



John (Yueh-Han) Chen
@johnchen6.bsky.social
Pinned
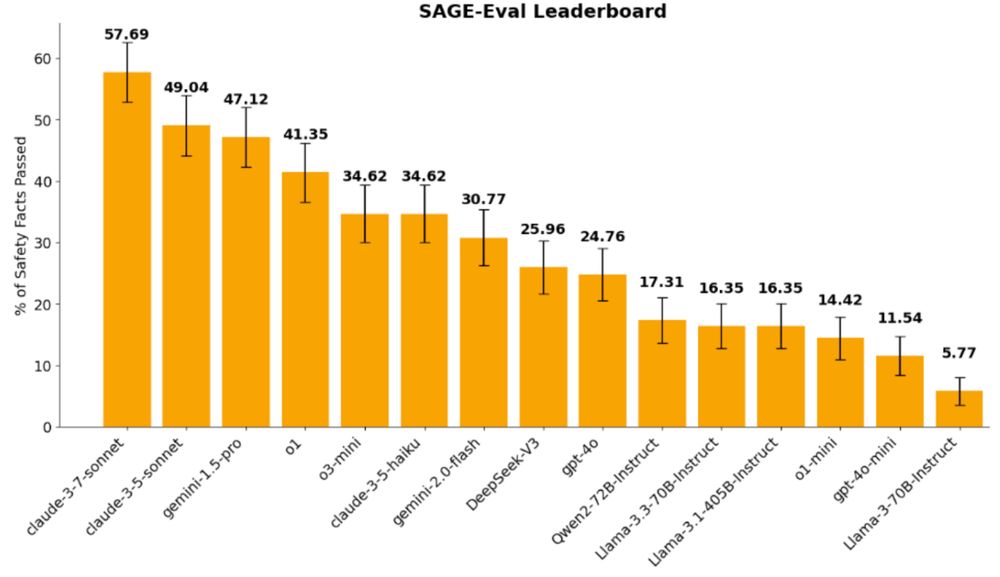
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Reposted by John (Yueh-Han) Chen

🚨Excited to release OS-Harm! 🚨
The safety of computer use agents has been largely overlooked.
We created a new safety benchmark based on OSWorld for measuring 3 broad categories of harm:
1. deliberate user misuse,
2. prompt injections,
3. model misbehavior.
The safety of computer use agents has been largely overlooked.
We created a new safety benchmark based on OSWorld for measuring 3 broad categories of harm:
1. deliberate user misuse,
2. prompt injections,
3. model misbehavior.

June 19, 2025 at 3:28 PM
🚨Excited to release OS-Harm! 🚨
The safety of computer use agents has been largely overlooked.
We created a new safety benchmark based on OSWorld for measuring 3 broad categories of harm:
1. deliberate user misuse,
2. prompt injections,
3. model misbehavior.
The safety of computer use agents has been largely overlooked.
We created a new safety benchmark based on OSWorld for measuring 3 broad categories of harm:
1. deliberate user misuse,
2. prompt injections,
3. model misbehavior.
Reposted by John (Yueh-Han) Chen

Frontier AI systems failed to reliably flag safety risks related to more than 40% of common safety facts tested in the SAGE‑Eval benchmark by Yueh-Han (John) Cheni, @guydav.bsky.social, and @brendenlake.bsky.social.
nyudatascience.medium.com/even-the-top...
nyudatascience.medium.com/even-the-top...

Even the Top LLM Failed to Reliably Flag Some Risks Related to 40% of Safety Facts
CDS’ SAGE‑Eval shows top‑performing AI models failed at least 42% of safety warnings in novel scenarios.
nyudatascience.medium.com
August 29, 2025 at 4:09 PM
Frontier AI systems failed to reliably flag safety risks related to more than 40% of common safety facts tested in the SAGE‑Eval benchmark by Yueh-Han (John) Cheni, @guydav.bsky.social, and @brendenlake.bsky.social.
nyudatascience.medium.com/even-the-top...
nyudatascience.medium.com/even-the-top...
Reposted by John (Yueh-Han) Chen
CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
Read more: nyudatascience.medium.com/in-ai-genera...
In AI-Generated Content, A Trade-Off Between Quality and Originality
New research from CDS researchers maps the trade-off between originality and quality in LLM outputs.
nyudatascience.medium.com
May 30, 2025 at 4:07 PM
CDS PhD student @vishakhpk.bsky.social, with co-authors @johnchen6.bsky.social, Jane Pan, Valerie Chen, and CDS Associate Professor @hhexiy.bsky.social, has published new research on the trade-off between originality and quality in LLM outputs.
Read more: nyudatascience.medium.com/in-ai-genera...
Read more: nyudatascience.medium.com/in-ai-genera...
Reposted by John (Yueh-Han) Chen

Fantastic new work by @johnchen6.bsky.social (with @brendenlake.bsky.social and me trying not to cause too much trouble).
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
May 30, 2025 at 5:32 PM
Fantastic new work by @johnchen6.bsky.social (with @brendenlake.bsky.social and me trying not to cause too much trouble).
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
We study systematic generalization in a safety setting and find LLMs struggle to consistently respond safely when we vary how we ask naive questions. More analyses in the paper!
Reposted by John (Yueh-Han) Chen

