)
- Uses the ModernBERT architecture + Gemma2 multilingual tokenizer (so: flash attention, alternating global/local attention, sequence packing, etc.)
- Max. seq. length of 8192 tokens
🧵
- 2 model sizes: 42M non-embed (140M total) and 110M non-embed (307M total)
- Uses the ModernBERT architecture + Gemma2 multilingual tokenizer (so: flash attention, alternating global/local attention, sequence packing, etc.)
- Max. seq. length of 8192 tokens
🧵

September 9, 2025 at 2:54 PM
Model details:
- 2 model sizes: 42M non-embed (140M total) and 110M non-embed (307M total)
- Uses the ModernBERT architecture + Gemma2 multilingual tokenizer (so: flash attention, alternating global/local attention, sequence packing, etc.)
- Max. seq. length of 8192 tokens
🧵
- 2 model sizes: 42M non-embed (140M total) and 110M non-embed (307M total)
- Uses the ModernBERT architecture + Gemma2 multilingual tokenizer (so: flash attention, alternating global/local attention, sequence packing, etc.)
- Max. seq. length of 8192 tokens
🧵
ModernBERT goes MULTILINGUAL!
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵

September 9, 2025 at 2:54 PM
ModernBERT goes MULTILINGUAL!
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
And the above blogpost also features details on how to finetune EmbeddingGemma. As an example, I finetuned it on the MIRIAD dataset for retrieving long (1k token) passages from scientific medical papers using detailed medical questions.
🧵
🧵

September 4, 2025 at 4:29 PM
And the above blogpost also features details on how to finetune EmbeddingGemma. As an example, I finetuned it on the MIRIAD dataset for retrieving long (1k token) passages from scientific medical papers using detailed medical questions.
🧵
🧵
Evaluation details:
- Outperforms any <500M embedding model on Multilingual & English MTEB
🧵
- Outperforms any <500M embedding model on Multilingual & English MTEB
🧵

September 4, 2025 at 4:29 PM
Evaluation details:
- Outperforms any <500M embedding model on Multilingual & English MTEB
🧵
- Outperforms any <500M embedding model on Multilingual & English MTEB
🧵
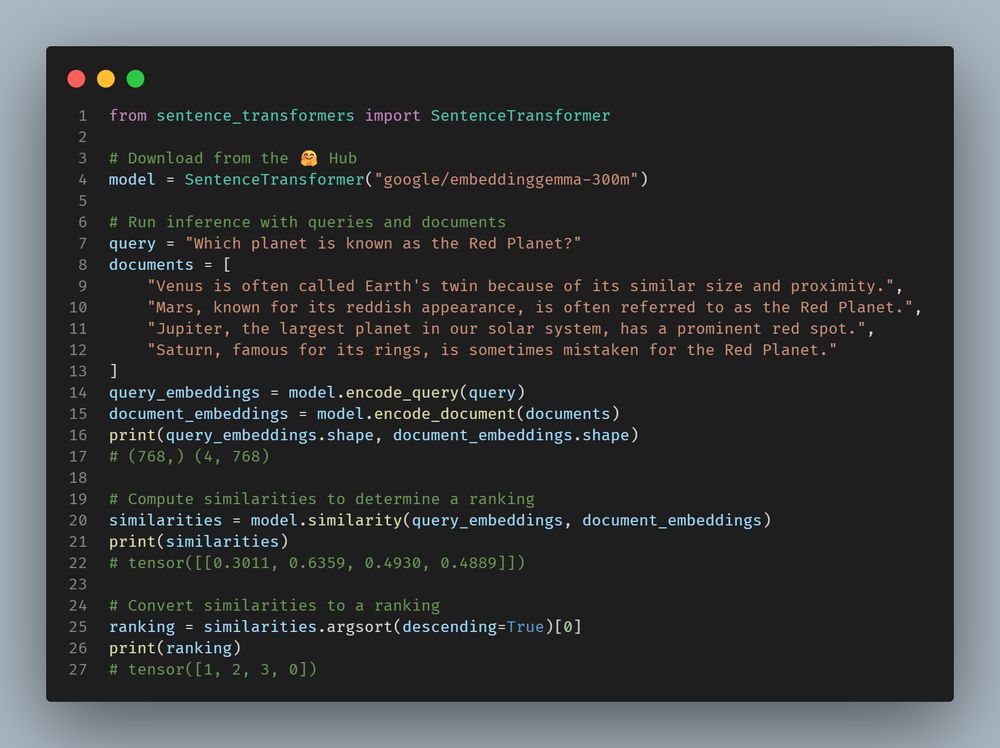
Usage:
- Supports 100+ languages, trained on 320B token multilingual corpus
- Compatible with Sentence-Transformers, LangChain, LlamaIndex, Haystack, txtai, Transformers.js, ONNX Runtime, and Text-Embeddings-Inference
- Matryoshka-style dimensionality reduction (512/256/128)
🧵
- Supports 100+ languages, trained on 320B token multilingual corpus
- Compatible with Sentence-Transformers, LangChain, LlamaIndex, Haystack, txtai, Transformers.js, ONNX Runtime, and Text-Embeddings-Inference
- Matryoshka-style dimensionality reduction (512/256/128)
🧵
September 4, 2025 at 4:29 PM
Usage:
- Supports 100+ languages, trained on 320B token multilingual corpus
- Compatible with Sentence-Transformers, LangChain, LlamaIndex, Haystack, txtai, Transformers.js, ONNX Runtime, and Text-Embeddings-Inference
- Matryoshka-style dimensionality reduction (512/256/128)
🧵
- Supports 100+ languages, trained on 320B token multilingual corpus
- Compatible with Sentence-Transformers, LangChain, LlamaIndex, Haystack, txtai, Transformers.js, ONNX Runtime, and Text-Embeddings-Inference
- Matryoshka-style dimensionality reduction (512/256/128)
🧵
Google just launched EmbeddingGemma: an efficient, multilingual 308M embedding model that's ready for semantic search & more on just about any hardware, CPU included.
Details in 🧵:
Details in 🧵:

September 4, 2025 at 4:29 PM
Google just launched EmbeddingGemma: an efficient, multilingual 308M embedding model that's ready for semantic search & more on just about any hardware, CPU included.
Details in 🧵:
Details in 🧵:
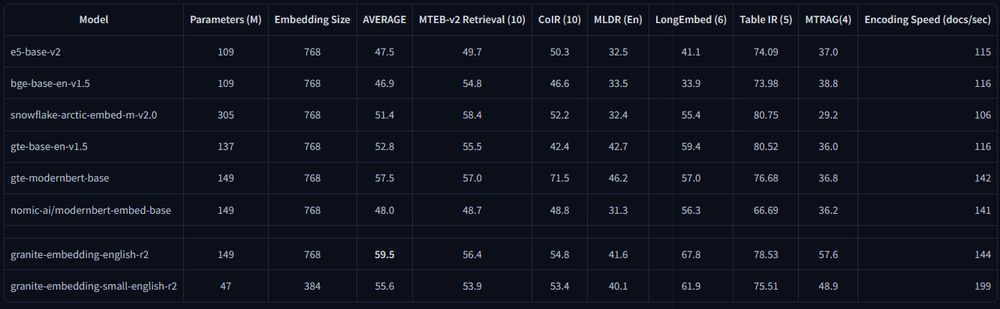
Evaluation details:
- Strong on common benchmarks like MTEB, MLDR, CoIR, BEIR
- Outperforms their previous equivalently sized models
- Beats other similarly sized models on various benchmarks, but your own evaluation is recommended
🧵
- Strong on common benchmarks like MTEB, MLDR, CoIR, BEIR
- Outperforms their previous equivalently sized models
- Beats other similarly sized models on various benchmarks, but your own evaluation is recommended
🧵
August 18, 2025 at 10:33 AM
Evaluation details:
- Strong on common benchmarks like MTEB, MLDR, CoIR, BEIR
- Outperforms their previous equivalently sized models
- Beats other similarly sized models on various benchmarks, but your own evaluation is recommended
🧵
- Strong on common benchmarks like MTEB, MLDR, CoIR, BEIR
- Outperforms their previous equivalently sized models
- Beats other similarly sized models on various benchmarks, but your own evaluation is recommended
🧵
Architecture details:
- 2 models: 47M and 149M parameters: extremely performant, even on CPUs
- Both use the ModernBERT architecture, i.e. alternating global & local attention, flash attention 2, etc.
- A 8192 maximum sequence length
🧵
- 2 models: 47M and 149M parameters: extremely performant, even on CPUs
- Both use the ModernBERT architecture, i.e. alternating global & local attention, flash attention 2, etc.
- A 8192 maximum sequence length
🧵