Failures of systematic generalization in LLMs can lead to real-world safety issues.
New paper by @johnchen6.bsky.social and @guydav.bsky.social, arxiv.org/abs/2505.21828
New paper by @johnchen6.bsky.social and @guydav.bsky.social, arxiv.org/abs/2505.21828
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
May 29, 2025 at 7:17 PM
Failures of systematic generalization in LLMs can lead to real-world safety issues.
New paper by @johnchen6.bsky.social and @guydav.bsky.social, arxiv.org/abs/2505.21828
New paper by @johnchen6.bsky.social and @guydav.bsky.social, arxiv.org/abs/2505.21828
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
May 29, 2025 at 4:51 PM
Do LLMs show systematic generalization of safety facts to novel scenarios?
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Introducing our work SAGE-Eval, a benchmark consisting of 100+ safety facts and 10k+ scenarios to test this!
- Claude-3.7-Sonnet passes only 57% of facts evaluated
- o1 and o3-mini passed <45%! 🧵
Reposted by John (Yueh-Han) Chen

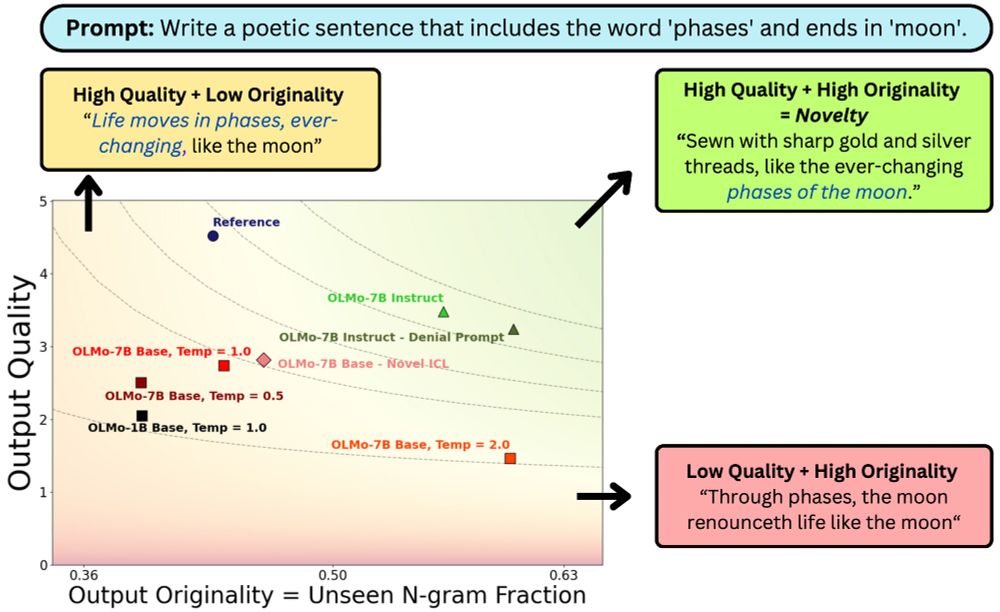
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
April 29, 2025 at 4:35 PM
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Reposted by John (Yueh-Han) Chen

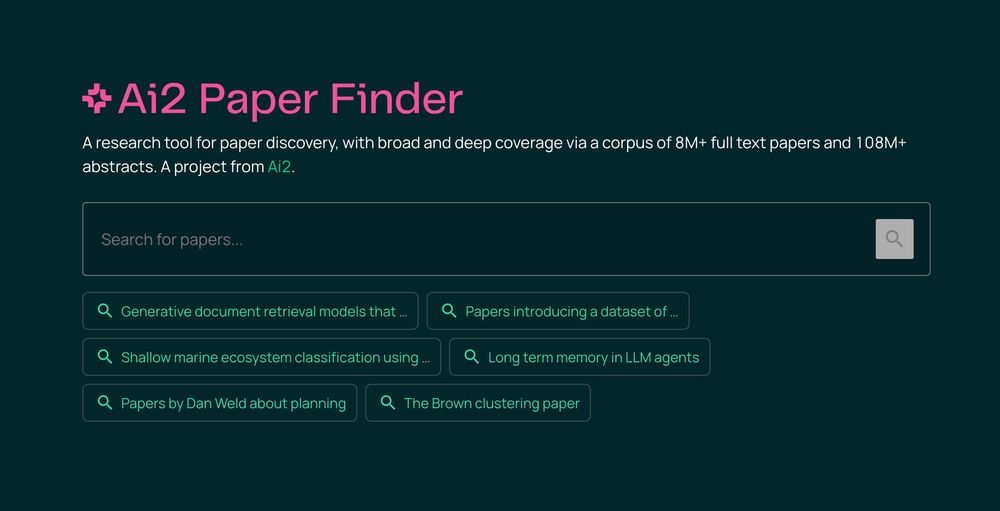
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
March 26, 2025 at 7:07 PM
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