August 18, 2025 at 10:33 AM
Architecture details:
- 2 models: 47M and 149M parameters: extremely performant, even on CPUs
- Both use the ModernBERT architecture, i.e. alternating global & local attention, flash attention 2, etc.
- A 8192 maximum sequence length
🧵
- 2 models: 47M and 149M parameters: extremely performant, even on CPUs
- Both use the ModernBERT architecture, i.e. alternating global & local attention, flash attention 2, etc.
- A 8192 maximum sequence length
🧵
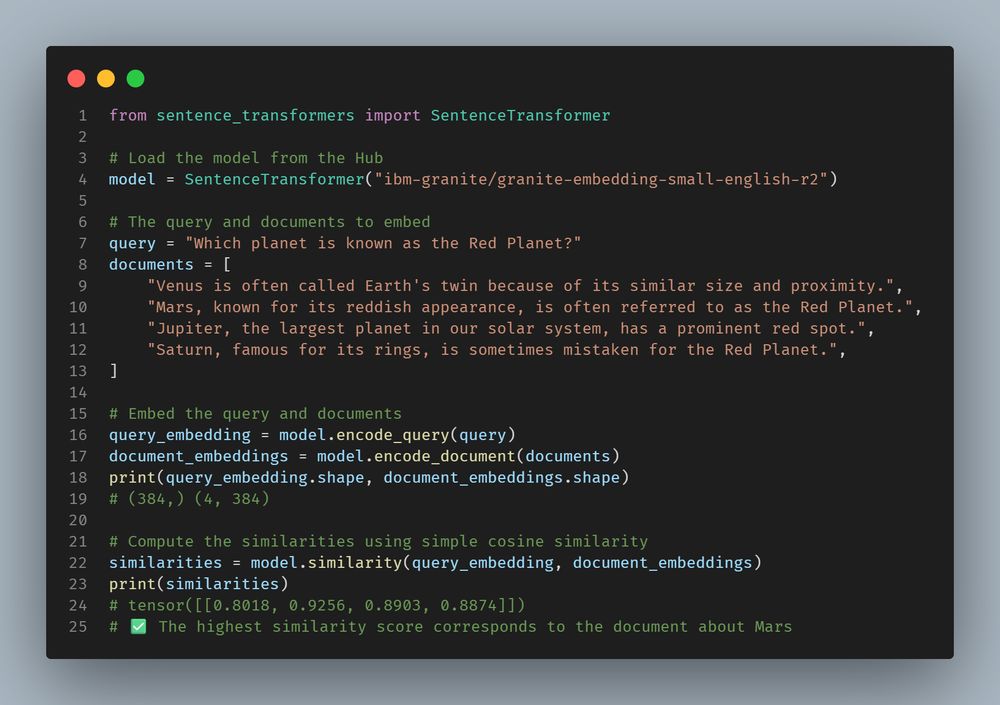
One of the most underrated players in AI models, IBM, released 2 new extremely efficient embedding models: granite-embedding-english-r2 & granite-embedding-small-english-r2, commercially viable.
Details in 🧵:
Details in 🧵:
August 18, 2025 at 10:33 AM
One of the most underrated players in AI models, IBM, released 2 new extremely efficient embedding models: granite-embedding-english-r2 & granite-embedding-small-english-r2, commercially viable.
Details in 🧵:
Details in 🧵:
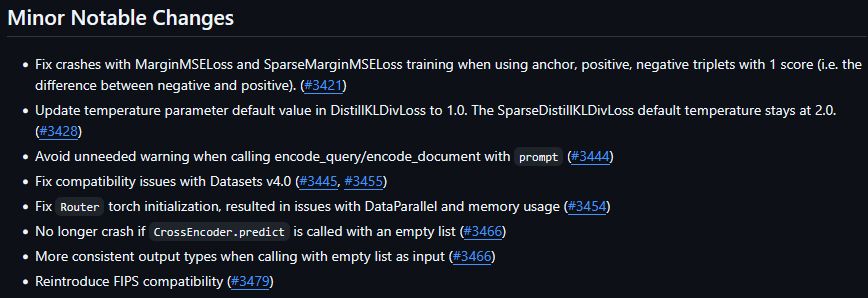
Plus many more smaller features & fixes (crash fixes, compatibility with datasets v4, FIPS compatibility, etc.).
🧵
🧵
August 6, 2025 at 1:54 PM
Plus many more smaller features & fixes (crash fixes, compatibility with datasets v4, FIPS compatibility, etc.).
🧵
🧵
We've added some documentation on evaluating SentenceTransformer models properly with MTEB. It's rudimentary as the documentation on the MTEB side is already great, but it should get you started.
sbert.net/docs/sentenc...
🧵
sbert.net/docs/sentenc...
🧵

August 6, 2025 at 1:54 PM
We've added some documentation on evaluating SentenceTransformer models properly with MTEB. It's rudimentary as the documentation on the MTEB side is already great, but it should get you started.
sbert.net/docs/sentenc...
🧵
sbert.net/docs/sentenc...
🧵